最近大家都在讨论【战狼2】,大都给了很高的评价。媒体也称这部电影为‘最接近好来屋大片的国产电影’。今天做了个简单的评价,结果显示战狼2的负面评价远超过正面评价。
所需R包
library(rvest)library(stringr)library(tidyverse)library(wordcloud2)library(jiebaR)
数据抓取
一共抓取了1000条豆瓣评论.
url0='https://movie.douban.com/subject/26363254/comments?'
page='status=P'
name=name_href=score=time=com_score=commen=NULL
ite=1
while(ite<=50){
url=paste0(url0,page)
web <- read_html(url)
page=web%>%html_nodes('.next')%>%html_attr('href')
tt1=web%>%html_nodes('span.comment-info>a')
name=c(name,tt1%>%html_text())
name_href=c(name_href,tt1%>%html_attr('href'))
score=c(score,web%>%html_nodes('div.comment-item > div:nth-child(2) >
h3:nth-child(1) > span:nth-child(2) > span:nth-child(3)')%>%
html_attr('title'))
time=c(time,web%>%html_nodes('div.comment-item > div:nth-child(2) >
h3:nth-child(1) > span:nth-child(2) > span:nth-child(4)')%>%
html_attr('title'))
com_score=c(com_score,web%>%html_nodes('.comment-vote>span')%>%html_text())
commen=c(commen,web%>%html_nodes('.comment>p')%>%html_text())
ite=ite+1}
datt=data.frame(name,score,time,com_score,commen,name_href,stringsAsFactors = F)
names(datt)=c('用户','评价','时间','评论得分','评论','超链接')
write.csv(datt,'datt.csv')
DT::datatable(datt)
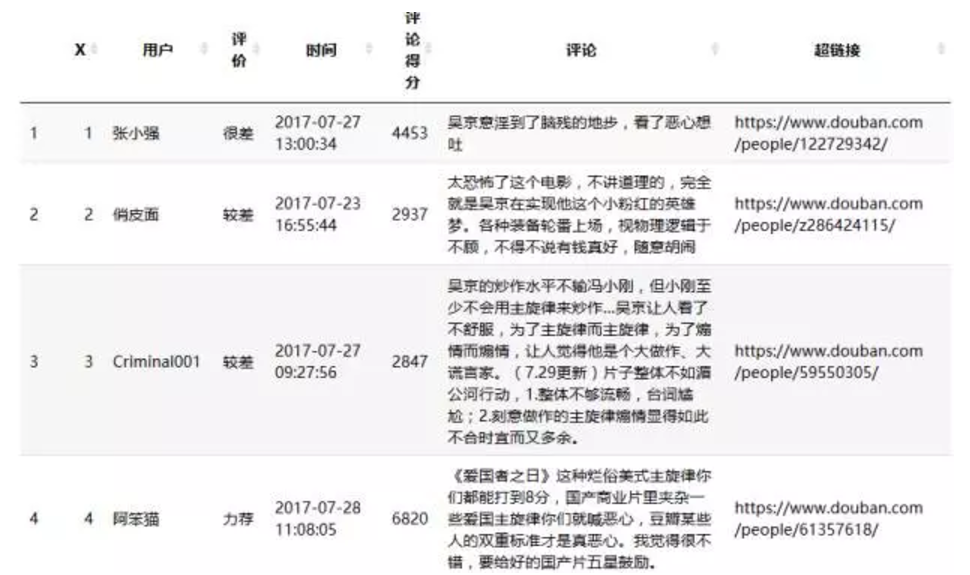
简单数据分析
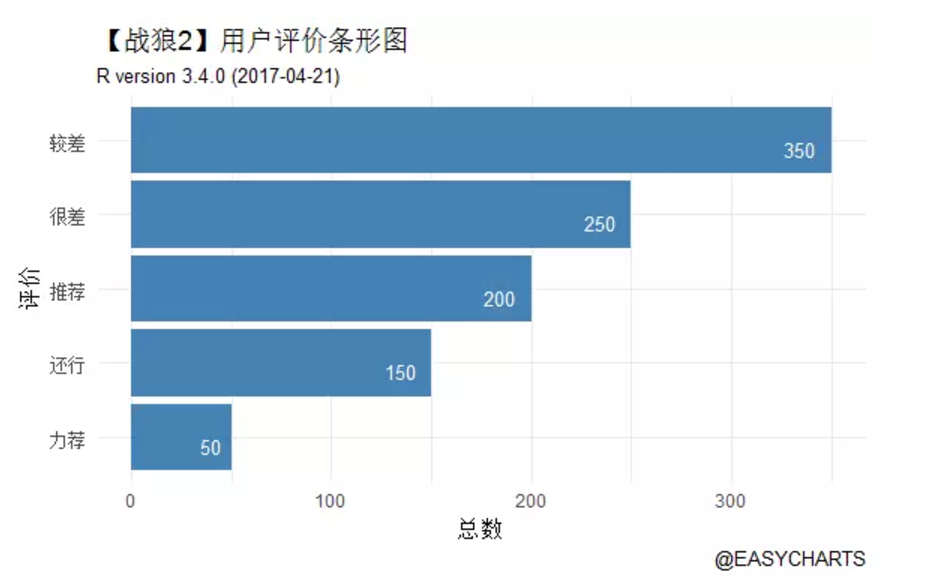
战狼二远没有你想的好
library(ggplot2)
datt1=as.data.frame(table(datt$评价))
ggplot(datt1,aes(reorder(Var1, Freq),Freq))+
geom_bar(stat="identity", fill="steelblue")+
geom_text(aes(label= Freq), vjust=1, hjust=1.5, color="white", size=3.5)+
labs(x='评价',y='总数')+
coord_flip()+
labs(title='【战狼2】用户评价条形图', subtitle=R.version.string,
caption='@EASYCHARTS')+theme_minimal()
差评者都说了什么?
datt2 = datt[datt$评价=='很差',]
comment1=datt2$评论%>%str_trim()
txt1=wolf[comment1]
datx1=as.data.frame(table(txt1),stringsAsFactors = F)[-1:-7,]
datx1[str_length(datx1$txt)>1,]
txda0=arrange(datx1,desc(Freq))
txda10=txda0[str_length(txda0$txt)>1,]
wordcloud2(datx1,color="random-light",backgroundColor = 'black')

总体评价
#stop_words.txt是把jiebaRD底层的stop_words.utf-8篡改wolf<-worker('mix',
stop_word="D:/Program Files/R/R-3.3.2/library/jiebaRD/dict/stop_words.txt")
comment=datt$评论%>%str_trim()
comment[1]
txt=wolf[comment]
datx=as.data.frame(table(txt),stringsAsFactors = F)[-1:-7,]
datx[str_length(datx$txt)>1,]
txda=arrange(datx,desc(Freq))
txda1=txda[str_length(txda$txt)>1,]
wordcloud2(txda1,color="random-light",backgroundColor = 'black')

注意:先运行总体评价的代码,在运行差评的部分.

