最近的金刚狼3着实让大家过足了瘾,虽然很悲情、英雄迟暮,光鲜不再,可是惋惜之余,大家对这步狼叔的封山之作还是充满敬意和关切的,豆瓣评分8.5,影评里将近4万多条短评,这里截取其中内容内容质量比较好的,以文字云的形式呈现,看下大家对于金刚狼都有着怎么的认知标签。
本文数据获取过程所用到的所有相关包:
library(XML)
library(Rwordseg)
library(wordcloud2)
library(RCurl)
library(stringr)
library(plyr)
library(dplyr)
url<-"https://movie.douban.com/subject/25765735/reviews?rating=&start=0"
baseurl<-"https://movie.douban.com/subject/25765735/reviews"
建立影评网址抓取函数
#豆瓣影评的网址遍历过程
urln<-paste0(baseurl,"?rating=&start=",20*(seq(0:73)-1))
fun<-function(urln){
rd <- getURL(urln,.encoding="UTF-8") #获取网页
rdhtml <- htmlParse(rd,encoding="UTF-8") #解析网页
root <- xmlRoot(rdhtml) #获取根节点
page<-getNodeSet(root,"//div[@class='review-short']/div[@class='short-content']/a")
#目标节点获取
pagevalue<-unique(laply(page,xmlGetAttr,name='href'))
#获取目标节点内的属性值(这里是评论网址)
}
#使用向量化函数进行循环处理
pagefull<-sapply(urln,fun)
#转换列表为向量
pagefullnew<-unlist(pagefull,use.names =F)
建立评论区评论文本获取函数
func<-function(page){
rd <- getURL(page,.encoding="UTF-8") #获取网页
rdhtml<-htmlParse(rd,encoding="UTF-8") # 解析网页
root<-xmlRoot(rdhtml) #获取根节点
ly<-getNodeSet(root,"//div[@class='main-bd']/div[@id='link-report']/div[@property='v:description']/p")
#获取目标节点
value<- laply(ly,xmlValue,trim=T)
#获取目标节点内的属性值(这里是评论文本)
}
#使用向量化函数进行循环处理
valuefull<-sapply(pagefullnew,func)
#转换列表为向量
valuefullnew<-unlist(valuefull,use.names =F)
文本分词处理过程
myrevieww<-valuefullnew
thewords <- segmentCN(myrevieww,nature=T)%>%unlist()
thewords <- gsub("[a-z]|\\.", "", thewords)
thewords<-thewords[nchar(thewords)>1]
建立关于影评的停止词
invalid.words <- c("电影", "演员", "导演", "我们", "他们", "一个", "没有",
"所以", "可以", "影片", "但是", "因为", "什么", "自己",
"这个", "故事", "最后", "这样", "觉得", "为了", "一部",
"这部", "片子", "其实", "当然", "时候", "看到", "已经",
"这种", "知道", "这些", "一样", "如果", "观众", "人物",
"开始", "那么", "那个", "可能", "情节", "结局", "结尾",
"风格", "节奏", "剧情", "有点", "终于", "之后", "怎么",
"一种", "出现", "作品", "地方", "本片", "一些", "一定",
"之前", "还是", "虽然", "这么", "角色", "这么", "不过",
"类型", "以为", "显得", "还是", "算是", "东西", "有些")
theflags <- thewords %in% invalid.words
thewords<-thewords[!theflags]
reviewdata<-table(thewords)%>%as.data.frame(stringsAsFactors = FALSE)%>% arrange(desc(Freq))
reviewdata$thewords[1]<-"金刚狼"
使用文字云包处理
wordcloud2(reviewdata[1:1000,],color = "random-light",minSize=.5,size=1,backgroundColor = "dark",minRotation = -pi/6, maxRotation = -pi/6,fontFamily ="微软雅黑")


导出词频结果
write.table(reviewdata,file="D:\\R\\File\\reviewdata.csv", sep =",", row.names =FALSE)
为了更加完美的利用文字云呈现广大影迷们对连狼叔的封山之作评价标签,这里我使用著名的在线文字云平台——tagul(https://tagul.com/cloud/1)来制作两幅文字云。
因为平台不支持中文,所以要先将汉语转化为英文,考虑到之前使用R语言调用有道词典结果不够完美,这里使用excel自带的在线翻译函数在excel中进行翻译,然后导入在线平台制作。
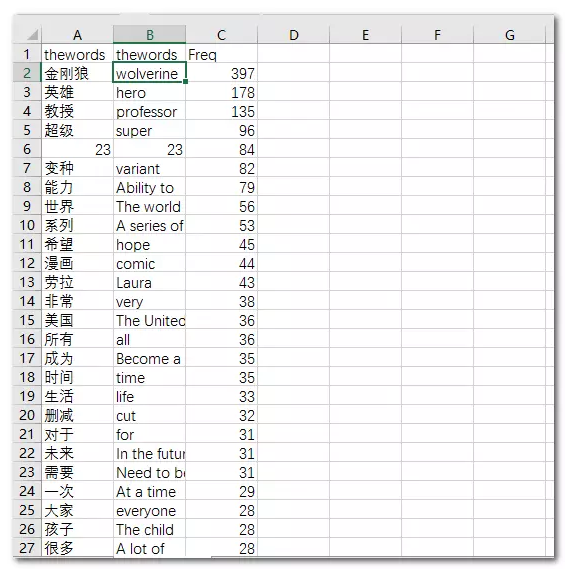
最终的词云效果:



因为不太懂关于影评的停止词设置,还是留下了很多副词,导致最终的效果有些不是很完美,但是作为一次尝试,以后会慢慢改善的!
欢迎关注魔方学院QQ群

