在最初接触数据分析时,常常把数据文件一股脑儿导入,接着开始尝试各种模型,目的就是为了快速得到分析预测结果。但这样仓促操作的后果并不像想象中高效,很多次在模型结果差的离谱时,回过头才发现原来数据中的很多“不良”记录也被用到的分析过程中。有时回过头再仔细推敲一遍时,很多特征之间的关系是显而易见的,然而我却在运用模型时没有重点关注。
我开始思考,难道没有一组“套路”可以操作?让探索数据的过程更有章法。
在走了很多弯路之后,我学习到了“探索性数据分析”(EDA)这样一个概念。第一次接触在Coursera网站的这门ExploratoryData Analysis课程里,这是一整套“数据分析课程”的其中一门,主要介绍了如何运用R语言对数据进行探索性的发现,将数据用简单的图示表示以便于更好的发现数据的潜在特征。完成课程之初,并不以为这是数据分析过程中一个关键的步骤,在做项目时只是简单的跑跑summary语句大概看看分布,之后还是我行我素。
直到最近在Kaggle上看了越来越多大神们的kernels,才猛然意识到EDA并不是一个可有可无的过程,而是进行建模分析之前的相当关键的步骤,它是帮助你熟悉数据并且探索数据的过程。在EDA的过程中,你能探索到越多的数据特性,你在建模的过程中就越高效。
在此决定把EDA过程总结并规范化,以便于自己和大家在未来进行探索性数据分析时有步骤可依。为了方便说明,会用到Kaggle上最近较火的Zillow房产数据分析比赛。
读取数据
通常情况下,用于导入数据文件的方法有三类。分别是base R 中的read.csv(),readr library read_csv() 和data.table library 中的fread()。
在进行一些小型数据分析时,base R和readr library 足够应付。但在处理的数据量越来越大时,最高效也最常用的是fread()。在读入数据时,fread()会自动检测各类数据,如sep,colClass和nrows等等。并且现在大量的数据都是机器产生的结构化数据,fread()能充分应付这类大型数据,为之后的数据分析开好头。
library(data.table)
train <-fread("train_2016_v2.csv")
properties_2016 <-fread("properties_2016.csv")
基本数据统计信息
导入数据之后,就需要对数据进行全方位的查看。在接触很多项目之后,我发现无论之前看过再多对数据的描述文档,在真实“摸到”数据之前,其实脑海中对于数据的认知都是非常表面的。那么数据到手之后,怎么开始上手?
第一步,看数据。用head()语句首先查看数据结构。head()会打印出前6行数据。假如想要一次性看到更多数据,head()提供了可以设置行列的参数。
head(train)
parcelid logerror transactiondate
1: 11016594 0.0276 2016-01-01
2: 14366692 -0.1684 2016-01-01
3: 12098116 -0.0040 2016-01-01
4: 12643413 0.0218 2016-01-02
5: 14432541 -0.0050 2016-01-02
6: 11509835 -0.2705 2016-01-02
head(train,10)
也许有不走寻常路的同学,想要从最后几行数据来认识结构,R提供了tail(),操作和head()一样。
第二步,查看统计数据。统计数据是指数据的最大最小值等。对于数值类型的数据,统计数据可以让我们快速了解到这个数据的分布和均值如何,对数据范围做到心里有数。对于字符类型的数据,可能需要先转换类型,再得到统计结果。
summary(train)
parcelid logerror transactiondate
Min. : 10711738 Min. :-4.60500 Length:90275
1st Qu.: 11559500 1st Qu.:-0.02530 Class :character
Median : 12547337 Median : 0.00600 Mode :character
Mean : 12984656 Mean : 0.01146
3rd Qu.: 14227552 3rd Qu.: 0.03920
Max. :162960842 Max. : 4.73700
train$transactiondate <- as.Date(train$transactiondate)
summary(train)
parcelid logerror transactiondate
Min. : 10711738 Min. :-4.60500 Min. :2016-01-01
1st Qu.: 11559500 1st Qu.:-0.02530 1st Qu.:2016-04-05
Median : 12547337 Median : 0.00600 Median :2016-06-14
Mean : 12984656 Mean : 0.01146 Mean :2016-06-11
3rd Qu.: 14227552 3rd Qu.: 0.03920 3rd Qu.:2016-08-19
Max. :162960842 Max. : 4.73700 Max. :2016-12-30
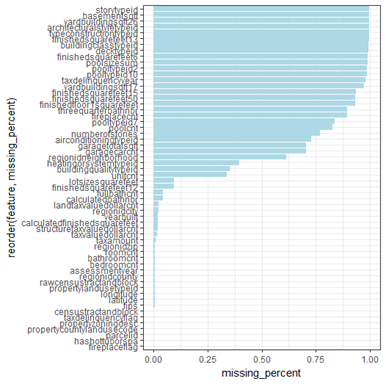
第三步,查看缺失数据(missing values)。数据集中通常会有一些缺失或不良数据,造成这些问题的理由很多样。一些是源于人为的数据录入问题,例如用户的性别未填写。或者有些是在从其他系统导出数据时产生的缺失。面对这些问题,我们在使用数据时应该尽量避免选择缺失量过大的属性。所以在分析之前,我们需要掌握数据的缺失情况。
通常采取的操作是统计出每一项属性中缺失数据所占比例,然后以图像简单直接的呈现出来。我最常用的就是柱状图,把排序后的缺失率结果展示出来。因此在之后进行分析决策时,那些缺失率相对较高的特征应该被排除在外。
library(dplyr)
missinga_values <- properties_2016 %>%summarise_each(funs(sum(is.na(.))/n()))
missing_values <- gather(missinga_values,key ="feature",value = "missing_percent")
missing_values %>% ggplot(aes(x =reorder(feature,missing_percent),y = missing_percent)) + geom_bar(stat ="identity",fill ="light blue") + theme_bw() + coord_flip()
单一变量分析
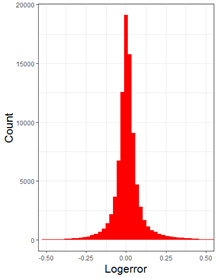
对于有些重要的变量,我们希望了解它的分布组成。比如一组数据的时间分布或者一组数值的区间分布,这些都属于这个单一变量的变化。
在Zillow这个项目中,交易产生的时间和每笔交易的误差是我们想要重点研究的。对于这类分析,我们可以画出数据的直方图或者密度图。
train %>%
ggplot(aes(x = logerror)) + geom_histogram(bins = 400, fill = "red")+
+ theme_bw() + theme(axis.title = element_text(size = 16),axis.text = element_text(14))+
+ ylab("Count") + xlab("Logerror") + coord_cartesian(x=c(-0.5,0.5))
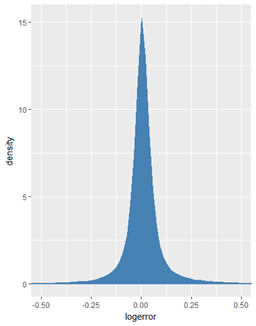
train %>%
ggplot(aes(x = logerror)) + geom_density(fill = "steelblue",color = "steelblue") + coord_cartesian(x = c(-0.5,0.5))
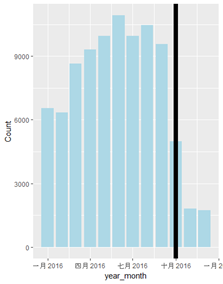
对于交易时间分布也是类似,将数据简单组合归类之后,画出分布直方图。
train %>%
+ mutate(year_month = make_date(year = year(transactiondate), month= month(transactiondate))) %>%
+ group_by(year_month) %>%
+ count() %>%
+ ggplot(aes(x=year_month,y= n)) + geom_bar(stat= "identity", fill = "lightblue") + geom_vline(aes(xintercept = as.numeric(as.Date("2016-10-01"))),size = 3) + labs(y = "Count")
多变量分析
多变量分析是统计学里一个重要的方法,也是单变量分析的延伸。几乎我们想在所面临的所以数据分析项目都是多变量的,也就是说问题涉及的因素是多种多样的。这篇文章主要介绍的是探索性分析,所以就只介绍几个高效好用的多变量分析方法。
关联性分析
当数据只是一列列数字时,我们很难发现各个变量之间的联系,这时候最好的就是对整体做一组关联性分析,然后将结果用图像呈现出来。用corrplotlibrary中的cor()可以帮我们求出变量之间的相关矩阵,再做得关系矩阵图。(关于关系矩阵图的属性还有很多介绍,需要的朋友可以查阅corrplotpackage)
library(corrplot)
cnt_vars <- c('bathroomcnt', 'bedroomcnt', 'calculatedbathnbr', 'finishedfloor1squarefeet', 'calculatedfinishedsquarefeet', 'fireplacecnt','fullbathcnt', 'garagecarcnt', 'garagetotalsqft', 'roomcnt', 'threequarterbathnbr', 'unitcnt', 'numberofstories', 'logerror')
cor_matrix <- cor(dtrain[,..cnt_vars],use = 'pairwise.complete.obs')
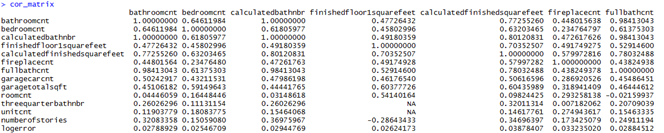
corrplot(cor_matrix,insig = "blank")
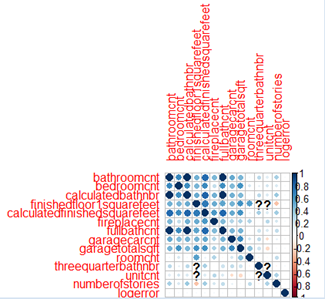
通过corrplot,我们可以清晰的发现哪些参数之间是正相关或负相关,在之后的建模分析中更有针对性。
组合分析
根据前几步的初步学习,我们对数据集有了一个基本的了解,接下来可以进一步探查变量之间的关系。通常会有几组目标组合,想要探查或者验证我们的猜测是否准确。此时我们就需要提出问题,然后通过做图将他们展示出来,这样可以让我们更容易发现数据规律以及一些我们容易遗漏的情况。
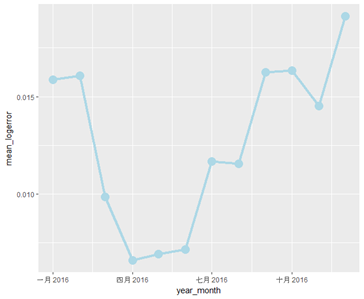
- Logerror & Transaction Time
train %>%
mutate(year_month = make_date(year = year(transactiondate), month= month(transactiondate))) %>%
group_by(year_month) %>%
summarize(mean_logerror = mean(logerror)) %>% ggplot(aes(x= year_month, y = mean_logerror)) + geom_line(size =1.5, color = "lightblue") + geom_point(size = 5, color = "lightblue")
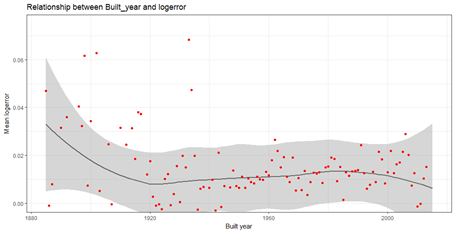
cor_temp %>%
group_by(yearbuilt) %>%
summarize(mean_logerror = mean(logerror),n()) %>%
ggplot(aes(x = yearbuilt,y= mean_logerror))+ geom_smooth(color = "grey40") + geom_point(color = "red") + ggtitle("Relationship between Built_year and logerror") +labs(x="Built year",y="Mean logerror") + coord_cartesian(ylim = c(0,0.075)) + theme_bw()
以上就是我在不断摔跤试错过程中总结的一些套路,大家学会了么?欢迎大家相互交流,让我们在数据分析的道路上共同进步!





