最近突然想看电影了,跑去电影天堂却不知道该看哪一步,很纠结呀,想来想去还是去知乎上搜搜高评分的电影。发现新大陆呀,还是网友的力量大,挖掘出了高评分的电影,并作一一罗列,足足400多部啊。具体内容可点击豆瓣电影TOP250不够看?这下有看不完的电影了~
于是,我想着该把这些数据抓取下来并保存到本地,然后再分析分析这些电影都有哪些特征。关于数据的抓取和分析,全程使用R语言,后文有获取数据和代码的方法。接下来我们以问题为导向,一一剖析这些电影的特征。先来看看抓取下来的数据结构长啥样吧:
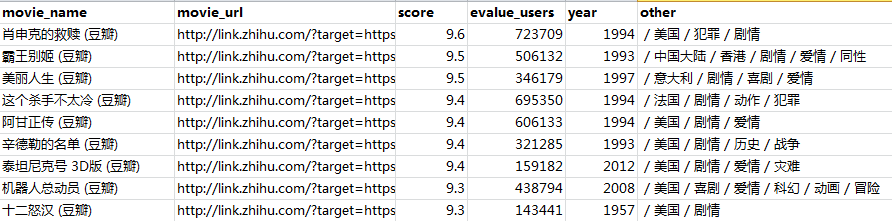
一、数据处理
由上图可知,抓取下来的数据最后一列包含了电影的拍摄国家和电影类型,这里需要将国家和电影类型分别存储到两个变量中,用于后面的分析探索使用。我们注意到,最后一列的用斜杠/分割开来,那我们就可以用这个斜杠作为字符串的分隔符:
# 把数据集中的other变量进行切割
library(stringr)
cut_other <- str_split(raw_data$other, '/')
head(cut_other)

发现截断的每一个词前后都用空格,需要将这些空格过滤掉:
# 剔除字符串中的收尾空格
cut_other <- sapply(cut_other, str_trim)
head(cut_other)

完成数据切割和清洗后,接下来就要从这些词中抽取出国家或地区的名称存储到一个变量,抽取出电影类型存储到另一个变量。
首先,需要前往搜狗官网,下载所有国家和地区名称的字典,再利用“深蓝词库转换”工具,将scel格式的字典转换成txt:
# 读取下载下来的国家和地区数据
countrys <- readLines(file.choose())
# 提取出所有关于电影所属国家的信息
movie_country <- sapply(cut_other, function(x,y) x[x %in% y], countrys)
head(movie_country)

# 提取出所有关于电影所属类型的信息
movie_type <- sapply(cut_other, function(x,y) x[!x %in% y], countrys)
head(movie_type )

OK,到目前为止,我们需要分析的数据都已经整理好了,接下来开始探索这些数据。
二、参评人数最多的Top10的电影
# 配置画图的数据
library(ggplot2)
p <- ggplot(data = arrange(raw_data, desc(evalue_users))[1:10,],
mapping = aes(x = reorder(movie_name,-evalue_users),
y = evalue_users)) +
# 限制y周的显示范围
coord_cartesian(ylim = c(500000, 750000)) +
# 格式化y轴标签的数值
scale_y_continuous(breaks = seq(500000, 750000, 100000),
labels = paste0(round(seq(500000, 750000, 100000)/10000, 2), 'W')) +
# 绘制条形图
geom_bar(stat = 'identity', fill = 'steelblue') +
# 添加轴标签和标题
labs(x = NULL, y = '评价人数', title = '评价人数最多的top10电影') +
# 设置x轴标签以60度倾斜
theme(axis.text.x = element_text(angle = 60, vjust = 0.5))
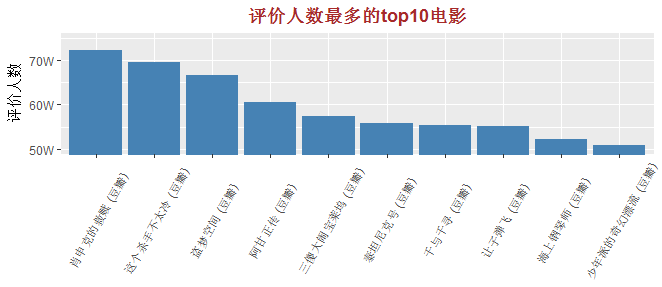
结果发现,肖申克的救赎、这个杀手不太冷、盗梦空间是上图top10中的top3,哈哈,这些电影你都看过吗?
三、一部电影需要多少国家合拍
# 统计每一部电影合拍的国家数
movie_contain_countrys <- sapply(movie_country, length)
table(movie_contain_countrys)
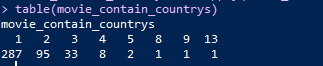
由于电影的制作包含5个国家及以上的分别只有1部电影,故将5个国家及以上的当做1组。
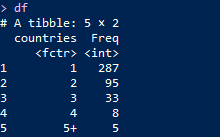
# 转化为数据框
df <- as.data.frame(table(movie_contain_countrys))
# 数据框变量的重命名
names(df)[1] <- 'countries'
# 数据类型转换
df$countries <- as.numeric(as.character(df$countries))
df$countries <- ifelse(df$countries<=4, df$countries, '5+')
# 聚合操作
library(dplyr)
groupby_countrys <- group_by(df, countries)
df <- summarise(groupby_countrys, Freq = sum(Freq))
# 数据类型转换,便于后面可视化
df$countries <- factor(df$countries)
df
对于上面统计的数据,我们运用环形图进行数据的展现:
# 定义数据,用于画图
df$ymax <- cumsum(df$Freq)
df$ymin <- c(0, cumsum(df$Freq)[-length(df$ymax)])
# 生成图例标签
labels <- paste0(df$countries,'(',round(df$Freq/sum(df$Freq)*100,2),'%',')')
# 绘图
p <- ggplot(data = df, mapping = aes(xmin = 3, xmax = 4, ymin = ymin,
ymax = ymax, fill = countries)) +
# 矩形几何图
geom_rect(size = 5) +
# 极坐标变换
coord_polar(theta = 'y') +
# 环形图
xlim(1,4) +
# 添加标题
labs(x = NULL, y =NULL, title = '一部电影需要多少国家合作') +
# 设置图例
scale_fill_discrete(breaks = df$countries, labels = labels) +
theme(legend.position = 'right',
plot.title = element_text(hjust = 0.5, colour = 'brown', face = 'bold'),
axis.text = element_blank(),
axis.ticks = element_blank(),
panel.grid = element_blank(),
panel.background = element_blank()
)
p
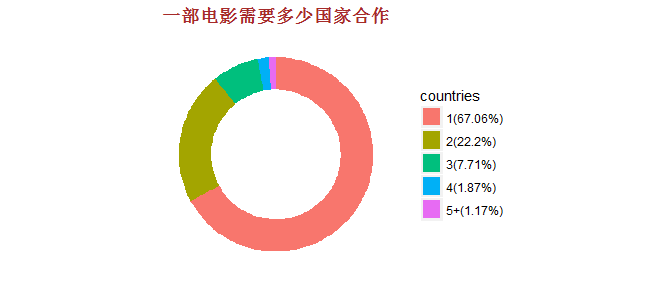
结果显示,这428部电影,有三分之一都是至少两个国家和地区合拍而成。
四、电影产量top10都是哪些国家
# 罗列出所有电影的拍摄国家
top_countris <- unlist(movie_country)
# 频数统计,并构造数据框
df <- as.data.frame(table(top_countris))
# 降序排序
df <- arrange(df, desc(Freq))
df
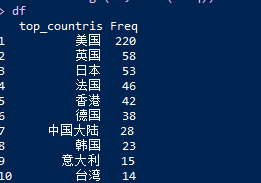
上图,统计发现,香港,中国大陆和台湾入围前十,分别是第5,第7和第10名。前三的归美国,英国和日本。美国绝对是量产的国家,远远超过第二名的英国。接下来,我们运用文字云来展现上面的统计数据:
library(wordcloud2)
wordcloud2(df, backgroundColor = 'black', rotateRatio = 2)

五、电影主要都是什么类型
# 罗列出所有电影的类型
top_type <- unlist(movie_type)
# 构造数据框
df <- as.data.frame(table(top_type))
# 降序排序
df <- arrange(df, desc(Freq))
df
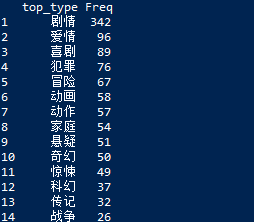
由于几乎所有的电影都贴上剧情这个标签,我们暂不考虑这个类型,看看其他的类型top15分布,并使用条形图来展示这些数据。
df <- df[-1,]
df$top_type <- as.character(df$top_type)
# 提取出前15的类型
df$top_type <- ifelse(df$top_type %in% df$top_type[1:15], df$top_type, '其他')
# 数据聚合
groupby_top_type <- group_by(df, top_type)
df <- summarise(groupby_top_type, Freq = sum(Freq))
# 排序
df <- arrange(df, desc(Freq))
# 构造数值标签
labels <- paste(round(df$Freq/sum(df$Freq)*100,2),'%')
p <- ggplot(data = df, mapping = aes(x = reorder(df$top_type, Freq), y = Freq)) +
# 绘制条形图
geom_bar(stat = 'identity', fill = 'steelblue') +
# 添加文字标签
geom_text(aes(label = labels), size = 3, colour = 'black',
position = position_stack(vjust = 0.5), angle = 30) +
# 添加轴标签
labs(x = '电影类型', y = '电影数量', title = 'top15的电影类型') +
# 重组x轴的标签
scale_x_discrete(limits = c(df$top_type[df$top_type!='其他'],'其他')) +
# 主题设置
theme(plot.title = element_text(hjust = 0.5, colour = 'brown', face = 'bold'),
panel.background = element_blank())
p
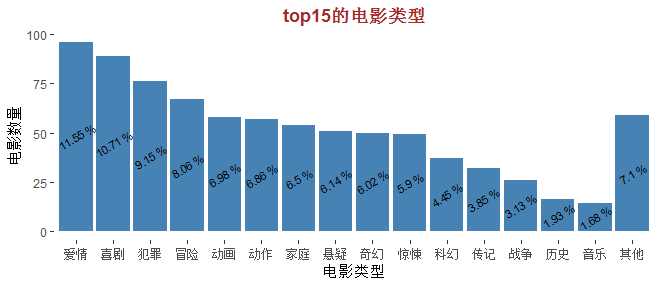
结果显示,前三名的电影类型分别为爱情、喜剧和犯罪。
六、哪些年代的电影好评度比较高
# 根据年份的倒数第二位,判读所属年代
raw_data$yearS <- paste0(str_sub(raw_data$year,3,3),'0','S')
# 对年代聚合
groupbyYS <- group_by(raw_data, yearS)
yearS_movies <- summarise(groupbyYS, counts = n())
# 绘图
p <- ggplot(data = yearS_movies,
mapping = aes(x = reorder(yearS, -counts),
y = counts)) +
# 绘制条形图
geom_bar(stat = 'identity', fill = 'steelblue') +
# 添加轴标签和标题
labs(x = '年代', y = '电影数量', title = '各年代的好评电影数量') +
# 主题设置
theme(plot.title = element_text(hjust = 0.5, colour = 'brown', face = 'bold'),
panel.background = element_blank())
p
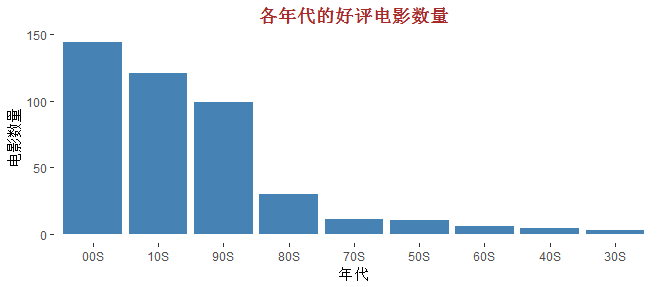
这个结果似乎并没有什么意义,90年代及以后的高分电影一共占了85%,毕竟随着时代的发展,电影的特效、质量都得到了快速的提升。
七、评分top5的电影类型
前面的分析都没有涉及到电影的评分,电影有各种各样的类型,甚至一个电影可以打上好几个类型的标签,那接下来我们就对这些类型标签进行评分统计。
# 罗列出所有电影的类型标签
types <- unique(unlist(movie_type))
# 定义空的数据框对象
df = data.frame()
# 通过循环,抓取出不同标签所对应的电影评分
for (type in types){
res = sapply(movie_type, function(x) x == type)
index = which(sapply(res, any) == 1)
df = rbind(df,data.frame(type,score = raw_data[index, 'score']))
}
# 按电影所属类型,进行summary操作
type_score <- aggregate(df$score, by = list(df$type), summary)
# 数据集进行横向拼接为数据框
type_score <- cbind(Group = type_score$Group.1, as.data.frame(type_score$x))
# 按平均得分排序
type_score <- arrange(type_score, desc(Mean))
type_score
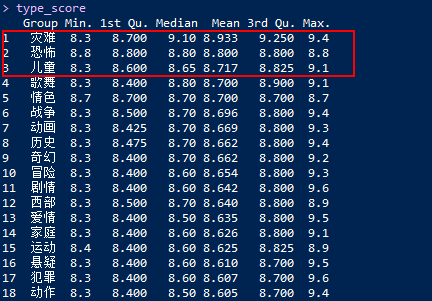
单从电影类型的平均得分来看,灾难片、恐怖片和儿童片位居前三,尽管分别只有3部,2部和12部。
八、评论人数和评分之间的关系
抓取的数据表中含有每部电影的评论人数和评分,这两个变量都是数值型变量,我们通过散点图的方式来看看这些电影的评论人数和评分之间是否存在某些隐形的关系呢?
p <- ggplot(data = raw_data, mapping = aes(x = evalue_users, y = score)) +
# 绘制散点图
geom_point(colour = 'steelblue') +
# 添加一元线性回归拟合线
geom_smooth(method = 'lm', colour = 'red') +
# 添加轴标签和标题
labs(x = '评论人数', y = '评分', title = '评论人数与评分的关系') +
# 设置x轴的标签格式
scale_x_continuous(breaks = seq(30000, 750000, 100000),
labels = paste0(round(seq(30000, 750000, 100000)/10000, 2), 'W')) +
scale_y_continuous(breaks = seq(8, 9.6, 0.2)) +
# 主题设置
theme(plot.title = element_text(hjust = 0.5, colour = 'brown', face = 'bold'))
p
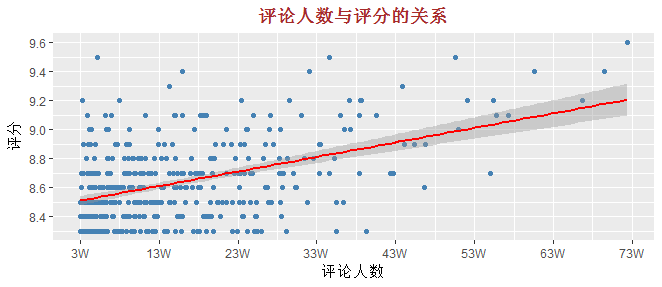
很有意思,从这400多个散点绘制的图形中可以发现,评论人数和评分之间还是存在正相关的关系,即评论的人越多,评分倾向于更高。由于绝大多数电影的评论人数都小于33万,故如果需要建模的话,建议将数据分为两组,分别对两组数据建模。
OK,今天就分享到这吧,感兴趣的朋友,可以照着文章操作一遍,相信对你的R语言有一定的提升或帮助作用。
您可以通过关注小号并回复“电影”获取文章中的数据和脚本。
每天进步一点点2015
学习与分享,取长补短,关注小号!


