前言
这篇文章的下篇终于写出来了,上篇(数据采集)在两个月前写出来的:
传送门:https://ask.hellobi.com/blog/wangdawei/7570
为何下篇现在才写出来呢?
有两个原因:
1.两个月前对python数据分析掌握的很差,那时候天天学爬虫,pandas,numpy了解的也不多
2.人嘛,总是有惰性,喜欢一拖再拖
注:python可视化才刚入门,最后的可视化以后还可以完善一篇
环境
Python3.X
编辑器:Jupyter notebook
导入链家网爬取的二手房数据
import numpy as np
import pandas as pd
df = pd.read_excel('house_lianjia.xlsx')
df
。。。。。。
一共2871条数据,其实上次爬了2w条数据,然后找不到了,那就拿测试爬的2871条作分析了
数据初窥
查看数据信息(包括每个字段数据类型),数据条数,文件大小等
df.info()

查看数据前五行:
df.head()

查看数据后五行:
df.tail()

我们可以看到‘梯户比例’一栏好像都是暂无数据
我们可以专门将这一栏数据拿出来查看:
df['梯户比例']

。。。。。。

显示的都是暂无数据
为了确定是否所有都是暂无数据,我们可以使用如下办法:
df[df['梯户比例'] == '暂无数据']#把暂无数据的数据提取出来

。。。。。。

取出了2871行,说明所有行的这栏都是暂无数据
删除无效的数据
那么,这一栏对我们数据分析没有意义,可以删去:
del df['梯户比例']#移除一栏
我们再次看一下最新的数据情况:
df
获得数据描述性统计
df.describe()

我们可以看一下数据的简单统计信息,从图中可以看出每个栏位数据的个数,不重复数据个数,出现最多的数据及其出现的次数
注意到最后一栏,进门朝向数据只有13个,这说明了数据缺失很严重,不考虑缺失值补齐,直接删除该栏数据:
del df['进门朝向'] #只有13个数据
再看一下数据情况:
df
可以通过这种方式快速查看各栏位名称:
#查看列(字段)名称
df.columns

专门查看各字段类型:
#查看字段类型
df.dtypes

发现缺失值
如果想看每个单元的缺失值,可以使用:
df.isnull()#哪些包含了缺失值
Flase表示没有缺失
当然,这样看起来非常难受,而且不直观
查看各字段是否有缺失值:
df.isnull().any()#是否有缺失值

这样,我们就能看到除了'房屋朝向'字段有缺失值,其他字段都没有缺失值。
我们想看看‘房屋朝向’字段有多少缺失值:
df.isnull().sum()#每个里有多少个缺失值

显示有13个缺失值
如果你对这个个数不敏感,我们可以看看缺失值的比例:
df.isnull().sum() / df.count()#缺失值比例

‘房屋朝向’的缺失值只有0.45%左右
数据探索
我们想看看数据分布是怎样的
例如看一下二手房所在区的情况:
df['所在区'].value_counts()
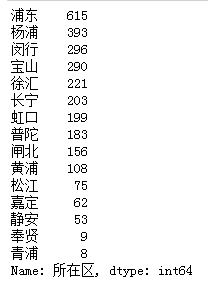
浦东的二手房在售的最多,可能是因为浦东新区地大
看一下二手房房屋朝向的情况:
df['房屋朝向'].value_counts()

南和南北朝向的有很多,阳光充足
看一下房屋户型的情况:
df['房屋户型'].value_counts()

可以看出在售的二手房多为2室1厅1卫
看一下房屋类型的情况:
df['房屋类型'].value_counts()

说明公寓类型最多
筛选房屋信息
如果我们想看一下我们感兴趣的房屋,例如我想找3室1厅1卫的房屋,并且只看部分:
df[df['房屋户型'] == '3室1厅1卫'].head()
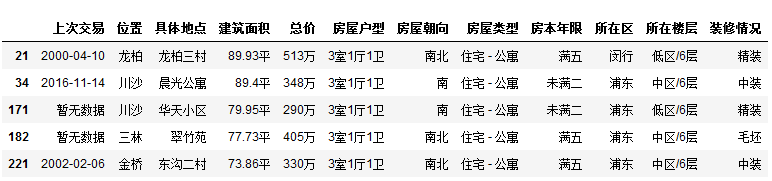
当然你也可以使用and(&)和or(|)挑选你感兴趣的房屋信息,这里不再赘述。
舍弃有缺失值的行
之前看到有包含13个含缺失值的行,我们将其舍弃:
df = df.dropna()#舍弃含有任意缺失值的行,显示的是剩下的
df.head()
小插曲:在jupyter notebook中,如果想要看一个方法的具体使用方法,我们可以:
?df.dropna()
然后查看弹出的信息了解使用说明
此时,我们再看看是否还有缺失值:
df.isnull().any()#是否有缺失值
 显示已经没有缺失值了
显示已经没有缺失值了
资料重整
我们发现:

房屋类型中,所有类型前面都显示‘住宅-’,我们将其去除
df['房屋类型'] = df['房屋类型'].map(lambda e: e.split(' - ')[1].split())
注:将该字段信息以‘-’为分隔符分成前后两部分(两部分都不包括-),然后索引取后面部分(如果是前面部分则是[0])
然后在pandas里用map加载匿名函数lambda,返回的e即为‘-’后面的部分信息
df
处理完之后:
正则表达式提取信息
由于建筑面积的信息不是数值型,而且建筑面积里含有‘平’这个字,不能直接用于计算
所以我们提取出其中的数字:
df['建筑面积'].str.extract('(\d+\.\d+)平', expand =False)
\d+:匹配0-9中一个及其以上数字
\.:转义,匹配点
(\d+\.\d+)用括号括起来,提取括号中的信息
提取的结果如下:

我们将提取的结果反馈回dataframe表格:
df['建筑面积'] = df['建筑面积'].str.extract('(\d+\.\d+)平', expand =False)
df.head(5)
 、
、
看来已经完成这一步骤
同理,使用正则提取‘总价’栏位中的数字:
df['总价'].str.extract('(\d+)万', expand =False)

df['总价'] = df['总价'].str.extract('(\d+)万', expand =False)
df.head()
转换数据类型
提取出来的数字是字符类型,我们需要将其转化为数字类型,例如float浮点数,int整型等
df[['总价']] = df[['总价']].astype(int)
df[['建筑面积']] = df[['建筑面积']].astype(float)
df.info()
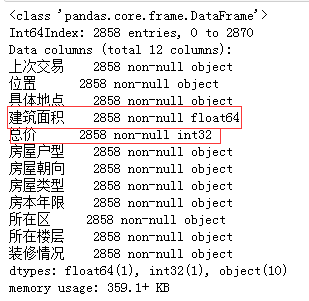
转换完成后,可以看出‘建筑面积’和‘总价’已经是数值型的了
属性构造
我们构造一个属性叫做‘均价’
df['均价'] = df['总价']/df['建筑面积']
df.head()
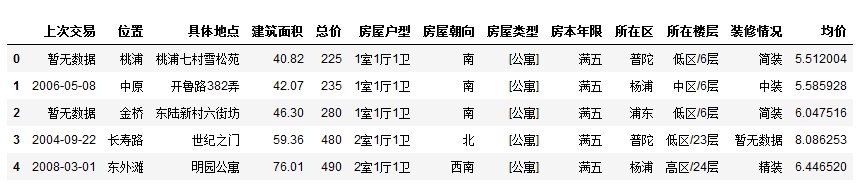
建立数据透视表
df2 = df.pivot_table(index = '位置', columns='装修情况', values='均价', fill_value='0')#默认均价,比较出各个地区价格
df2.head()#位置作为索引,装修情况作为栏位,均价作为值
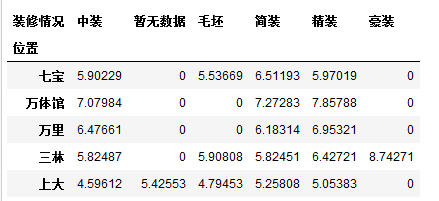
df2 = df.pivot_table(index = '所在区', columns='装修情况', values='均价', fill_value='0')#默认均价,比较出各个地区价格
df2#所在区作为索引,装修情况作为栏位,均价作为值
这样的数据透视表,可以让我们一目了然的看出各区不同装修情况在售的不同二手房价格(均价单位是万元/每平方米,取的是平均值)
我们注意到,上面的数据透视表中有很多0,当然,这里的0不是说房价为0,而是fill_value='0',即缺失值用0填充了
无意义的值转为缺失值
我们看到,装修情况栏位中有着'暂无数据'的字样情况:
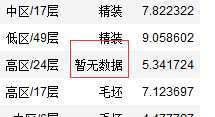
我们将其变为缺失值:
df['装修情况'] = df['装修情况'].replace('暂无数据',np.NaN)
然后删去这些含缺失值的行:
df.dropna()
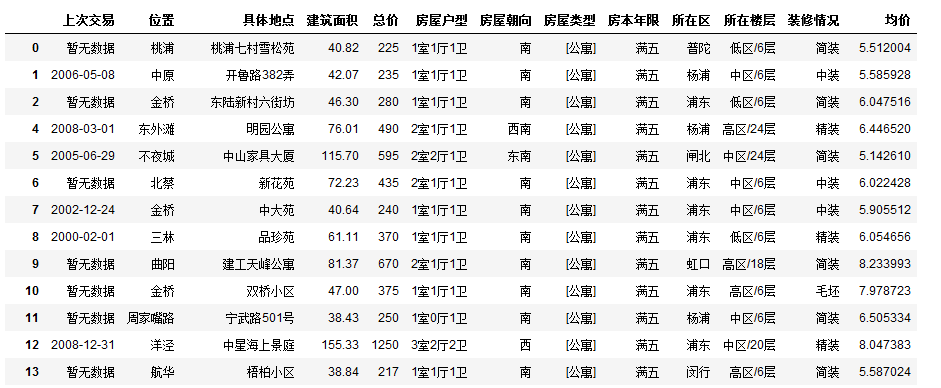

我们注意到行数确实减少了
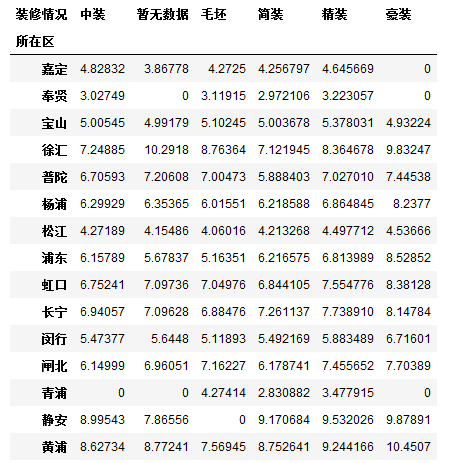
我们再次制作数据透视表:
df2 = df.pivot_table(index = '所在区', columns='装修情况', values='均价', fill_value=np.NaN)#默认均价,比较出各个地区价格
df2#位置作为索引,装修情况作为栏位,均价作为值
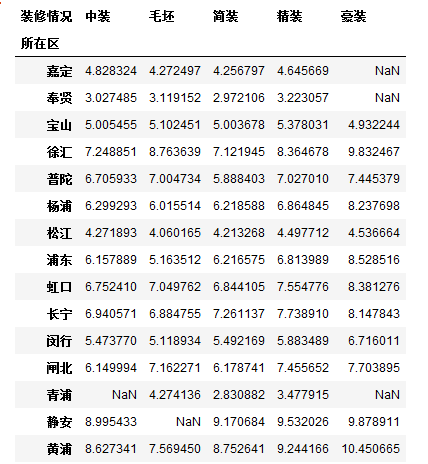
NaN表示没有信息:意思是没有此类的房屋信息
数据可视化
做数据分析,数据展现的方法之一就是图
#-*- coding: utf-8 -*-
%matplotlib inline
以上是为了让绘制的图显示出来
from matplotlib.font_manager import FontProperties
import matplotlib.pyplot as plt
font = FontProperties(fname = 'C:\Windows\Fonts\simsun.ttc')
以上是为了解决绘图里中文字体显示问题,可以参照如下链接设置显示中文字体:
https://www.joinquant.com/post/441
绘制散点图
df.plot(x='建筑面积', y='总价', kind='scatter')
plt.xlabel('建筑面积', fontproperties=font)
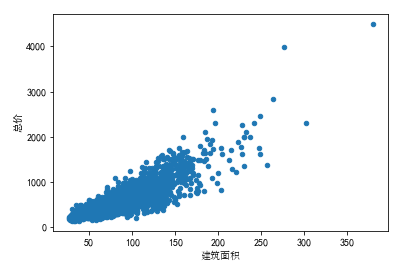
可以看出,随着建筑面积的增大,二手房的总价也在上升,并没有出现特别异常的值
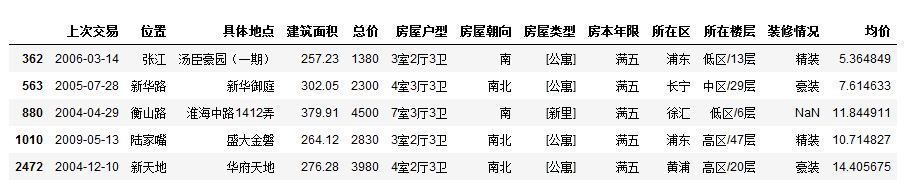
但是有离群值出现,例如靠近右上角的,我们可以看一下这些房屋的信息:
df[df['建筑面积']>250]
绘制柱状图
注:以下过程比较波折,在于我目前对可视化学习较少
为了统计不同装修情况,我进行了一大堆步骤:
df1 = pd.get_dummies(df['装修情况'])#建立虚拟变量,是精装则在精装位置显示1,以此类推
df1.head()
dec = df1.sum()
type(dec)
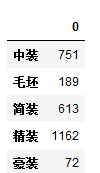
我想将Series转为df:
dec

df2 = pd.DataFrame(dec)#series转为df
df2
发现索引不是我想要的,于是我删除了索引:
df2 = df2.reset_index(drop = True)
df2
这绕了一圈差不多删除完了,尴尬
再手工加回去:
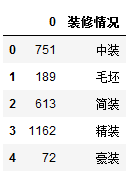
df2['装修情况'] = ['中装','毛坯','简装','精装','豪装']
df2
这栏位名不太对,改一下:
df2.columns = ['个数', '装修情况']
df2

走到这部不容易,我一定好好学数据可视化。。。
df2.plot(x='装修情况', y='个数', kind='bar')
plt.xlabel('装修情况', fontproperties=font)
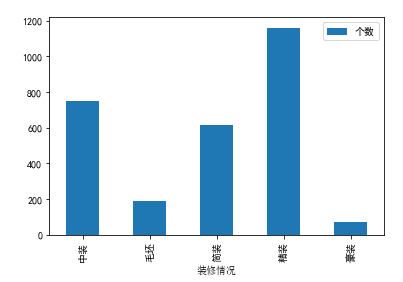
绘图,通过图形更加一目了然看出不同装修情况的个数比较
最后再看一下描述性统计:
df.describe()
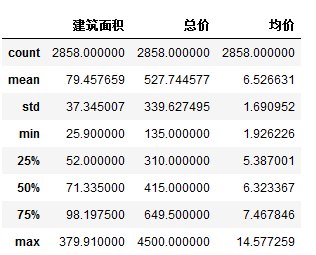
因为数据缺失值处理了,数字转为数值型了,所以此时的统计更有意义
包括数量、均指、标准差、最小值、上四分位数等等。
写在文末
这是我写的比较久的一篇文章,就像在做一个简单的项目一样,从上文的爬取数据到这次的数据分析可视化,终于完整的做了一次数据分析。
致谢
在这篇文章的数据分析过程中,感谢秦路老师给我在技术上的答疑解惑!


