背景介绍
前面学习了涉及自变量和因变量间呈曲线关系的情形,当时采用的是曲线直线化的策略(回顾:SPSS分析技术:曲线直线化;一氧化碳中毒如何避免?),但是这种方法只适用于曲线关系比较简单的情况,即可以找到合适的曲线方程将原来的自变量变换将直线关系,然后再利用线性回归分析,由此可见,曲线直线化的方法有自身缺陷,有些数据情况是曲线直线化方法无法解决的。
本文介绍的非线性回归就是针对以上更为复杂的问题而提出的一个通用的模型框架,它采用迭代方法对用户设置的各种复杂曲线模型进行拟合,同时将残差的定义从最小二乘法向外大大扩展(例如最小一乘法等方法)为用户提供了极为强大的分析能力。
曲线直线化和非线性回归
因变量和自变量是非线性关系时,可以通过曲线直线化和非线性回归对它们之间的关系进行拟合。许多较为简单的非线性模型可以通过变量变换转化为线性模型,它们又被称为可变换为线性的模型。可变换为线性的模型有许多优点,诸如易于求得某些参数的初始值等。虽然曲线回归简单快捷、易于理解,但是曲线回归(曲线直线化)的数据变换会导致随机误差项分布的变换,这将影响到最小二乘法所得解的含义以及模型的适用条件。例如假定变换前模型的误差项服从正态分布,对于变换后的数据来说,其相应的误差项很可能就不再服从正态分布。回归分析的假设不仅只有正态性,也包括方差齐性、独立性等要求,因此变换后的线性模型采用最小二乘法求得的最佳参数估计值并不一定是原模型的最佳估计。显然,在较为复杂的非线性模型中,曲线直线化有其固有的问题,因此在精度要求较高,或者模型较复杂的非线性回归问题中,采用曲线直线化来估计非线性方程并不是一个好的策略。
非线性回归的基本原理可以从其回归模型讲起。非线性回归模型一般可以表示为如下形式:

非线性回归参数估计的基本思想非常类似于线性模型,分析者必须先给出一个能够表示估计误差的曲线函数,然后使得该函数取值最小化,并求得此时的参数估计值。以常用的最小二乘法为例,它也是设法找到使得各数据点离模型回归线纵向距离的平方和达到最小值,但此处的模型回归线就是相应的曲线,而不是线性回归中的直线,或者曲线拟合中变换后的直线。
由于曲线函数并非直线,使得模型无法直接计算出最小二乘估计的参数值,因此非线性回归模型一般采用高斯-牛顿法进行曲线函数参数的估计。这种估计方法是对曲线函数作泰勒级数展开,以达到线性近似的目的,并反复迭代求解。首先为所有未知参数指定一个初始值,然后将原方程按泰勒级数展开,并只取一阶各项作为线性函数的逼近,其余各项均归入误差,然后采用最小二乘法对该模型中的参数进行估计,用参数估计值替代初始值,得到一个新的曲线函数;再将新得到的曲线函数展开,进行线性化,从而又可以求出一批参数估计值;如此反复,直至参数估计值收敛为止。这种参数估计方法的计算非常复杂,必须借助于计算机完成,在许多时候,初始值的设定对模型能否顺利求解是有显著影响的。非线性回归模型在SPSS中可以采用未约束和定义参数约束两个过程来拟和,前者用于一般的非线性模型,后者可用于带约束条件的非线性模型的拟合,适用范围更广,算法也不相同。
案例分析
为了对比(曲线回归)曲线直线化和非线性回归这两种回归方式的不同。下面依然采用文章:SPSS分析技术:曲线直线化;一氧化碳中毒如何避免?的案例,在这篇文章中,通过对数据进行变换,原来通风时间和毒物浓度间的曲线关系被转换成了直线,从而可以通过直接进行线性回归得到分析结果。
分析步骤
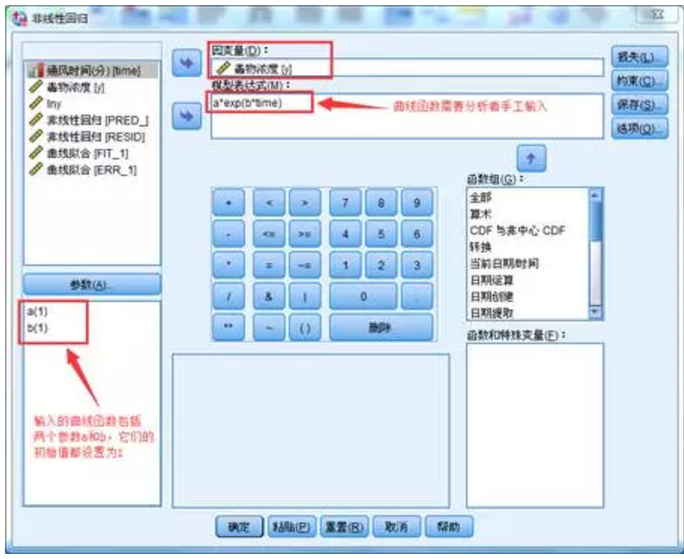
选择菜单【分析】-【回归】-【非线性】,在跳出的对话框中进行如下设置。将一氧化碳浓度(毒物浓度)选入因变量;因为我们观察因变量与自变量之间的关系服从指数函数,所以在模型表达式中输入指数函数公式y=a*exp(b*time)。因为指数函数有两个待确定参数,在右下角的输入两个参数的拟合初始值1。
结果解释
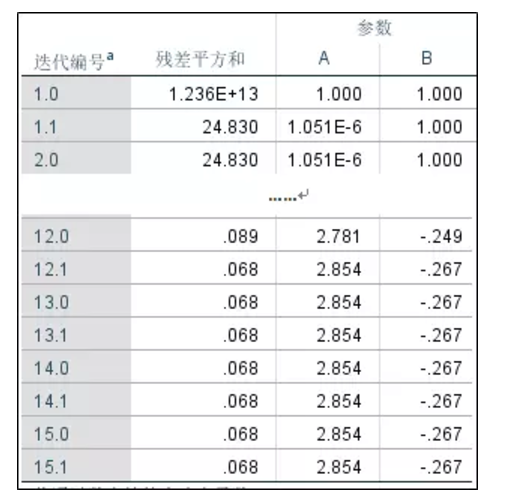
1、迭代过程。由于迭代过程记录太长,这里省略中间部分。观察残差平方和的变化,可见随着迭代地进行,残差平方和变得越来越小,也就是说模型无法解释的变异部分越来越少。但这一过程不是无限进行下去的,当进行了15步迭代,共拟合了32个模型后,残差平方和以及各参数的估计值均稳定下来,模型达到收敛标准。
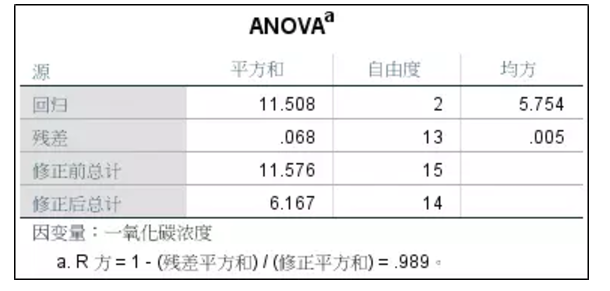
2、模型方差分析的结果。相应的原假设为所拟合的模型对因变量的预测无贡献。由于这里进行的是非线性回归,方差分析的F值和p值只有参考意义,因此结果中并不给出,可以手工计算。显然,最终的p值远小于0. 05,拒绝原假设,可以认为模型对于因变量的预测是有作用的。方框中的最下方计算出了模型的决定系数为0.989,第6章曲线直线化的p值等于0. 961,可见非线性回归模型的拟合效果从决定系数来看是更好,可惜曲线直线化的决定系数与非线性回归的决定系数是不可比的(后面会介绍原因)。
3、回归系数估计值;
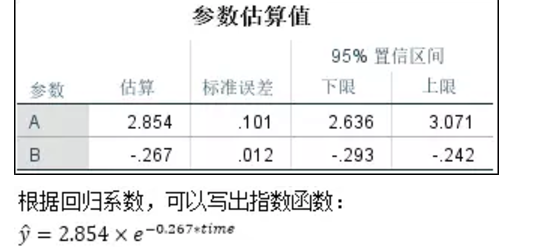
4、两种方法比较。
上面用非线性回归的方法得到了模型表达式的估计值。显然,该表达式和曲线直线化所得到的结果并不相同,a和b两个系数的值相差不小。究竟哪一个方程更好呢?虽然从决定系数上看似乎是非线性回归的方程更优,但是曲线拟合中计算出的决定系数实际上是曲线直线化后直线方程的决定系数,并不一定代表变换前的变异解释程度,即两个模型的决定系数是不可比的。
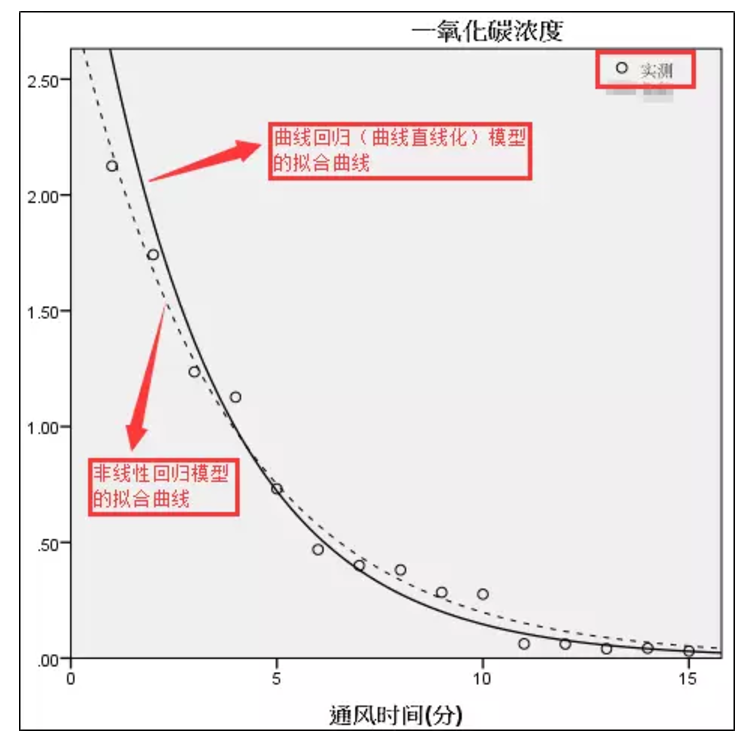
为了能直观地对两个模型进行比较,这里分别对本案例的数据分别拟合两个模型,并利用【保存】子对话框求得各自的模型预测值与预测残差,并绘制图形如下图所示。下图是原始数据、曲线回归模型、非线性回归模型三者的比较,从中可见在通风时间大于4 分钟时,两个模型的预测效果基本接近,似乎是非线性回归模型更好一些。但是在小于4 分钟时,则曲线拟和模型的预测效果明显较差。特别是第1和第2分钟的数据,显然预测误差较大。综合比较之下,非线性回归模型的拟合效果要更好。