传统的偷漏税分析是通过人工检测来进行的,对人的依赖性太大,为了提高偷漏税的判别效率,拟决定先根据商户的纳税数据进行初步的自动判断,对于判别为偷漏税的用户再进行人工检测。
本文从以下几个步骤讲解数据分析的流程:
1、数据集
2、数据探索与清洗
3、模型构建(CART决策树模型和神经网络模型)
4、模型训练与诊断
5、模型评估(混淆矩阵和ROC曲线)
一、数据集的获取
正如上文所说,我将要判别汽车行业纳税人是否存在偷漏税情况,那么哪些因素能够判别哪些指标的数据异常表明存在偷漏税的情况呢?通过识别哪些经营特征来判断偷漏税情况呢?
数据集中提供了汽车销售行业纳税人的各个属性与是否偷漏税标识。结合汽车销售行业纳税人的各个属性,总结衡量纳税人的经营特征,建立偷漏税行为识别模型,识别偷漏税纳税人。本文提供的数据集指标类型如下:

为了尽可能全面覆盖各种偷漏税方式,建模样本要包含不同纳税类别的 所有偷漏税用户及部分正常用户。偷漏税用户的偷漏税的关键数据指标。共计124条数据,各类销售指标数据,终端输出,输出正常表示纳税情况正常,异常表示存在偷漏税情况。
二、数据探索与清洗
当获得数据集后,按照惯例,需要对数据做一个探索性分析,即了解我的数据呈现什么分布情况。由于数据集不存在缺失值情况,所以不需要做缺失值处理。为了后面模型的训练和测试评估,对样本随机选取20%的作为测试样本,剩下80%的作为训练样本。

三、模型构建、训练与诊断
这么多的影响因素,我们应该如何找到最大的影响因素?CART决策树模型可以通过一系列规则对数据进行分类。还可以为其他模型筛选变量。决策树找到的变量是对目标变量影响很大的变量。
CART决策树又称分类回归树,当数据集的因变量为连续性数值时,该树算法就是一个回归树,可以用叶节点观察的均值作为预测值;当数据集的因变量为离散型数值时,该树算法就是一个分类树,可以很好的解决分类问题。但需要注意的是,该算法是一个二叉树,即每一个非叶节点只能引伸出两个分支,所以当某个非叶节点是多水平(2个以上)的离散变量时,该变量就有可能被多次使用。


CART模型对提取具有模型显著性的偷漏税识别因子,即为变量。将变量作为输入数据对构建的BP神经网络模型进行训练,并选取20%检验样本对模型的有效性进行预测检验。

四、模型评估
得到混淆矩阵如下:
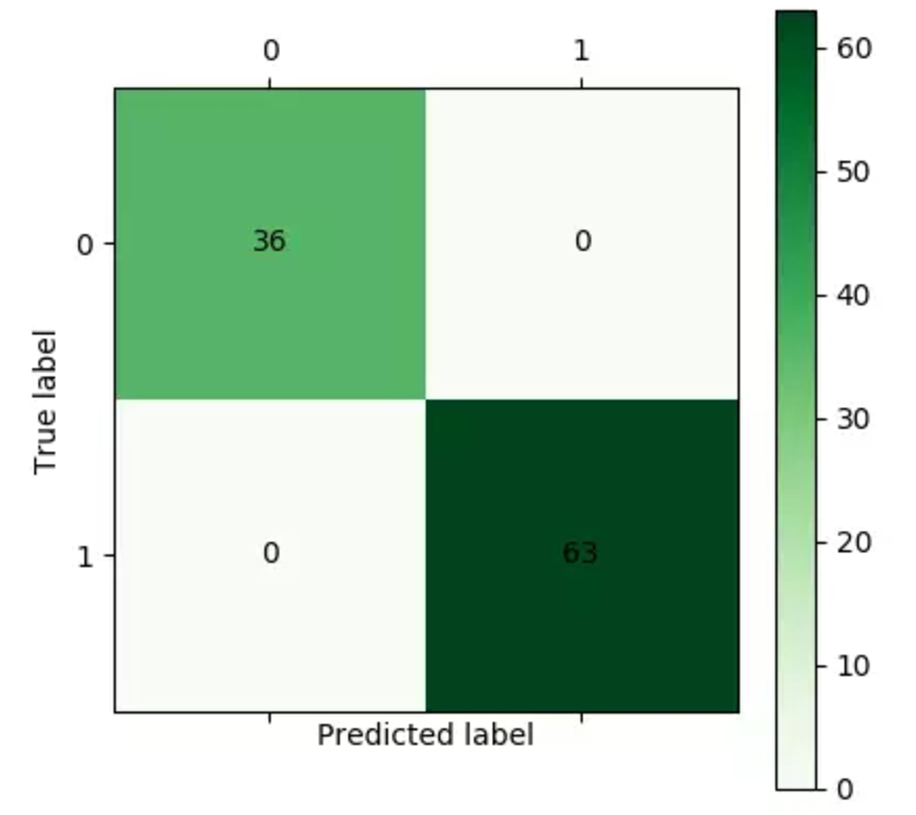
得到ROC曲线如下:
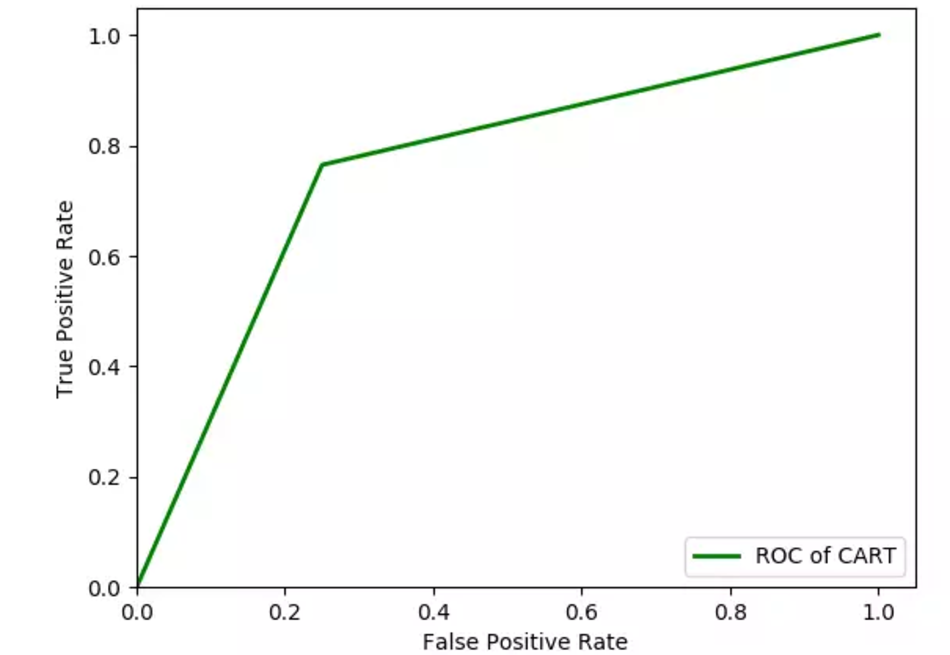
因为训练集是随机选择,每次运行,对模型的识别效果影响也是有区别的,上图是几次运行中模型识别效果较普通的一次。
关于如何评价模型的好坏,请参见:
http://www.jianshu.com/p/41f434818ffc
