

协同过滤是一种通过分析用户的历史数据来建立用户和商品之间联系的方法。协同过滤中两种比较成功的方法是隐含因子模型和近邻模型,其中SVD是隐含因子模型的代表。
隐含因子模型
什么是隐含因子模型?隐含因子模型即为将商品和用户映射到同样的隐含因子空间中,使得它们之间可以直接比较。最常用的方法即为SVD。

其中通过Frobenius范数作为衡量标准所得到的近似矩阵是最接近原矩阵的。
隐含因子模型的缺点主要体现在以下方面:
• 如果一小部分紧密关联的商品之间是强相关的,则这种模型效果较差; • 用户不易知道为什么这个商品会被推荐给TA,结果的可解释性不好;
• 实际情况中,数据通常是比较稀疏的,而 SVD 对于稀疏数据比较敏感。
近邻方法
近邻方法用来衡量商品或用户之间的相似性,通常是通过相似分数来衡量的。这种方法擅长检测出局部关系,而隐含因子模型则不能。
隐式反馈
隐含因子模型和近邻方法中都没有隐式反馈,而SVD++则将隐式反馈加入了模型,这正是SVD++产生的缘由。用户和商品之间可能存在多种隐式反馈,有一些不是那么明显,比如Netflix数据中,用户对电影的评价可以看作一种隐式反馈。
SVD++ 模型
由Google大牛 Yehuda Koren 提出
https://scholar.google.com/citations?user=wTmI_HYAAAAJ&hl=en
这种模型试图将隐含因子模型和近邻模型的优点结合起来。某个用户对某个商品的评价由以下三部分构成:

其中

第一项(标红)表示基本评分,其中包含了全局评分均值以及用户和商品分别对应的偏差。

第二项(标红)跟原始SVD类似,但是包含了隐式反馈,该反馈体现在商品评价集合 N(u) 中。

第三项和第四项是近邻项。前一项是评价对应的加权偏差,后一项体现了隐式反馈的局部影响。
如果令

则SVD++的目标函数如下:

这种优化问题可以利用梯度下降来求解。
实验结果

概率矩阵分解 PMF (Probabilistic matrix factorization)
由深度学习大牛Ruslan Salakhutdinov 提出,已加入CMU
http://www.cs.cmu.edu/~rsalakhu/index.html
这种方法类似于SVD,它也是将一个矩阵进行分解,不同点在于:概率矩阵分解对稀疏数据表现较好;概率矩阵分解的复杂度随着样本数的增加而线性增长。
概率矩阵分解将用户评价看作一种概率图模型:

具体公式表示如下:
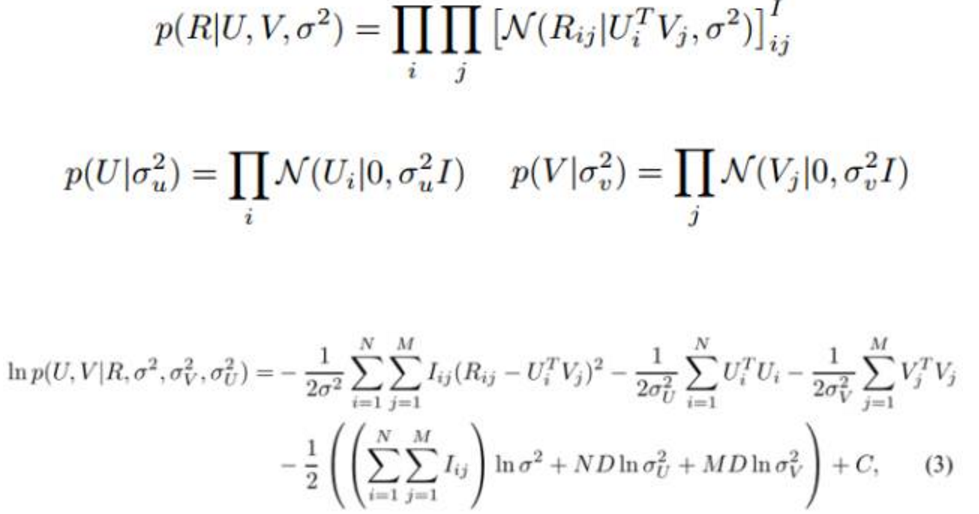
给定用户和商品的隐含因子对应的先验知识,则问题可以转化为最小化下面的误差:

将先验知识融入参数中,即可得到自适应PMF。
实验结果

约束性概率矩阵分解

具体公式如下:
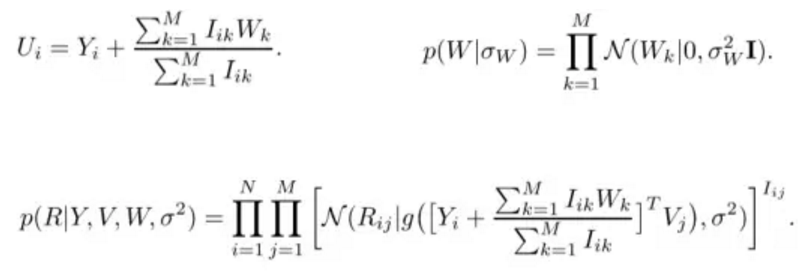
目标函数如下:
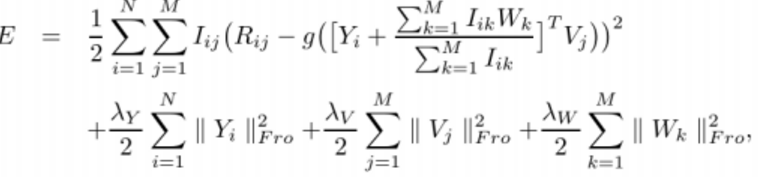
实验结果:

注:
Fronenius范数如下:

参考资料 http://dparra.sitios.ing.uc.cl/classes/recsys-2015-2/student_ppts/CRojas_SVDpp-PMF.pdf
www.cs.rochester.edu/twiki/pub/Main/HarpSeminar/Factorization_Meets_the_Neighborhood-_a_Multifaceted_Collaborative_Filtering_Model.pdf
http://alex.smola.org/teaching/berkeley2012/slides/8_Recommender.pdf
https://papers.nips.cc/paper/3208-probabilistic-matrix-factorization.pdf
http://images.slideplayer.com/25/7956898/slides/slide_21.jpg
http://cdn.slidesharecdn.com/ss_thumbnails/qcon-xavier-131118142118-phpapp01-thumbnail-4.jpg?cb=1384784551
http://www.slideshare.net/xamat/qcon-sf-2013-machine-learning-recommender-systems-netflix-scale
https://inst.eecs.berkeley.edu/~ee127a/book/login/eqs/8780903672165983049-130.png
{kind=link}
{kind=link}
