首先来介绍下一种用来学习词表示的神经网络 (Collobert et al. JMLR 2011)。这种方法的思想在于某个单词及其上下文是一个正样例,同样上下文中的一个随机词(corrupted word)就是一个负样例。比如:

另外,对比估计中的隐含负样例证据也可以用神经网络来解决

那么如何将这种方法形式化呢?可以用下式来表示这个问题:
score(cat chills on a mat) > score(cat chills Jeju a mat)
问题又来了,如何计算评分呢?可以利用神经网络来计算,每个单词对应一个n维的向量。

为了表示一个句子,可以将句子中所有单词对应的向量组合起来构成一个矩阵,即词嵌入矩阵。句子对应的矩阵可以随机初始化为如下形式:

即

矩阵中的词向量需要学习得到。这个矩阵也称为 look-up 表。概念上来讲,对一个one-hot向量e左乘look-up表就可以得到单词对应的向量,即 x = Le。
下面聊聊如何用神经网络来处理这个问题。为了得到 score(cat chills on a mat),可以将L的矩阵表示

连接起来,得到一个向量

那么如何计算评分呢?为计算评分,先简单介绍下单层的神经网络,单层的神经网络是一个线性层和非线性变换对的组合:
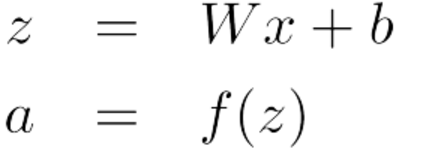
激活函数 a 可以用于后续的计算,比如上面我们所关心的评分:
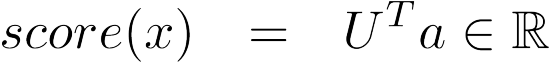
为了得到下面两个评分:
s = score(cat chills on a mat) sc = score(cat chills Jeju a mat)
可以通过最小化下面的目标函数来优化,使得真词窗的可能性更大一些,同时使得含误用词的可能性更小一些,
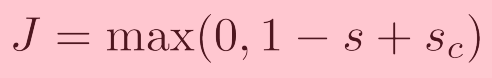
这个函数是连续的,可以利用随机梯度下降法来优化。
前面介绍了前向计算,接下来介绍如何通过反向传播来优化模型。

由于目标函数是连续的,可以通过计算 s 和 sc 关于所有相关变量(U, W, b, x)的偏导数来反向传播:

对于单个权值的偏导数计算方式如下:
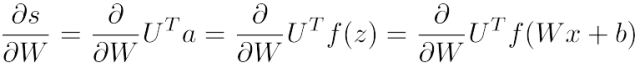
这个只跟ai相关联。比如 W23 只用来计算a2,W12只用来计算a1。
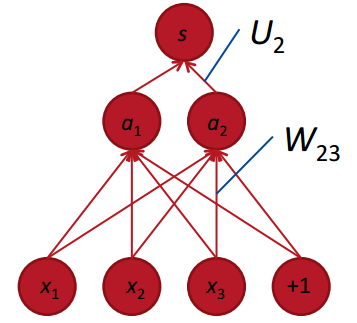
由链式法则
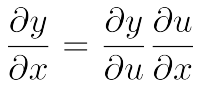
可以得到:
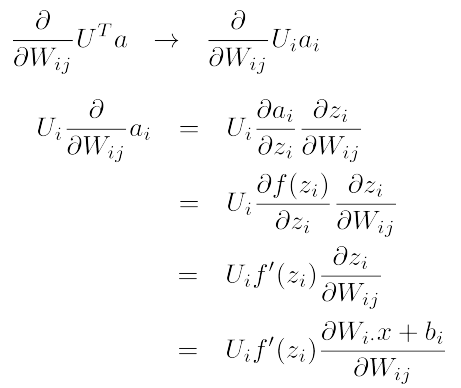

上面是针对单个权重系数的,可以借助外积得到相应的矩阵形式:
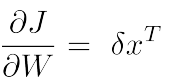
偏置对应的偏导数如下:
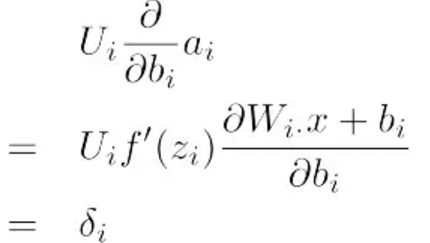
简单总结下,后向反馈即为求导数并且利用链式法则来反向传播误差。值得注意的是,高层计算的导数可以在低层计算中得以复用。
下面求解评分对于单个词向量的导数,此时,不能只考虑某一个ai,因为每个xj都跟上层所有的神经元相连接,因此,xj会影响上层中的每个单元,所以:
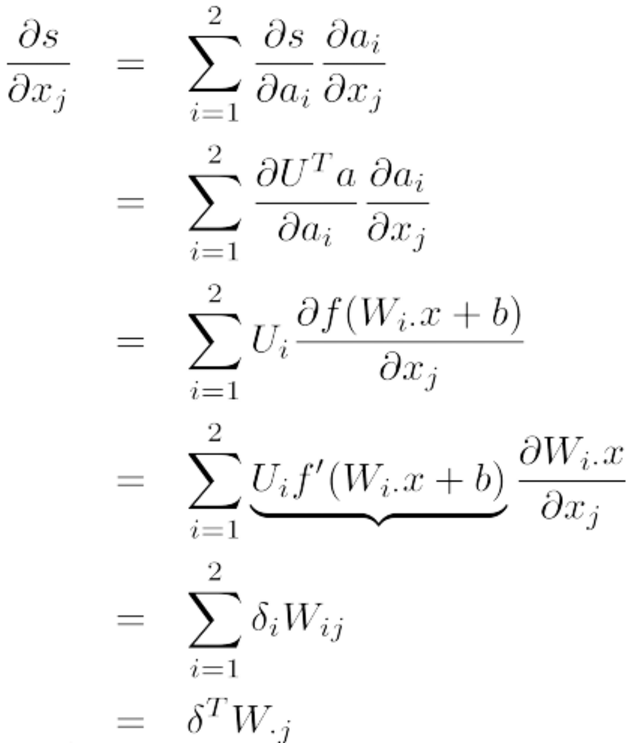
其中,

就是可以复用的部分。
最后来谈下基于深度学习学到的词向量有什么优势。这种方法可以借助于softmax或maxent,同时借助于隐含层将类别信息融入其中。

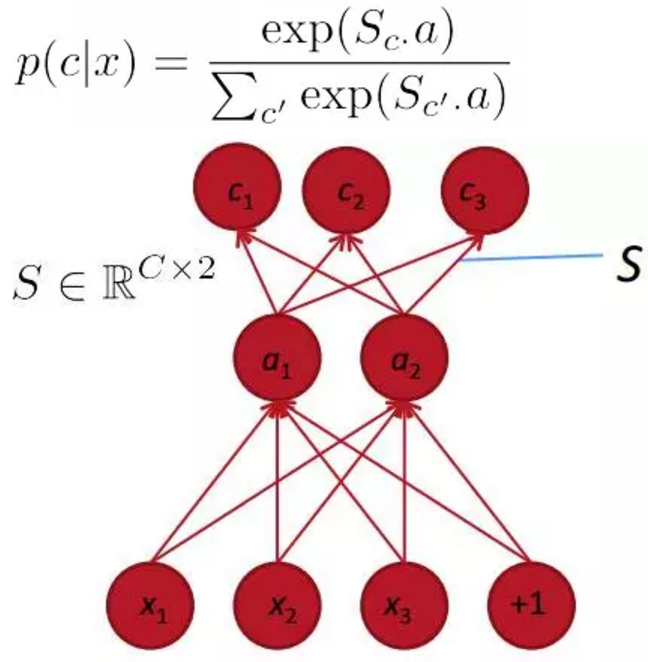
附:
简单的链式法则
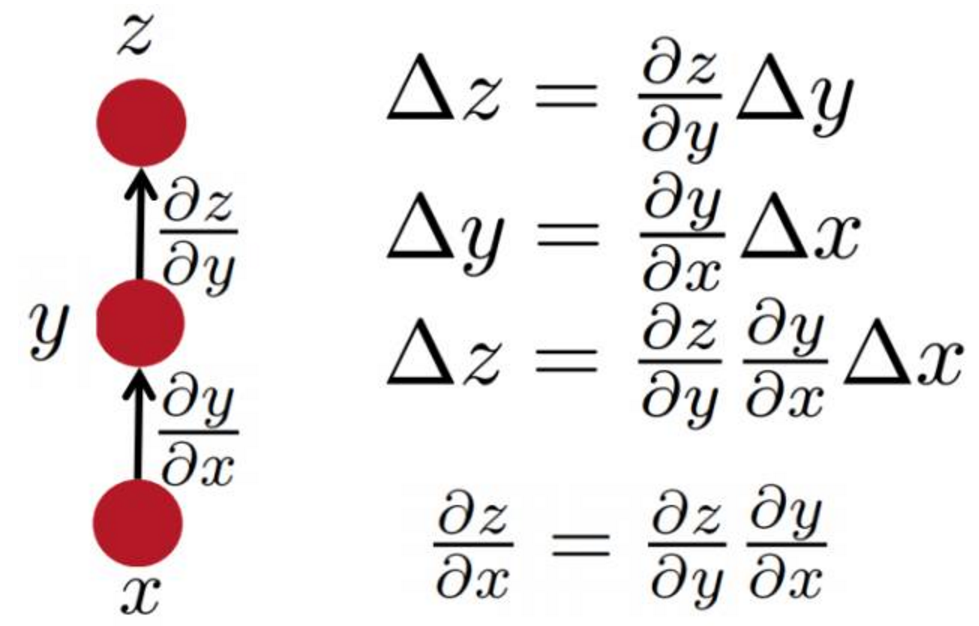
多通路链式法则
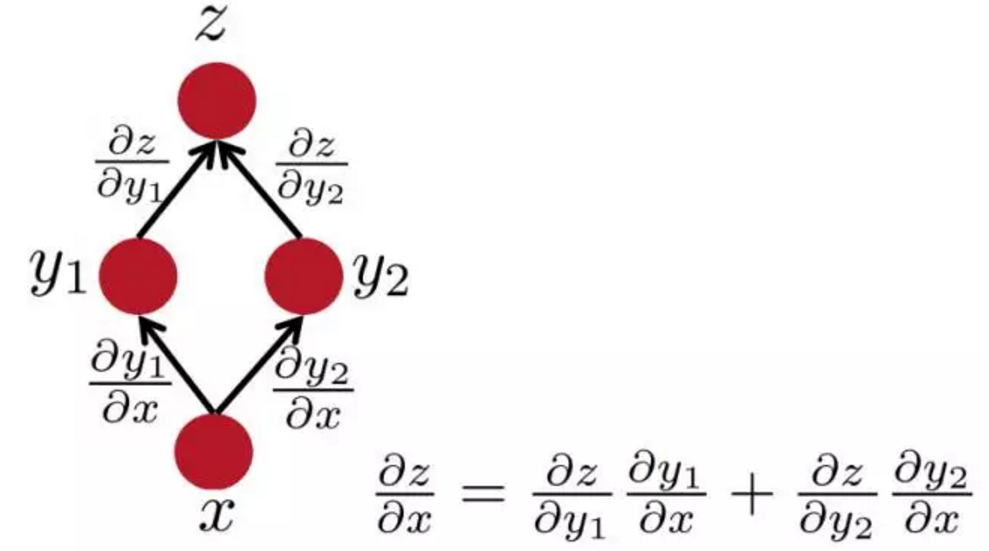
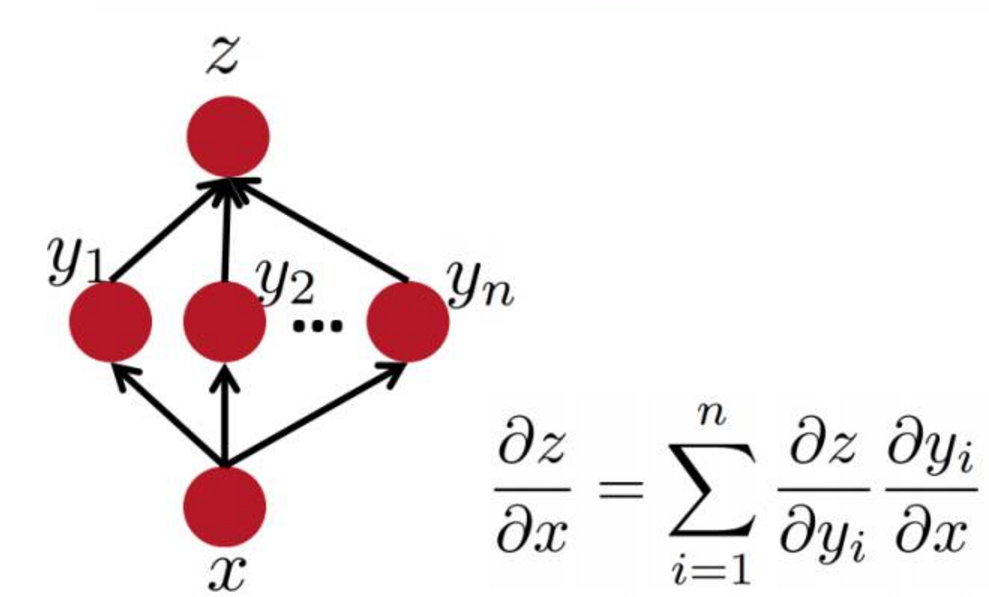
多层网络中的反向传播
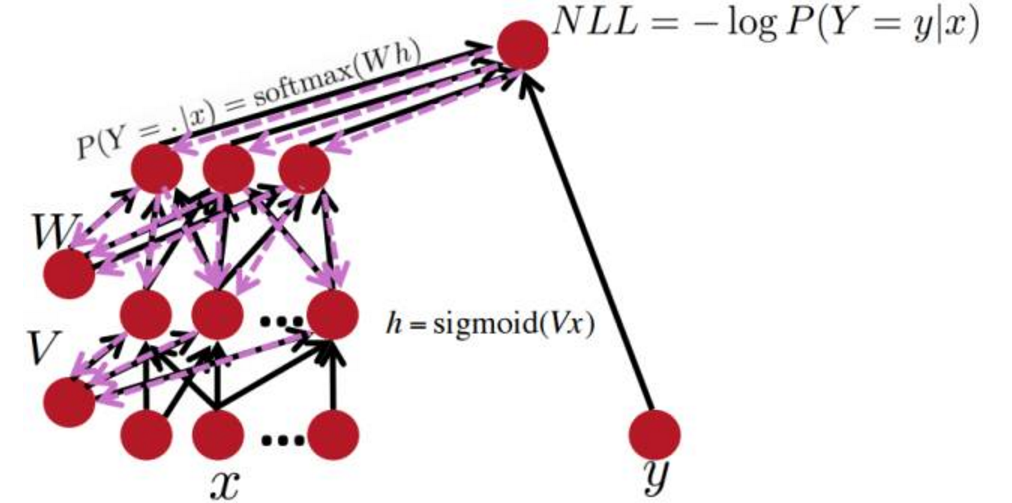
梯度的计算可以由前向传播中的符号表达式自动推理得到。给定输出关于它的梯度,每个节点需要知道如何计算输出和如何计算该节点关于对应输入的梯度。
