


















本站文章版权归原作者及原出处所有 。内容为作者个人观点, 并不代表本站赞同其观点和对其真实性负责。本站是一个个人学习交流的平台,并不用于任何商业目的,如果有任何问题,请及时联系我们,我们将根据著作权人的要求,立即更正或者删除有关内容。本站拥有对此声明的最终解释权。
29 个评论
辛苦了,写的很不错。后面多多出精品
整的很可以的!!加油
大伟,成功晋级老司机行列,求上车。
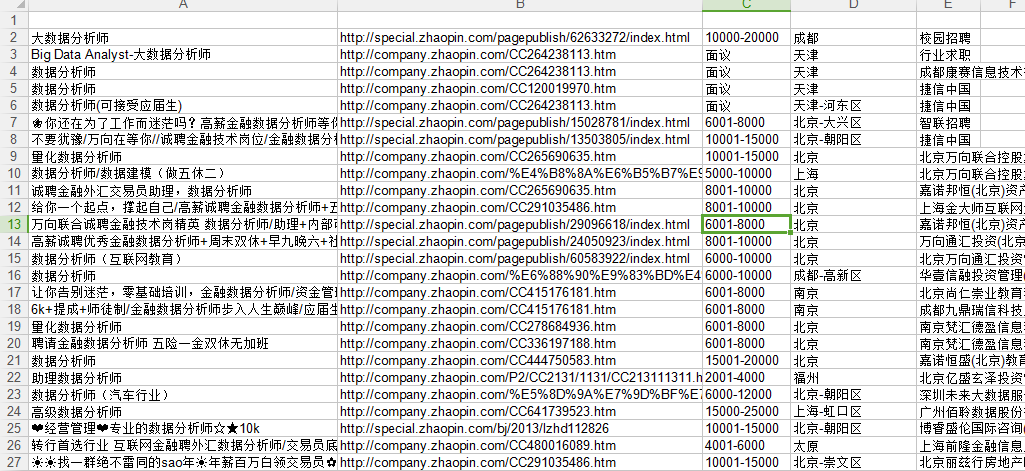
配图,满分

ID王大伟 回复 Jason_Huang
哈哈
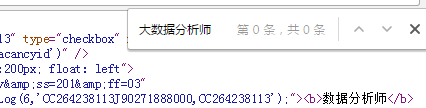
出现 出现异常:list index out of range 该怎么解决啊..
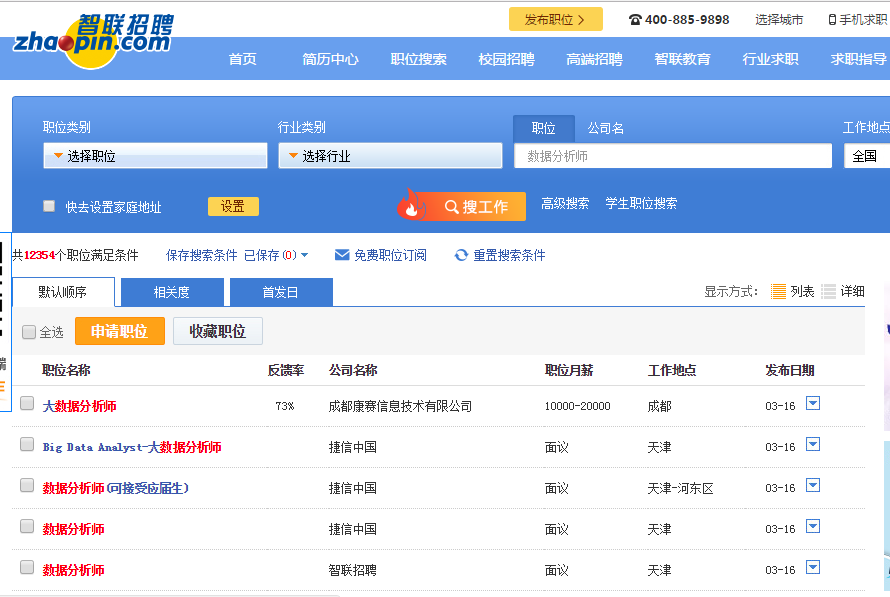
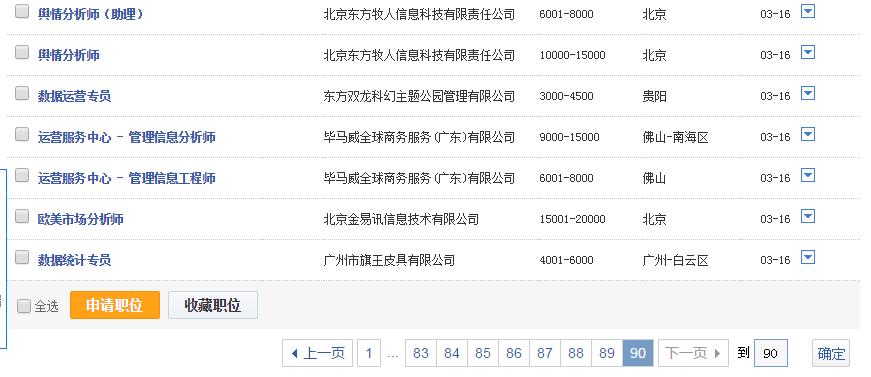
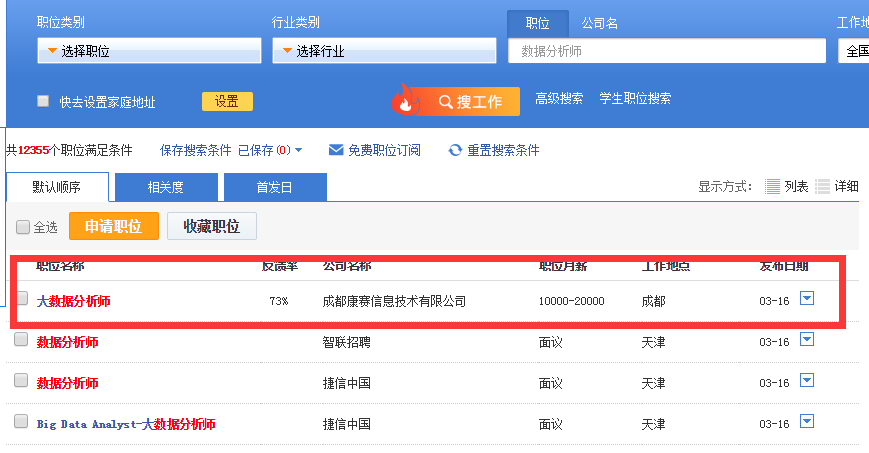
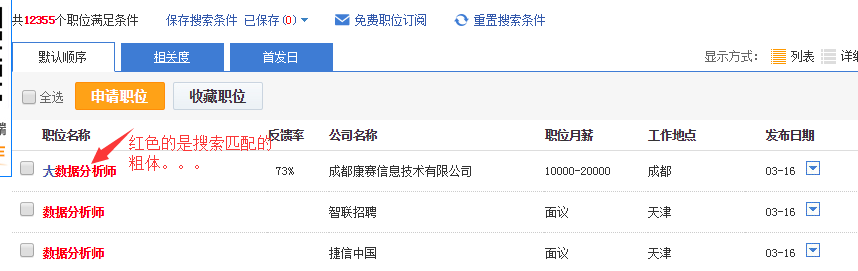
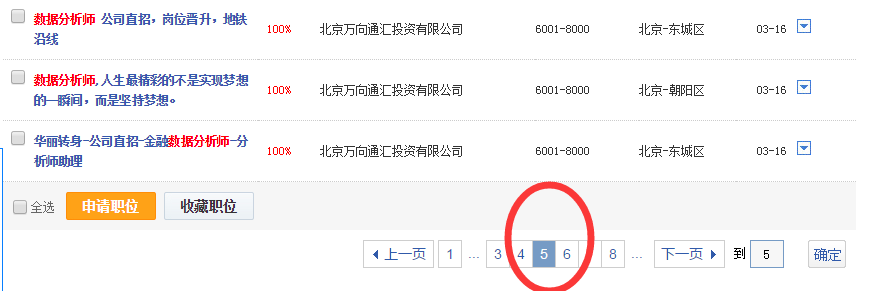
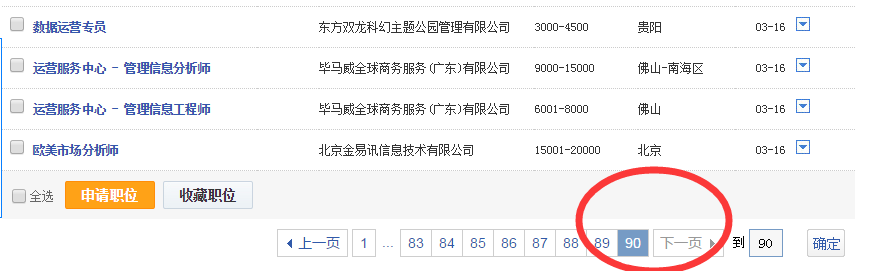
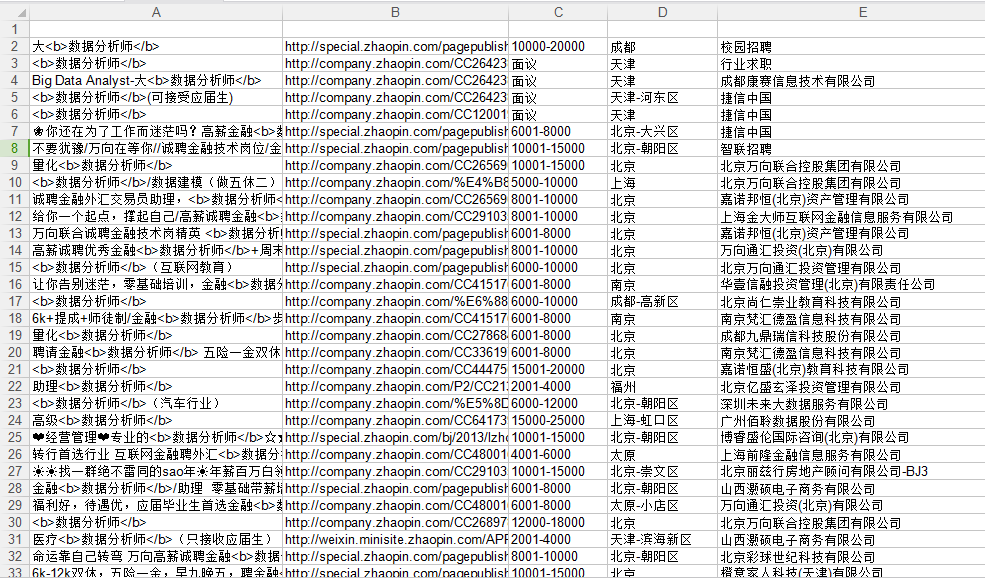
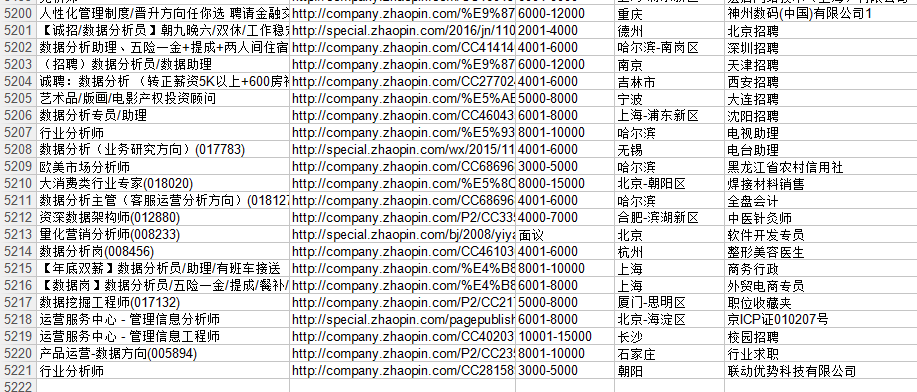
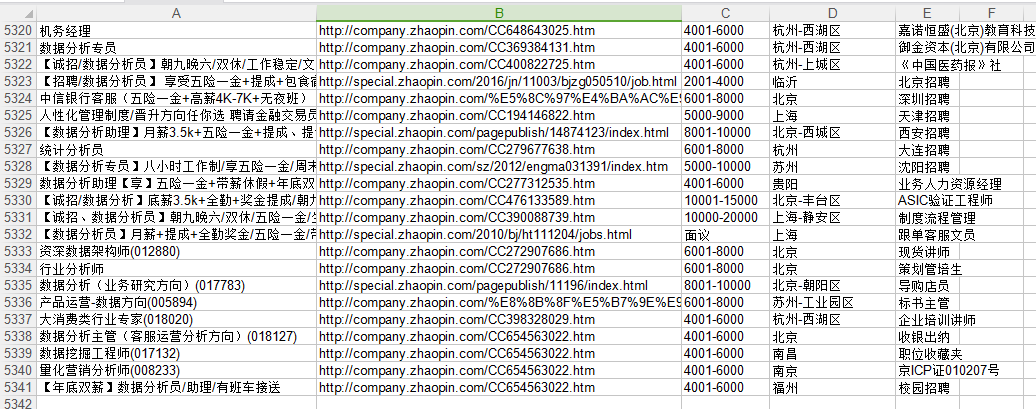
智联招聘上面是一页显示60条职位信息,所以爬90页应该是5400条信息,有时候爬出来可能只有5300+,不知道为什么,希望有dalao可以指点。我对比了一下爬出来的信息和网页上显示的顺序,发现有些是不一致的,这个也搞不懂
怎么配的图,在哪里可以自己生成图片?
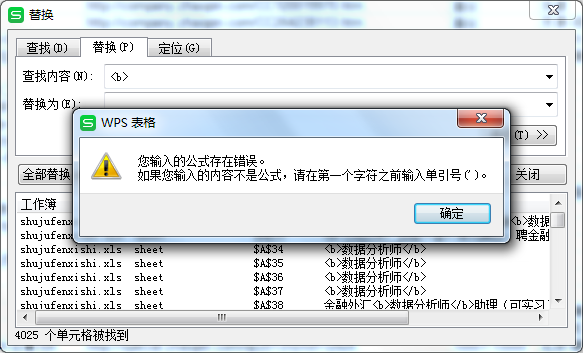
执行的时候报错了。不知道为啥。
年轻人,这样写代码不如函数式。
白的不能再白的小白了,有问题要问,pat1-5的地址是怎么来的?
为什么我用你的代码有excel但是没有一条数据
偶然之间在一个微信群里找到了你讲的课程连接,于是开始学习python
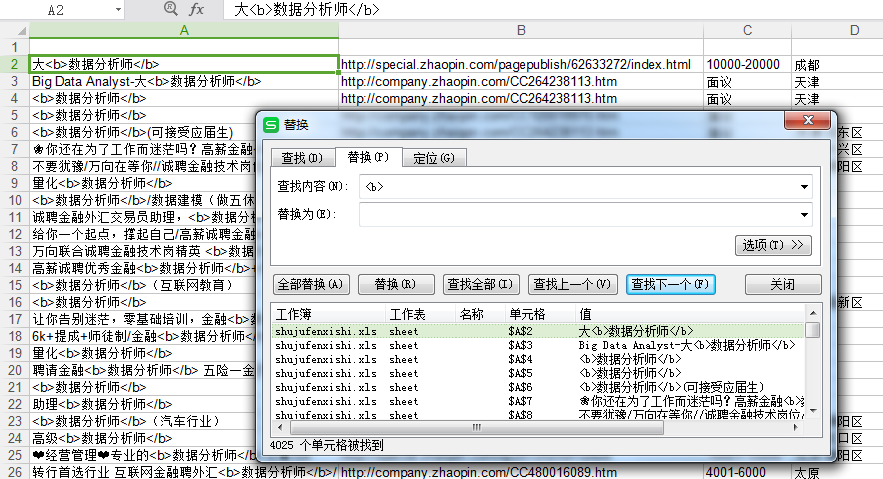
按照你的步骤执行完了,出来了个空的excel,不知道哪里出了问题,求指点
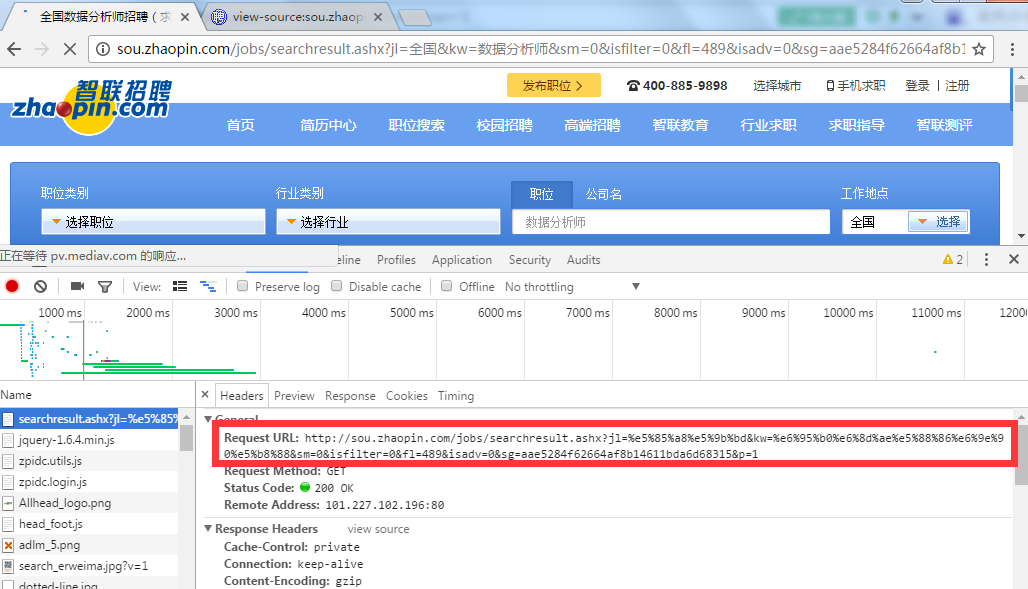
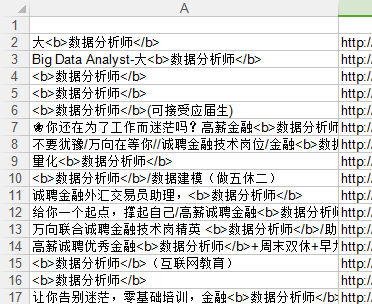
是不是爬出来的html有问题呢,我打印html,出来的是这样的
b'<!DOCTYPE HTML PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "//www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">\r\n<html xmlns="//www.w3.org/1999/xhtml">\r\n<head>\r\n \r\n <title>\xe5\x85\xa8\xe5\x9b\xbd\xe6\x95\xb0\xe6\x8d\xae\xe5\x88\x86\xe6\x9e\x90\xe5\xb8\x88\xe6\x8b\x9b\xe8\x81\x98\xef\xbc\x88\xe6\xb1\x82\xe8\x81\x8c\xef\xbc\x89 \xe6\x95\xb0\xe6\x8d\xae\xe5\x88\x86\xe6\x9e\x90\xe5\xb8\x88\xe6\x8b\x9b\xe8\x81\x98\xef\xbc\x88\xe6\xb1\x82\xe8\x81\x8c\xef\xbc\x89\xe5\xb0\xbd\xe5\x9c\xa8\xe6\x99\xba\xe8\x81\x94\xe6\x8b\x9b\xe8\x81\x98</title>\r\n<META
b'<!DOCTYPE HTML PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "//www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">\r\n<html xmlns="//www.w3.org/1999/xhtml">\r\n<head>\r\n \r\n <title>\xe5\x85\xa8\xe5\x9b\xbd\xe6\x95\xb0\xe6\x8d\xae\xe5\x88\x86\xe6\x9e\x90\xe5\xb8\x88\xe6\x8b\x9b\xe8\x81\x98\xef\xbc\x88\xe6\xb1\x82\xe8\x81\x8c\xef\xbc\x89 \xe6\x95\xb0\xe6\x8d\xae\xe5\x88\x86\xe6\x9e\x90\xe5\xb8\x88\xe6\x8b\x9b\xe8\x81\x98\xef\xbc\x88\xe6\xb1\x82\xe8\x81\x8c\xef\xbc\x89\xe5\xb0\xbd\xe5\x9c\xa8\xe6\x99\xba\xe8\x81\x94\xe6\x8b\x9b\xe8\x81\x98</title>\r\n<META
谢谢
很不错呀