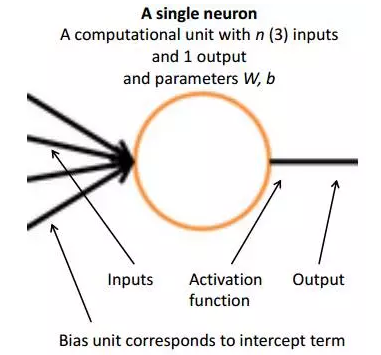
神经网络跟支持向量机类似,有其相应的术语。如果理解了逻辑回归或maxent网络的原理,那么就已经理解了神经网络的基本神经元的工作原理。
下面是一个神经元的示例。其中输入是三维的,即每个输入包含三个变量,通过基于参数W和b的变换就可以得到输出。
在NLP中,maxent分类器一般形式如下:
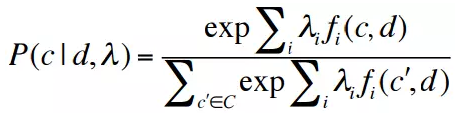
有监督学习中给出了类别集合C中数据d的分布。上式写成向量形式如下:
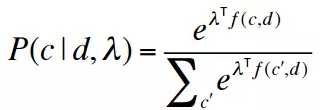
这种分类器跟神经网络中的softmax 层的分类器类似,神经网络中顶层形式如下:
J = sofxmax(λ·x)
这里给出一个二分类的神经元对应的logistic模型推导。
上述向量形式在二分类问题中具有如下形式:
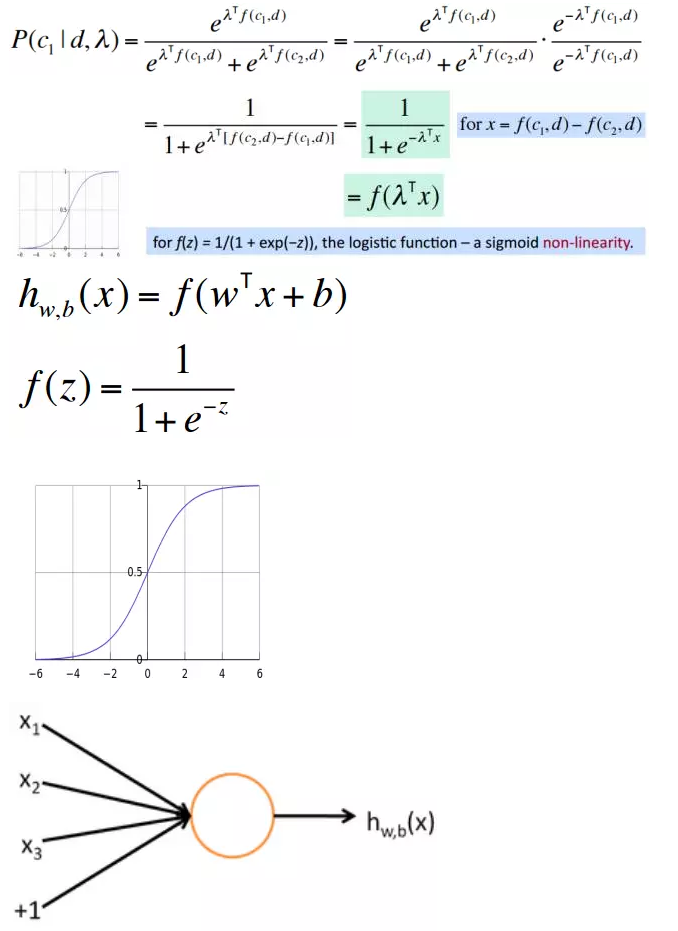
其中 b 可以看作一个 “always on” 的特征,它给出了类别的先验知识,也可以将它分离出来,看做一个偏置项。w, b 是这个神经元中的参数, 也即逻辑回归模型的参数。
事实上,神经网络相当于同时运行多个逻辑回归模型。这是因为如果我们将一个输入向量送入一系列逻辑回归模型中,则可以得到一个输出向量,这个输出向量又可以送入另外一个逻辑回归模型,进而可以得到一个多层神经网络。但是我们不需要事先给出这些逻辑回归会给出什么预测。
对于每个中间隐含层,训练标准会引导它的取值,进而有助于预测下一层的目标,以此类推。
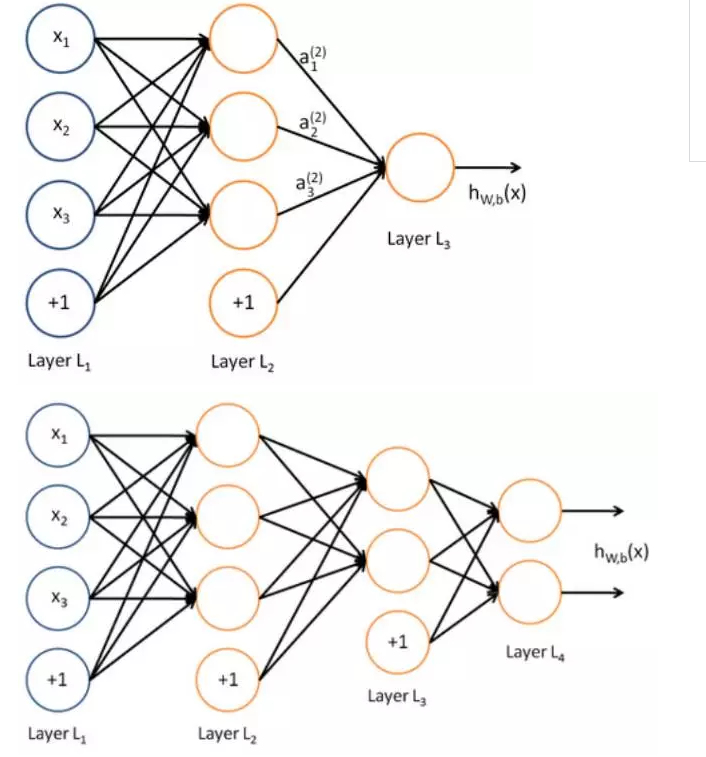
每一层用矩阵如何表示呢?非矩阵形式如下:
矩阵形式可以表示成
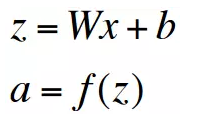
其中f是对每一个元素加以作用的,如下面的例子:
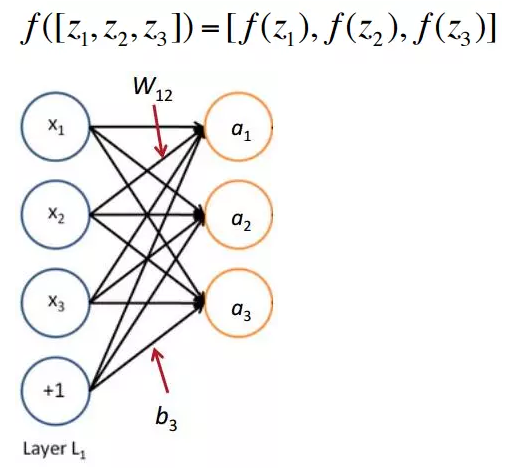
如何训练权值矩阵呢?
• 对于每个有监督的层,可以像maxent模型那样累训练 – 可以借助于梯度计算衍生误差并将其反向传播来提升性能。
有以下两种方式: • Online learning: 随机梯度下降法 (SGD) 或者提升版本,比如 AdaGrad (Duchi, Hazan, & Singer 2010) • Batch learning: 共轭梯度法或 L-BFGS
• 多层网络可能会变得比较复杂,因为内部的隐含层--逻辑单元使得函数是非凸的,这跟隐含 CRFs 类似 [Quattoni et al. 2005, Gunawardana et al. 2005],在多层网络中需要使用衍生误差反向传播来提升模型的性能。
接下来讨论为什么需要非线性变换
在逻辑回归中,非线性变换可以将输入映射为概率。在函数近似中,比如回归或分类问题中,如果没有非线性,则深度神经网络不能比线性变换多出什么额外的功能。如果每次变换都是线性变换,即使有多个层,最终都可以简化为一个线性变换。除非在玻尔兹曼机或图模型中,概率解释不是必须的,非概率情形中,可以利用其它非线性变换,比如tanh。
最后来总结下基本术语:
• Neuron: 逻辑回归或类似的函数 • Input layer : 输入向量,包含训练和测试 • Bias unit: 截距,通常是跟特征相关联 • Activation: 响应 • Activation function: 逻辑回归或者类似的 “sigmoid” 非线性变换 • Backpropagation: 多层网络中逐层随机梯度下降后向反馈 • Weight decay: 正则条件或贝叶斯先验知识
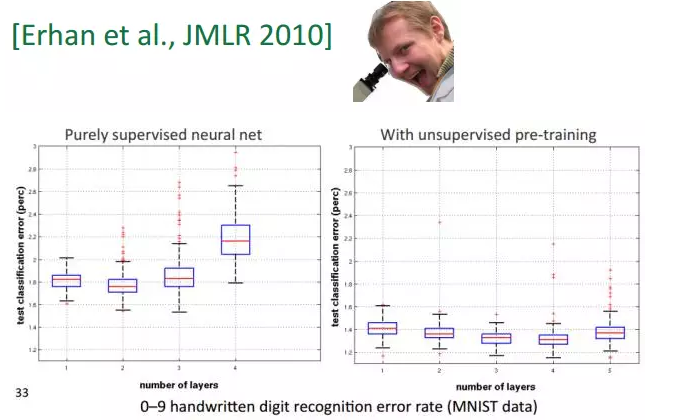
有效的深度学习因为无监督预训练方法的出现而出现生机。比如无监督预训练是借助于RBM或去噪自编码来实现。