数据探索过程中往往需要了解数据的分布情况,例如上、下四分位数的位置、数据符合哪种分布等,下文将使用R的ggplot2包探索数据分布情况。
绘制直方图
数据探索中,使用最为广泛的分布图就是直方图,ggplot2包中的geom_histogram()函数就可方便的实现直方图的绘制。
library(ggplot2)
set.seed(1234)
x <- rnorm(1000,mean = 2, sd = 3)
ggplot(data = NULL, mapping = aes(x = x)) + geom_histogram()

由于直方图的绘制,只需要传递一个变量的数据,如果收集的数据是数据框,ggplot()中的参数正常设置;如果收集的数据仅仅是一个向量,那么ggplot()中data参数需要设置为NULL,其余参数可正常设置。
默认情况下,直方图将数据切割为30组,即bins = 30,如果对默认分组不满意,可以自定义直方图的组距(binwidth = )和分组数量(bins = );如果对默认的颜色不敏感,也可以自定义直方图的填充色和边框颜色。
#将数据切割为50组,并将直方图的填充色设置为铁蓝色,边框色设置为黑色
ggplot(data = NULL, mapping = aes(x = x)) + geom_histogram(bins = 50, fill = 'steelblue', colour = 'black')
#将直方图的组距设置为极差的二十分之一
group_diff <- diff(range(x))/20
ggplot(data = NULL, mapping = aes(x = x)) + geom_histogram(binwidth = group_diff, fill = 'steelblue', colour = 'black')
绘制分组直方图
对于分组直方图,必须为直方图传递一个分组变量,这个变量可以是字符型变量,也可以是因子型的数值变量。一般绘制分组直方图,有两种方式,即:
1)将分组变量映射给颜色属性
2)使用ggplot2包中的分面功能
有关分面的介绍可查看链接:
ggplot2作图之分面操作
#将分组变量映射给颜色属性
set.seed(1234)
x <- c(rnorm(500,mean = 1, sd = 2), rt(500, df = 10))
y <- rep(c(0,1), times = c(500,500))
df <- data.frame(x = x ,y = y)
#将数值型分组变量进行因子化
df$y = factor(df$y)
ggplot(data = df, mapping = aes(x = x, fill = y)) + geom_histogram(position = 'identity', bins = 50, colour = 'black')

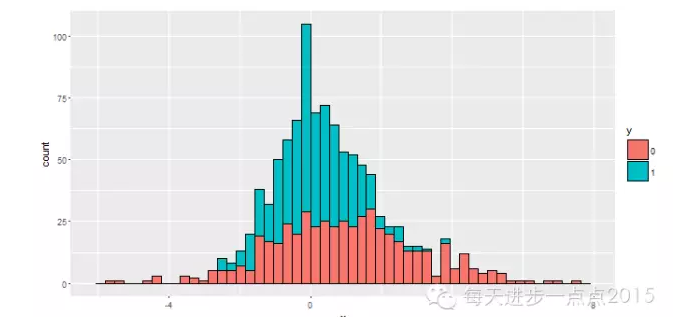
这里必须提醒的是,如果将分组变量映射给颜色时,必须将position参数设置为‘identity’,否则绘制的直方图将是堆叠的,反而失去了分布图的对比。如下图所示:
ggplot(data = df, mapping = aes(x = x, fill = y)) + geom_histogram( bins = 50, colour = 'black')
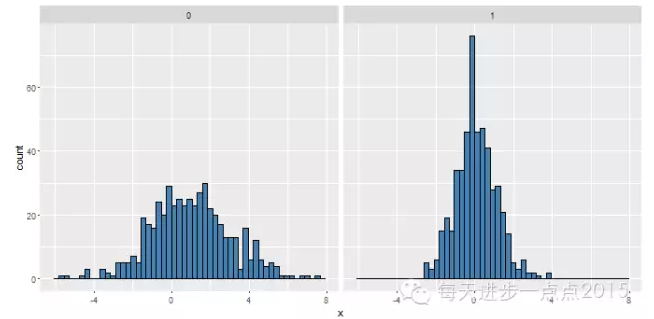
#使用分面功能
ggplot(data = df, mapping = aes(x = x)) + geom_histogram( bins = 50, fill = 'steelblue', colour = 'black') + facet_grid(. ~ y)
绘制核密度曲线
除了直方图可以很好的表达数据的分布情况,还可以通过核密度曲线生成数据的分布估计,下面使用geom_density()函数和geom_line()函数中stat='density'两种方法绘制核密度曲线。
#使用geom_density()函数绘制核密度曲线
state <- as.data.frame(state.x77)
ggplot(data = state, mapping = aes(x = Income)) + geom_density()
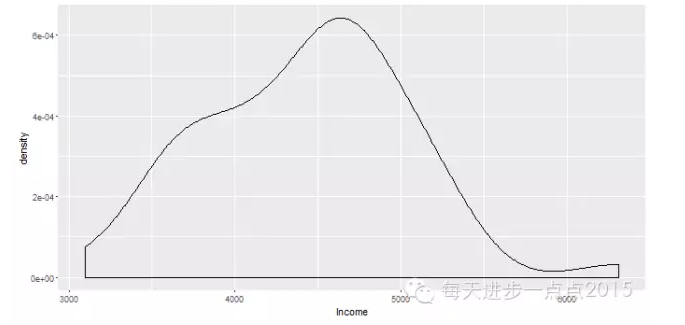
#geom_line()函数绘制核密度曲线
ggplot(data = state, mapping = aes(x = Income)) + geom_line(stat = 'density')
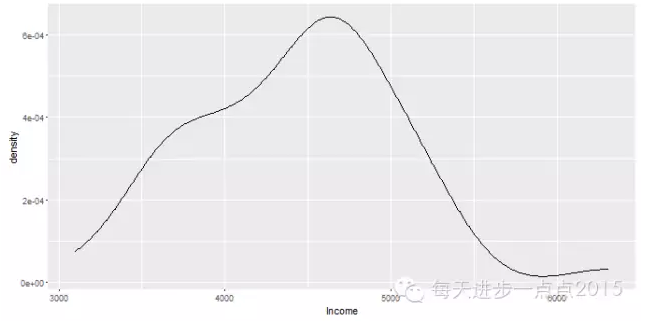
这两幅图的最大区别就是geom_density()函数绘制的核密度图两侧和底部有线段。有关核密度图的一个非常重要参数就是带宽,带宽越大,曲线越光滑,默认带宽为1,可以通过adjust参数进行调整。
#为了对比不同带宽,将密度图绘制在一起
ggplot(data = state, mapping = aes(x = Income)) + geom_line(stat = 'density', adjust = 0.5, colour = 'red',size = 2) + geom_line(stat = 'density', adjust = 1, colour = 'black', size = 2) + geom_line(stat = 'density', adjust = 2, colour = 'steelblue', size = 2)
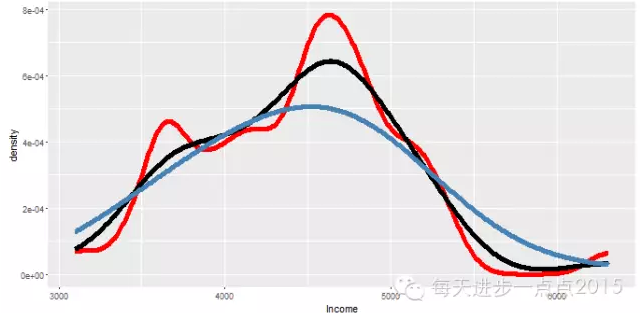
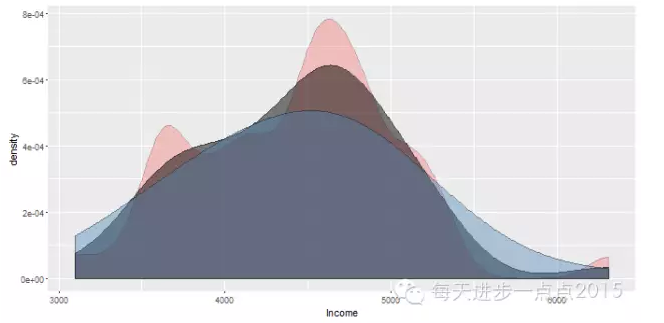
而且还可以为密度图填充颜色,但这里必须使用geom_density()函数
ggplot(data = state, mapping = aes(x = Income)) + geom_density( adjust = 0.5, fill = 'red',alpha = .2) + geom_density(adjust = 1, fill = 'black', alpha = .5) + geom_density(adjust = 2, fill = 'steelblue', alpha = .4)
同样,密度曲线也可以进行分组绘制,方法与直方图一致,这里使用两个例子说明:
#将分组变量映射给颜色属性
set.seed(1234)
x <- c(rnorm(500), rnorm(500,2,3), rnorm(500, 0,5))
y <- rep(c('A','B','C'), each = 500)
df <- data.frame(x = x, y = y)
ggplot(data = df, mapping = aes(x = x, colour = y)) + geom_line(stat = 'density', size = 2)
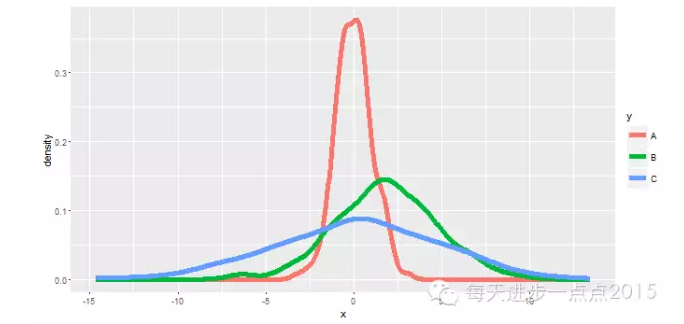
#使用分面功能
ggplot(data = df, mapping = aes(x = x, colour = y)) + geom_density(size = 2) + facet_grid(. ~ y)
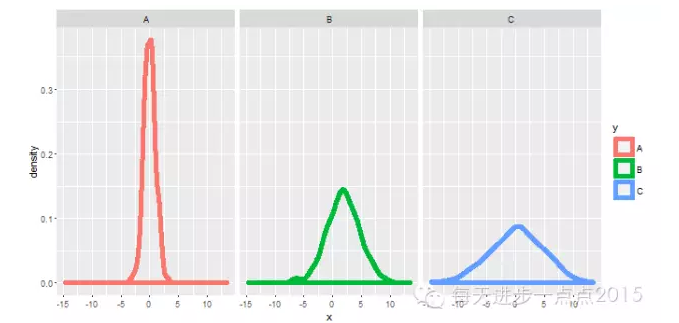
上面分别介绍了直方图和核密度曲线的绘制,接下来将把两种图形组合在一起,可对数据的理论分布和实际分布进行比较。
ggplot(data = df, mapping = aes(x = x)) + geom_histogram(bins = 50, fill = 'blue', colour = 'black') + geom_density(adjust = 0.5, colour = 'black', size = 2) + facet_grid(. ~ y)
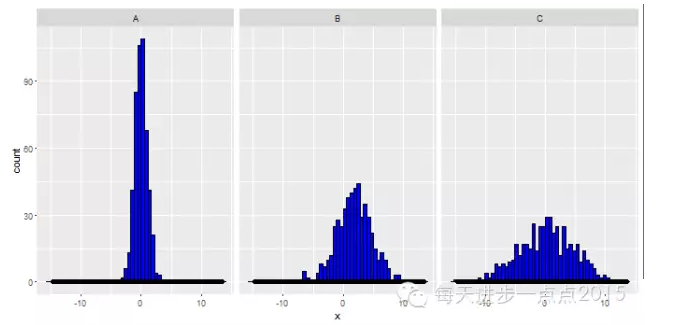
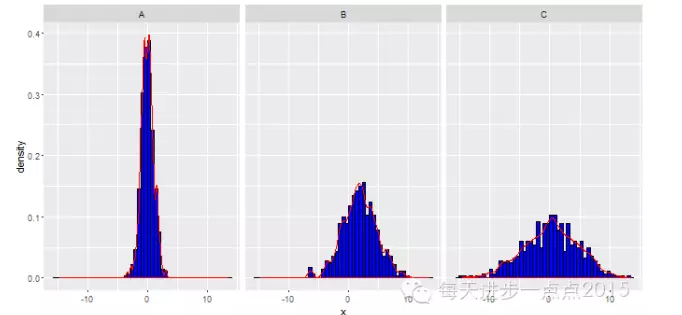
发现一个问题,密度曲线被压成了一条线,原因是密度曲线的纵轴范围为0~1, 而直方图的纵轴范围0~120。为解决该问题,只需将直方图中的y值改为..density..即可。
ggplot(data = df, mapping = aes(x = x)) + geom_histogram(aes(y = ..density..), bins = 50, fill = 'blue', colour = 'black') + geom_density(adjust = 0.5, colour = 'red') + facet_grid(. ~ y)
绘制箱线图
绘制箱线图也是数据探索过程中常用的手法,箱线图的实现可以使用ggplot2包中的geom_boxplot()绘制。箱线图一般使用在分组变量中,即通过箱线图的比较,发现组别之间的差异。
ggplot(data = iris, mapping = aes(x = Species, y = Sepal.Width)) + geom_boxplot(fill = 'steelblue')
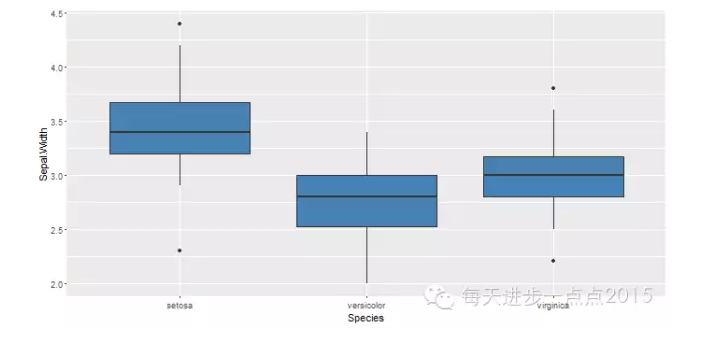
图中黑点即为离群点,关于离群点可以将其设置为不同的颜色和形状,用于醒目标示,除此,还可以调整箱线图的宽度,默认宽度为1。
ggplot(data = iris, mapping = aes(x = Species, y = Sepal.Width)) + geom_boxplot(fill = 'steelblue', outlier.colour = 'red', outlier.shape = 15, width = 1.2)
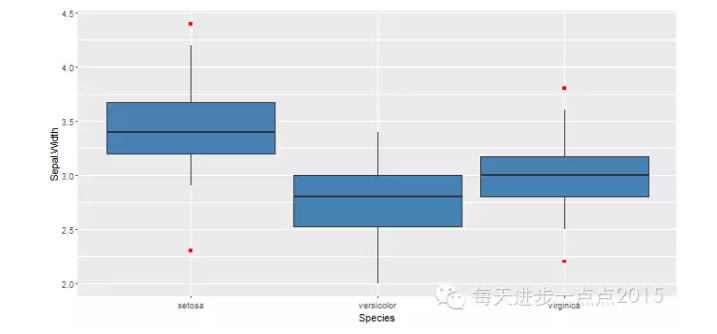
为了比较各组数据中位数的差异,可以为盒形图设置槽口,只需将geom_boxplot()函数中notch参数设置为TRUE
ggplot(data = iris, mapping = aes(x = Species, y = Sepal.Width)) + geom_boxplot(notch = TRUE, fill = 'steelblue', outlier.colour = 'red', outlier.shape = 15, width = 1.2)
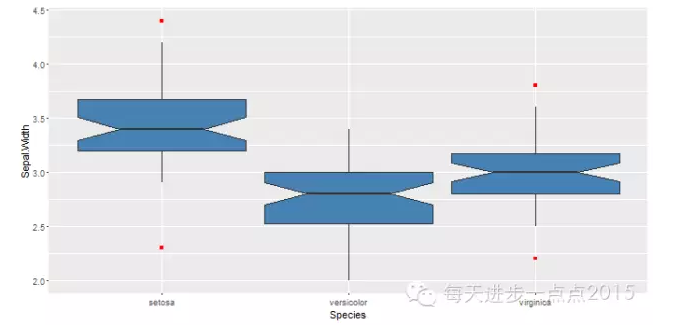
如果各箱线图的槽口互补重合,则说明各组数据的中位数是由差异的。
如何绘制不分组的箱线图呢?这里的提醒点非常重要:
1)必须给x赋一个常量值,赋值将会报错
2)清除x轴上的刻度标记和标签
ggplot(data = iris, mapping = aes(x = 'Test', y = Sepal.Width)) + geom_boxplot(fill = 'steelblue', outlier.colour = 'red', outlier.shape = 15, width = 1.2)
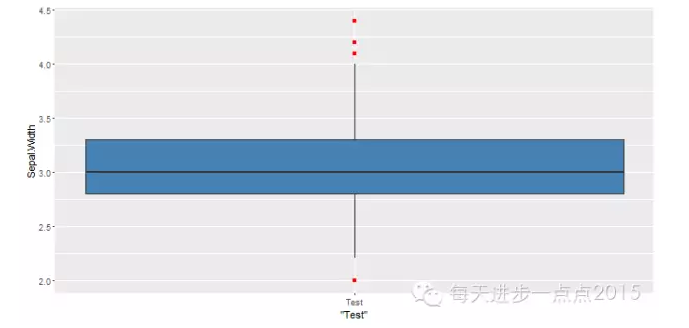
#清除x轴上的刻度标记和标签
ggplot(data = iris, mapping = aes(x = 'Test', y = Sepal.Width)) + geom_boxplot(fill = 'steelblue', outlier.colour = 'red', outlier.shape = 15, width = 1.2) + theme(axis.title.x = element_blank()) + scale_x_discrete(breaks = NULL)

我们发现,对于默认的盒形图,将会展示最小值、下四分位数、中位数、上四分位数和最大值的位置,如果想查看均值或方差的位置该如何添加呢?同样很简单,只需在图层上添加一层stat_summary()的值即可。
ggplot(data = iris, mapping = aes(x = 'Test', y = Sepal.Width)) + geom_boxplot(fill = 'steelblue', outlier.colour = 'red', outlier.shape = 15, width = 1.2) + theme(axis.title.x = element_blank()) + scale_x_discrete(breaks = NULL) + stat_summary(fun.y = 'mean', geom = 'point', shape = 18, colour = 'orange', size = 5)

绘制小提琴图
在学习《R语言实战》这本书,就提到了小提琴图,并且预测该图形的应用将受到重视。ggplot2包也将该图形纳入范畴,通过geom_violin()函数可以轻松绘制小提琴图。
小提琴图实质上也是核密度估计,其用来对多组数据的分布进行比较,如果使用上文中的密度曲线时容易被多条彩色曲线所干扰,而小提琴图是并排排列,对分组数据的分布进行比较比较容易一些。
#绘制普通的小提琴图
ggplot(data = iris, mapping = aes(x = Species, y = Sepal.Width)) + geom_violin()
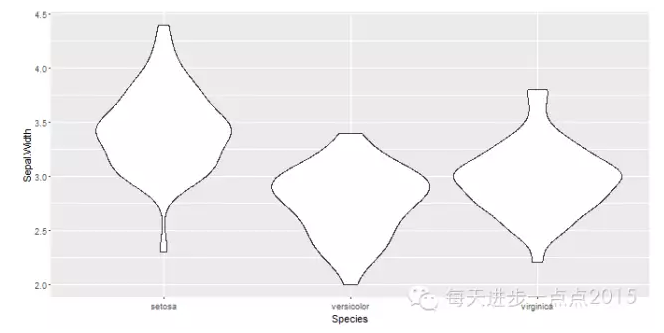
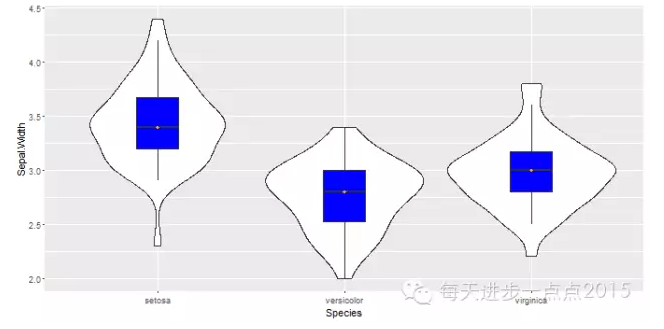
除此,我们还可以将小提琴图与盒形图进行组合,即可以了解数据的分布形态,又可以了解数据的具体分布。
#绘制叠加盒形图的小提琴图
ggplot(data = iris, mapping = aes(x = Species, y = Sepal.Width)) + geom_violin() + geom_boxplot(width = 0.3, outlier.colour = NA, fill = 'blue') + stat_summary(fun.y = 'median', geom = 'point', shape = 18, colour = 'orange')
默认情况下,系统对小提琴图进行标准化处理,使得各组数据对于的图的面积一样,如果对这样的设置不满,还可以将sacle参数设为‘count’,使图的面积观测值数目成正比。
set.seed(1234)
x <- rep(c('A','B','C'), times = c(100,300,200))
y <- c(rnorm(100), rnorm(300,1,2), rnorm(200,2,3))
df <- data.frame(x = x, y = y)
ggplot(data = df, mapping = aes(x = x, y = y)) + geom_violin(scale = 'count') + geom_boxplot(width = 0.1, outlier.colour = NA, fill = 'blue') + stat_summary(fun.y = 'median', geom = 'point', shape = 18, colour = 'orange')
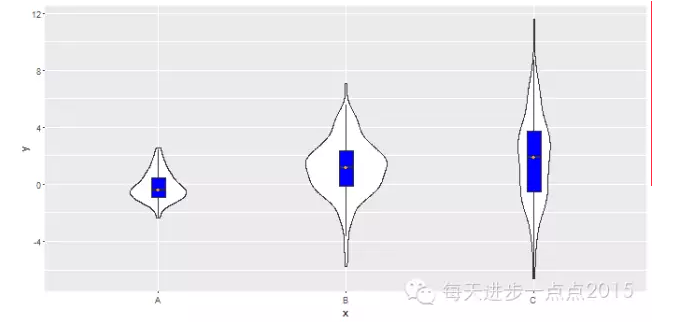
很明显,小提琴图的面积大小有很大差异,原因是各组的观测数量分别为100,300和200。
绘制二维密度分布图
以上数据的探索均是基于1维数据的直方图、核密度曲线、盒形图和小提琴图,下面使用ggplot2包探索一下2维数据的分布情况,有关二维数据的分布常使用密度图进行探索。
使用stat_density2d()函数实现二维数据的核密度估计,具体探索见下文的几个例子:
library(C50)
data(churn)
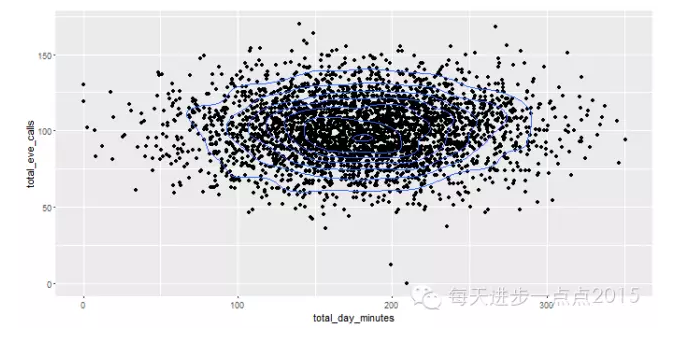
#绘制散点图和密度等高线
ggplot(data = churnTrain, mapping = aes(x = total_day_minutes, y = total_eve_calls)) + geom_point() + stat_density2d()
#使用..level..,将密度曲面的高度映射给等高线的颜色
ggplot(data = churnTrain, mapping = aes(x = total_day_minutes, y = total_eve_calls)) + stat_density2d(aes(colour = ..level..)) + scale_color_gradient(low = 'lightblue', high = 'darkred')
由上面两幅图发现,衡量数据分布的密集情况是通过默认的等高线展示,也可以选择瓦片图展示数据的分布情况。
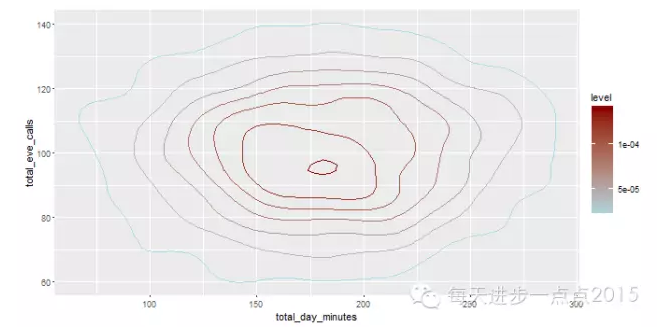
由上面两幅图发现,衡量数据分布的密集情况是通过默认的等高线展示,也可以选择瓦片图展示数据的分布情况。
#将密度估计映射给填充色
ggplot(data = churnTrain, mapping = aes(x = total_day_minutes, y = total_eve_calls)) + stat_density2d(aes(fill = ..density..), geom = 'tile', contour = FALSE)

#将密度估计映射给透明度
ggplot(data = churnTrain, mapping = aes(x = total_day_minutes, y = total_eve_calls)) + stat_density2d(aes(alpha = ..density..), geom = 'tile', contour = FALSE)
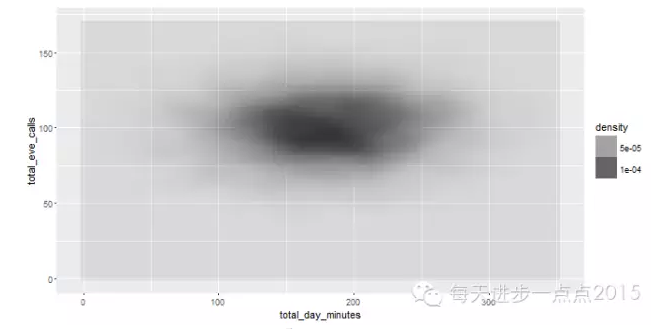
前文中我们说过,核密度曲线是有一个非常重要的参数,即带宽,可以通过带宽的调整提高核密度曲线对实际数据分布的估计精度,同样在二维核密度曲线中,也可以为两个变量设置带宽,所不同的是,这里设置带宽用参数h实现。
ggplot(data = iris, mapping = aes(x = Petal.Length, y = Petal.Width)) + stat_density2d(aes(alpha = ..density..), geom = 'tile', contour = FALSE, h = c(0.1,0.2))

很明显,通过带宽的调整,上下两幅密度图存在差异,上一幅图仅出现1个高密度集聚点,而下一幅图则出现了两个高密度聚集点。
参考资料
R语言实战
R语言_ggplot2:数据分析与图形艺术
R数据可视化手册
每天进步一点点2015
学习与分享,取长补短,关注小号!



