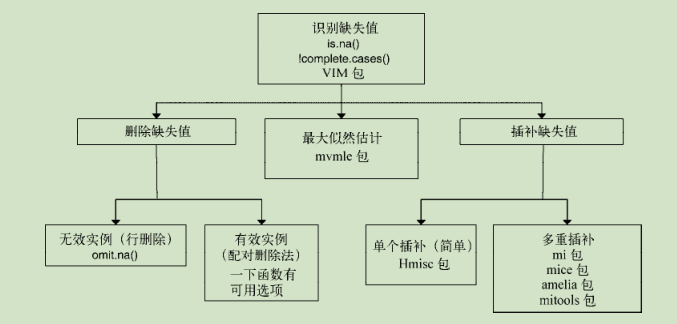
处理步骤:
- 识别缺失数据
- 检查导致数据缺失的原因(分类:mcar(完全随机缺失),随机缺失(mar),非随机缺失(nmar),后边最常见)
- 删除包含缺失值的实例或用合理的数值代替缺失值
识别缺失值
NA:代表缺失值
NAN:代表不可能值
函数is.na() is.nan()和is.infinite()可用来识别缺失值不可能值 和无穷值,返回逻辑值

complete.cases()可以用来识别矩阵或数据框中没有缺失值的行,如包含,返回true(注意和前边正好相反)
代码:
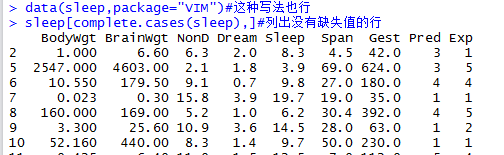


探索缺失值模式(发现缺失值模式)
1:列表显示缺失值
存在原因:对于数据集的增大,之上方法丧失吸引力
包:mice包 md.pattern()函数可生成一个以矩阵或数据框形式展示缺失值模式的表格

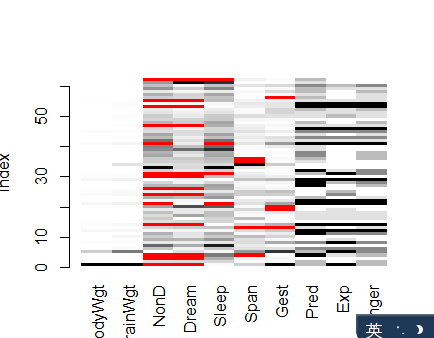
2:图形探究缺失数据
包:aggr() matrixplot() 和scattmiss()
图形如下

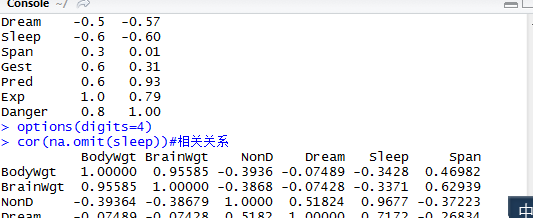
解读:1图表示每个变量的缺失值数,比如nond缺失值为14,位最大
2图表是表每个观测值的缺失值个数,红色为缺失值
另外一个matrixplot()函数可生成展示每个实例数据的图形
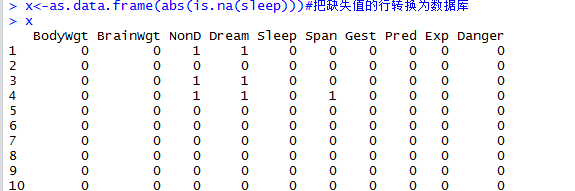
3用相关性探索缺失值
Is.na的返回值是1或者0,用指示变量代替原数据集,也叫影子矩阵,对影子矩阵就是对原数据集操作

代码:

识别缺失值数据的来由和影响
目的:1)分析生成缺失数据的潜在机制
2)评价缺失数据对回答实质性问题的影响
- 3种方法:恢复数据的推理方法,涉及删除缺失值的传统方法和涉及模拟的现代方法
- 目标:在没有完整信息的情况下,尽可能精确的回答收集数据所要解决的实质性问题
理性处理不完整数据
推理方法:根据变量间的数学或者逻辑关系来填补或恢复缺失值
完整实列分析(行删除)
complete.cases()
na.omit()
以上是存储没有缺失值的数据框或者矩阵形式的实例(行)


总:行删除法假定数据是MCAR(完整数据的观察只是全数据集的一个随机子样本),由于删除了所有含缺失值的观测,减少了可用的样本,这也导致统计效力的降低
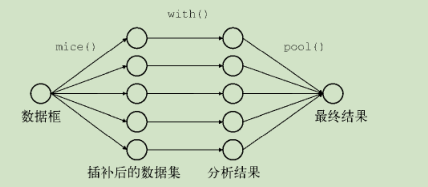
多重插补法(MI)
确实数据用蒙特卡洛方法来填补
重点:mice包
以下图形可以加强理解


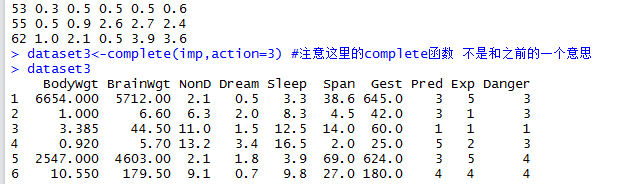
注意:以上3是创建的5个中的第3个
其它方法

还有2个过时的方法,分别是:
成对删除或者简单插补
ps:把精力放在实际能利用的地方,对于不能用的可以了解了解下就行



