前文传送门:
从零开始学自然语言处理(十一)——keras实现textCNN
在说上下文无关文法之前,我们来看看形式语言理论,什么是形式语言理论?形式语言理论形式语言理论是用数学方法研究自然语言或者程序设计语言的理论。研究语言组成规则,而不研究语言的具体含义。说到形式语言,必须说一下它的形式文法。形式文法被严格地定义为四元组G=(N,T,P,S)
S:start 开始符号
P:productions 生成式集合
T:terminal 终结符集合
N:Nonterminal 非终结符集合
文法形式语言中主要有4种文法:
0型文法(无限制文法)
1型文法(上下文有关文法)
2型文法(上下文无关文法)
3型文法(正则文法)
我们现在不用纠结每种文法的具体含义,因为我们暂时只需要了解2型文法(上下文无关文法)即可。
之前说过,形式语言理论会用在自然语言中,文法也会用在自然语言中,我们举个例子看看:
当我们在小学学习语文课程时,会说到句子的结构,例如句子的结构可以是:主语+谓语+宾语,可以用名词+动词+名词表示。
如果你还有印象,小时候语文作业有一种习题叫做造句或者将词语按顺序组成句子,就是从给定的词语中选取部分词语构成句子。
例如给定的词语集合是:【羊 老虎 草 水 吃 喝】,我们首先可以将词语分类为:
名词:{羊 老虎 草 水},
动词:{吃 喝}
我们可以按照给出的词语库和之前说的句子结构(名词+动词+名词)造出很多句子:
例如:羊吃草 羊喝水 草吃老虎
我们先不管这个造句是否符合常理,
例如 草吃老虎 就不符合常理。
我们将刚说的例子抽象出来,做形式化分析:我们做如下定义:
S表示句子,->表示推出,N表示名词,V表示动词则句子结构可以表示为:S -> N V N
按照不同词性将词分类的规则整理为:N -> 羊 | 老虎 | 草 | 水V -> 吃 | 喝
我们将其中的大写符号叫做非终结符:{S, N, V}
将这里的名词和动词叫做终结符:{羊 老虎 草 水 吃 喝}
接下来说说最左推导和最右推导最左推导:每次总是选择最左侧的符号进行替换即对于上例中的 N V N ,首先替换最左边的 N 为 羊, 再替换之后最左侧的非终结符 V 为 吃, 最后替换最右边一个非终结符 N 为 羊
最终推导出 羊吃羊
最右推导:每次总是选择最右侧的符号进行替换,在这个例子里的结果是:水喝水
语法分析给定文法 G 和句子 S, 语法分析要回答的问题是:是否存在对句子 S 的推导?若仍然选择上面的文法 G,当 S = 羊喝水 时,我们能够实现 S 通过若干步的推导得到。
所以回答:是。
若 S = 吃喝水, 则不能实现该推导,
回答:否。
大家到这里应该发现了,文法是用来定义句子结构的。
当我们在进行句法结构分析的时候,上下文无关文法(CFG)是最常用的句法知识形式化的工具。
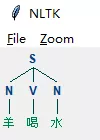
我们可以通过nltk工具包实现给定文法情况下句子的句法结构分析:
from nltk import CFG
import nltk
grammar = CFG.fromstring("""
S -> N V N
N -> '羊' | '老虎' | '草' | '水'
V -> '吃' | '喝'
""")
sent = '羊 喝 水'
sent = nltk.word_tokenize(sent)
parser = nltk.ChartParser(grammar)
trees = parser.parse(sent)
for tree in trees:
tree.draw()
我们可以看一个更复杂的句法结构分析,主要是文法更加复杂了。
from nltk import CFG
import nltk
grammar = CFG.fromstring("""
S -> NP VP
PP -> P NP
NP -> Det N | Det N PP | 'I'
VP -> V NP | VP PP
Det -> 'an' | 'my'
N -> 'elephant' | 'pajamas'
V -> 'shot'
P -> 'in'
""")
sent = 'I shot an elephant in my pajamas'
sent = nltk.word_tokenize(sent)
parser = nltk.ChartParser(grammar)
trees = parser.parse(sent)
for tree in trees:
tree.draw()
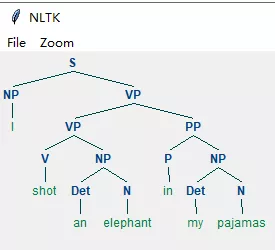
第一种:
第二种:
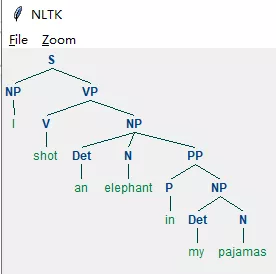
从结果可以看出,nltk输出了两种句法结构分析结果,这两种结构都符合该文法规则。
关注“数据科学杂谈”公众号,带你零基础学习自然语言处理~
扫码下图关注我们不会让你失望!

