前文传送门:
从零开始学自然语言处理(六)—— 命名实体识别
在之前的 从零开始学自然语言处理(六)—— 命名实体识别 文章中,我们使用了 standford CoreNLP 工具,本文中,我们继续会使用 standford CoreNLP 进行句法分析。
句法分析分为句法结构分析(syntactic structure parsing)和依存关系分析(dependency parsing)。
以获取整个句子的句法结构为目的的称为完全句法分析,而以获得局部成分为目的的语法分析称为局部分析,依存关系分析简称依存分析。
今天我们看看句法结构分析。
简单的讲,句法结构分析方法可以分为基于规则的分析方法和基于统计的分析方法两大类。
顾名思义,句法结构分析可以帮我们分析出句子的句法结构信息(如:主谓宾、定状补)。
from nltk.parse.stanford import StanfordParser
chi_parser = StanfordParser(r"C:\Users\Dell\Downloads\stanford-parser-full-2018-10-17\stanford-parser.jar",r"C:\Users\Dell\Downloads\stanford-parser-full-2018-10-17\stanford-parser-3.9.2-models.jar",r"F:\stanford-parser-3.9.2-models\edu\stanford\nlp\models\lexparser\chinesePCFG.ser.gz")
其中,用到的内容在 从零开始学自然语言处理(六)—— 命名实体识别文章中提过,用到的chinesePCFG.ser.gz在stanford-corenlp-full-2018-10-05中的stanford-corenlp-3.9.2-models.jar解压后的内容中。
文末扫码关注公众号“数据科学杂谈”,公众号后台回复“NER”,即可获取本文所需相关安装文件~
#分析指定数据,返回一个generator
sent = '我 爱 北京 天安门'
sentence = chi_parser.raw_parse(sent)
print(sentence)
for line in sentence:
#需要注意的是line类型为<class 'nltk.tree.Tree'>
print(line)
#画树
line.draw()
#树会弹出来显示

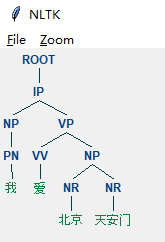
句法分析缩写语含义
ROOT:要处理文本的语句
IP:简单从句
NP:名词短语
VP:动词短语
PU:断句符,通常是句号、问号、感叹号等标点符号
LCP:方位词短语
PP:介词短语
CP:由‘的’构成的表示修饰性关系的短语
DNP:由‘的’构成的表示所属关系的短语
ADVP:副词短语
ADJP:形容词短语
DP:限定词短语
QP:量词短语
NN:常用名词
NR:固有名词
NT:时间名词
PN:代词
VV:动词
VC:是
CC:表示连词
VE:有
VA:表语形容词
AS:内容标记(如:了)
VRD:动补复合词
CD: 表示基数词
DT: determiner 表示限定词
EX: existential there 存在句
FW: foreign word 外来词
IN: preposition or conjunction, subordinating 介词或从属连词
JJ: adjective or numeral, ordinal 形容词或序数词
JJR: adjective, comparative 形容词比较级
JJS: adjective, superlative 形容词最高级
LS: list item marker 列表标识
MD: modal auxiliary 情态助动词
PDT: pre-determiner 前位限定词
POS: genitive marker 所有格标记
PRP: pronoun, personal 人称代词
RB: adverb 副词
RBR: adverb, comparative 副词比较级
RBS: adverb, superlative 副词最高级
RP: particle 小品词
SYM: symbol 符号
TO:”to” as preposition or infinitive marker 作为介词或不定式标记
WDT: WH-determiner WH限定词
WP: WH-pronoun WH代词
WP$: WH-pronoun, possessive WH所有格代词
WRB:Wh-adverb WH副词
我们试试其他的句子:
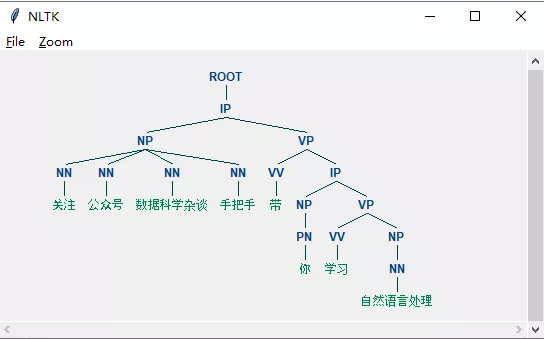
sent = u'关注 公众号 数据科学杂谈 手把手 带 你 学习 自然语言处理'
print(list(chi_parser.parse(sent.split())))
[Tree('ROOT', [Tree('IP', [Tree('NP', [Tree('NN', ['关注']), Tree('NN', ['公众号']), Tree('NN', ['数据科学杂谈']), Tree('NN', ['手把手'])]), Tree('VP', [Tree('VV', ['带']), Tree('IP', [Tree('NP', [Tree('PN', ['你'])]), Tree('VP', [Tree('VV', ['学习']), Tree('NP', [Tree('NN', ['自然语言处理'])])])])])])])]
#分析指定数据,返回一个generator
sentence = chi_parser.raw_parse(sent)
print(sentence)
for line in sentence:
#需要注意的是line类型为<class 'nltk.tree.Tree'>
print(line)
#画树
line.draw()
#树会弹出来显示

接下来我们看看英文的句法结构分析:
#英文句法分析
eng_parser = StanfordParser(r"C:\Users\Dell\Downloads\stanford-parser-full-2018-10-17\stanford-parser.jar",r"C:\Users\Dell\Downloads\stanford-parser-full-2018-10-17\stanford-parser-3.9.2-models.jar")
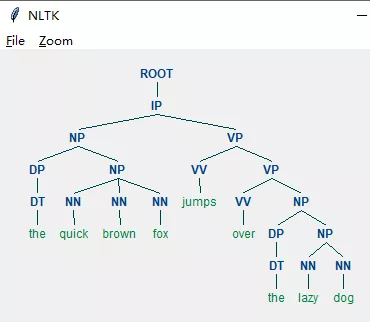
print(list(eng_parser.parse("the quick brown fox jumps over the lazy dog".split())))
[Tree('ROOT', [Tree('NP', [Tree('NP', [Tree('DT', ['the']), Tree('JJ', ['quick']), Tree('JJ', ['brown']), Tree('NN', ['fox'])]), Tree('NP', [Tree('NP', [Tree('NNS', ['jumps'])]), Tree('PP', [Tree('IN', ['over']), Tree('NP', [Tree('DT', ['the']), Tree('JJ', ['lazy']), Tree('NN', ['dog'])])])])])])]
#分析指定数据,返回一个generator
sent = r"the quick brown fox jumps over the lazy dog"
sentence = chi_parser.raw_parse(sent)
print(sentence)
for line in sentence:
#需要注意的是line类型为<class 'nltk.tree.Tree'>
print(line)
#画树
line.draw()
#树会弹出来显示

如果想在线使用,可以:http://nlp.stanford.edu:8080/parser/文末扫码关注公众号“数据科学杂谈”,公众号后台回复“NER”,即可获取本文所需相关安装文件~
关注公众号,手把手带你通俗易懂学习自然语言处理!
扫码下图关注我们不会让你失望!

