前文传送门:
从零开始学自然语言处理(四)—— 做 NLP 任务文本 id 化与预训练词向量初始化方法
词性标注(Part-of-Speech tagging或POS tagging),又称词类标注或简称标注,是指分词结果中的每个单词标注一个正确的词性的程序,也即确定每个词是名词、动词、形容词或其他词性的过程。
在汉语中,词性标注比较简单,因为汉语词汇词性多变的情况比较少见,大多数词语只有一个词性,或者出现频次最高的词性远远高于第二位的词性。只需选取最高频词性,即可实现80%准确率的中文词性标注程序。以jieba为例:
1)Ag 形语素,形容词代码为a,语素代码g前面置以A。
2)a 形容词,取英语形容词adjective的第一个字母。
3)ad 副形词,直接作状语的形容词。形容词代码a和副词代码d并在一起。
4)an,名形词,具有名词功能的形容词,形容词代码a和名词代码n并在一起。
4)v,动词,取英语动词verb的第一个字母。
5)vd,副动词,直接做状语的动词。动词和副动词的代码并在一起。
6)vn,名动词,指具有名词功能的动词。动词和名词的代码并在一起。
7)w,标点符号
8)x,非语素字,非语素字只是一个符号,字母x通常用于代表未知数、符号。
例如:
中文分词是其他中文信息处理的基础。
词性标注的结果是:
中文/n 分词/n 是/v 其他/p 中文/n 信息/n 处理/v 的基础。
使用jieba进行中文词性标注很方便,具体操作如下:
import jieba.posseg as pseg
然后首先分词:
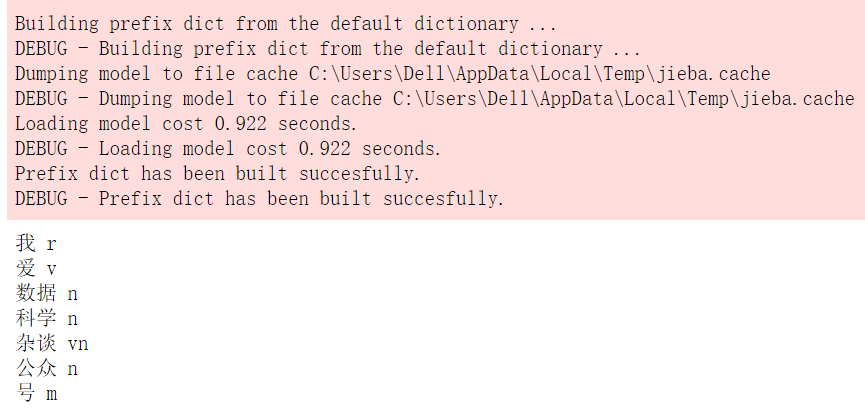
words = pseg.cut("我爱数据科学杂谈公众号")
for w in words:
print(w.word,w.flag)
words = pseg.cut("我爱Shanghai")
for w in words:
print(w.word,w.flag)

Jieba 分词中的词性标注功能与中文分词类似,也是结合规则方法和统计方法的方式,在词性标注的过程中,词典匹配和 HMM 共同作用。词性标注的流程如下:
(1)首先基于正则表达式,进行汉字的判断;
(2)若符合正则表达式,则判断为汉字,然后基于前缀词典构建有向无环图;
(3)再基于有向无环图计算最大概率路径,同时在前缀词典中找出它所分出的词性,若在词典中未找到,则赋予词性为“x”(代表未知)。
(4)若不符合正则表达式,那么将继续通过正则表达式进行类型判断,分别赋予“x”“m”和“eng”(英文),例如上面例子中的 Shanghai 标注结果是 eng 。
如果你在对英文处理的时候,也是按照先分词,再词性标注的流程来,具体操作如下:
首先安装 nltk 库
pip install nltk 即可
然后可以使用以下的代码:
import nltk
document = r"it's easy to learn and use Python."
sentences = nltk.sent_tokenize(document)
for sent in sentences:
print(nltk.pos_tag(nltk.word_tokenize(sent)))
词性标注的结果如下:
[('it', 'PRP'), ("'s", 'VBZ'), ('easy', 'JJ'), ('to', 'TO'), ('learn', 'VB'), ('and', 'CC'), ('use', 'VB'), ('Python', 'NNP'), ('.', '.')]
具体词性可以参考如下:
CC 并列连词 NNS 名词复数 UH 感叹词
CD 基数词 NNP 专有名词 VB 动词原型
DT 限定符 NNP 专有名词复数 VBD 动词过去式
EX 存在词 PDT 前置限定词 VBG 动名词或现在分词
FW 外来词 POS 所有格结尾 VBN 动词过去分词
IN 介词或从属连词 PRP 人称代词 VBP 非第三人称单数的现在时
JJ 形容词 PRP$ 所有格代词 VBZ 第三人称单数的现在时
JJR 比较级的形容词 RB 副词 WDT 以wh开头的限定词
JJS 最高级的形容词 RBR 副词比较级 WP 以wh开头的代词
LS 列表项标记 RBS 副词最高级 WP$ 以wh开头的所有格代词
MD 情态动词 RP 小品词 WRB 以wh开头的副词
NN 名词单数 SYM 符号 TO to
当然,除了jieba和NLTK,还有很多工具可以做词性标注。
扫码下图关注我们不会让你失望!

