
前文传送门:
自从 bert 咔嚓一下子冒出来之后,NLP 似乎进入到了一个新的纪元,不管你做啥 NLP 任务,bert 几乎能秒杀任何自己搭建的模型。现在如果没有使用过 bert,都不好意思说自己是 NLPer。然而对于许多新涉足 NLP 领域的同学来说,想要学习 bert(包括 GPT、XLnet)需要先了解 bert 出现之前的一系列铺垫工作。因此,本公众号将推出系列课程《从 word2vec 到 bert》,在向您介绍相关工作的同时,手把手带你实现一个可以运行的代码。
keras 实现 word2vec 的 CBOW 模型
许多刚刚接触 NLP 的童鞋,难免用深度学习做一些 NLP 相关的任务,而且都不可避免会使用到词向量。最经典的词向量训练模型,应该就是连续词袋模型(continuous bag of words, CBOW)以及跳字模型(Skip-gram)。初学者想要学习 CBOW 和 skip-gram,首选会怎么做?阅读能力较强且英语较好的人,会选择先看论文,不爱看书的(比如小编我自己一看书就困)往往会上网搜索,CSDN、简书、包括知乎上都会有大神进行讲解。看完之后,我们一般会说:“哦~原来是这么回事。” 那我们把实现代码写一下吧。

尼玛,完全不知道该如何下手啊。然而网上的那些教程《一文教你快速理解 word2vec》,几乎千篇一律,换汤不换药。上来给你吹一波 word2vec 是谁谁谁先提出来的,怎么怎么牛逼。然后上来给你摆公式:
哥差的是你的公式吗?
继续往下看,会给你摆一张快看吐了的图。
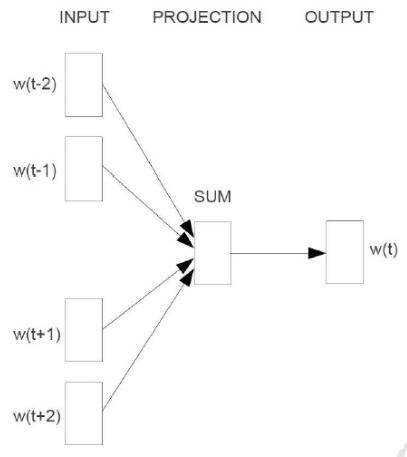
X!老子缺的是你这张图吗?小爷我缺的是代码实现,而且是能让小爷看得懂、跑的通的代码!!
然鹅,功夫不负有心人。

小编终于找到一篇良心软文,给出了 CBOW 模型的 keras 实现,而且代码注释得十分清晰。这篇软文是由苏神在他的个人博客[1]中写的。苏神是一个敢于钻研,爱好广泛的学神级人物。看了他这篇软文,我才终于对 CBOW 模型有了恍然大明白的感觉。下面的代码是我在学习了苏神的代码之后实践的结果。我刚接触深度学习就是使用的 keras,个人感觉 keras 对新手确实十分友好,刚跳深度学习坑的人,可以尝试借助 keras 来进行学习。
上代码!
import os
import jieba
import random
import numpy as np
from keras.layers import Input, Embedding, Lambda
from keras.models import Model
import keras.backend as K
from collections import Counter
首先,设定好超参数:
word_size = 128 #词向量维度
window = 5 #窗口大小
nb_negative = 50 #随机负采样的样本数
min_count = 10 #频数少于min_count的词将会被抛弃,低频词类似于噪声,可以抛弃掉
nb_epoch = 2 #迭代次数
接下来是对语料进行处理,这里我们使用的是搜狗新闻的语料库。你从网上下载下来的搜狗新闻语料,其文件夹结构为
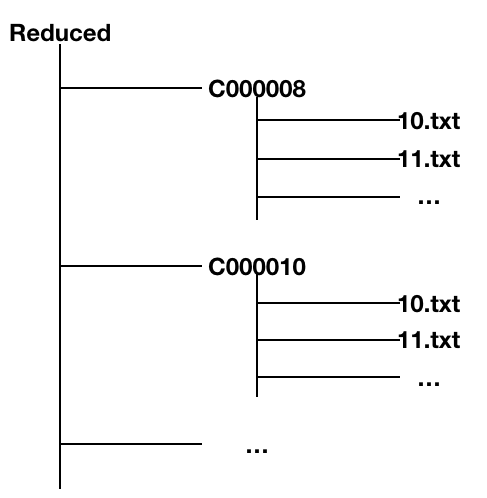
语料存放在多个文件夹下,每个.txt 中都是一条新闻语料,因此我们需要写一个方法能够遍历根目录下的所有文件夹。
def all_path(dirname):
paths = [] #将所有的txt文件路径存放在这个list中
for maindir, subdir, file_name_list in os.walk(dirname):
for filename in file_name_list:
apath = os.path.join(maindir, filename)#合并成一个完整路径
paths.append(apath)
return paths
在这里,我们编写一个 def 来将所有语料读取出来。本例中是以词为单位,因此用到了 jieba 分词。结巴分词的介绍可以查看从零开始学自然语言处理(一)—— jieba 分词
def get_corpus(file_path):
words = [] #词库,不去重
corpus = []
i = 0 #用来控制读入数据的条数
for file in file_path:
if '.txt' in file:
i += 1
try:
with open(file, encoding='gbk') as fr:
for line in fr:
words+=jieba.lcut(line) #jieba分词,将句子切分为一个个词,并添加到词库中
corpus.append(jieba.lcut(line))
except:
pass
if i ==1000: #当读入了1000条语料之后跳出
break
return words, corpus
paths = all_path('../../dbs/SogouC.reduced/Reduced')
words, corpus = get_corpus(paths)
words = dict(Counter(words))
这里使用 Counter 来帮助我们对词频进行了统计,并将其转换为字典形式。例如,若原来 words 中数据为['结巴','结巴','喜欢','我','我','我','我'],经过 Counter()的一顿操作之后,就得到了 Counter({'结巴': 2, '喜欢': 1, '我': 4})。再经过 dict()转换,就将其转换为字典形式。
total = sum(words.values()) #总词频
words = {i:j for i,j in words.items() if j >= min_count} #去掉低频词
id2word = {i+2:j for i,j in enumerate(words)} #id到词语的映射,习惯将0设置为PAD,1设置为UNK
id2word[0] = 'PAD'
id2word[1] = 'UNK'
word2id = {j:i for i,j in id2word.items()} #词语到id的映射
nb_word = len(id2word) #总词数
PAD 的作用通常是将一些句子进行补全。例如有些模型要求输入数据的长度固定,假设要求输入的词的个数为 5,不足 5 个词的句子怎么办呢?这个时候就用到 PAD 了。可以将 PAD 统一补在句子前,也可以统一补在句子后。例如“PAD” “PAD” “我” “喜欢” “C 罗”。
UNK 就是 unknown 的意思。当遇见一些未出现在词库 words 中的词,例如罕见词、人名以及预处理时删掉的低频词等,都可以用 UNK 来替换。学习过 CBOW 的童鞋都知道,CBOW 是用周围词去预测中心词。怎么预测呢?就比如给了一个训练语料“我/出生/在/中国/。”,当给定[“我”,“出生”,“中国”,“。”]时,此时我的训练目标就是要预测“在”这个词的概率要大于其它所有词(即语料库中所有除了“在”的所有词)的概率。但是词库中的词可能会有几十万个,这样训练下去想要收敛就会变得十分困难。因此提出 word2vec 的神人们就想出了一个取巧的方法:我给它要求降低一点,我不要求模型从几十万个词找到那个正确的中心词,我把这个要求降低一点,我只要求模型能从十几个词中找到正确的中心词就可以了。因此就用到了 negtive sampling。原论文中对如何进行负采样有一个概率计算公式,这里我们为了简便,我们使用 random 方法从词库中随机挑选 neg_num 个负样本。
def get_negtive_sample(x, word_range, neg_num):
negs = []
while True:
rand = random.randrange(0, word_range)
if rand not in negs and rand != x:
negs.append(rand)
if len(negs) == neg_num:
return negs
现在开始构造训练数据!
def data_generator(): #训练数据生成器
x,y = [],[]
for sentence in corpus:
sentence = [0]*window + [word2id[w] for w in sentence if w in word2id] + [0]*window
#上面这句代码的意思是,因为我们是通过滑窗的方式来获取训练数据的,那么每一句语料的第一个词和最后一个词
#如何出现在中心位置呢?答案就是给它padding一下,例如“我/喜欢/足球”,两边分别补窗口大小个pad,得到“pad pad 我 喜欢 足球 pad pad”
#那么第一条训练数据的背景词就是['pad', 'pad','喜欢', '足球'],中心词就是'我'
for i in range(window, len(sentence)-window):
x.append(sentence[i-window: i]+sentence[i+1: window+i+1])
y.append([sentence[i]]+get_negtive_sample(sentence[i], nb_word, nb_negative))
x,y = np.array(x),np.array(y)
z = np.zeros((len(x), nb_negative+1))
z[:,0]=1
return x,y,z
x 为背景词训练语料,y 为一个正确的中心词+nb_negative 个负样本,因为我们是将正确的中心词放在 y 的第一位,因此在构造 z 时,把标签 1 放在每条 label 数据的第一位。输出 z[0],可以看到是[1,0,0,...,0],其实大家可以实际操作一下,看看构造出来的 xyz 分别长什么样。
x,y,z = data_generator() #获取训练数据
苏神对多维向量或者叫张量的操作简直信手拈来,苏神经常使用这个 K(keras.backend)对张量进行维度变换、维度提取和张量加减乘除。我这个小白看的是晕头转向,得琢磨半天。但是后来我也没有找到合适的方式来替换这个 K,只能跟着用。下面是具体的网络结构代码。
#苏神对多维向量或者叫张量的操作简直信手拈来,苏神经常使用这个K(keras.backend)对张量进行维度变换、维度提取和张量加减乘除。
#我这个小白看的是晕头转向,得琢磨半天。但是后来我也没有找到合适的方式来替换这个K,只能跟着用。
#第一个输入是周围词
input_words = Input(shape=(window*2,), dtype='int32')
#建立周围词的Embedding层
input_vecs = Embedding(nb_word, word_size, name='word2vec')(input_words)
#CBOW模型,直接将上下文词向量求和
input_vecs_sum = Lambda(lambda x: K.sum(x, axis=1))(input_vecs)
#第二个输入,中心词以及负样本词
samples = Input(shape=(nb_negative+1,), dtype='int32')
#同样的,中心词和负样本词也有一个Emebdding层,其shape为 (?, nb_word, word_size)
softmax_weights = Embedding(nb_word, word_size, name='W')(samples)
softmax_biases = Embedding(nb_word, 1, name='b')(samples)
#将加和得到的词向量与中心词和负样本的词向量分别进行点乘
#注意到使用了K.expand_dims,这是为了将input_vecs_sum的向量推展一维,才能和softmax_weights进行dot
input_vecs_sum_dot_ = Lambda(lambda x: K.batch_dot(x[0], K.expand_dims(x[1],2)))([softmax_weights,input_vecs_sum])
#然后再将input_vecs_sum_dot_与softmax_biases进行相加,相当于 y = wx+b中的b项
#这里又用到了K.reshape,在将向量加和之后,得到的shape是(?, nb_negative+1, 1),需要将其转换为(?, nb_negative+1),才能进行softmax计算nb_negative+1个概率值
add_biases = Lambda(lambda x: K.reshape(x[0]+x[1], shape=(-1, nb_negative+1)))([input_vecs_sum_dot_,softmax_biases])
#这里苏神用了K.softmax,而不是dense(nb_negative+1, activate='softmax')
#这是为什么呢?因为dense是先将上一层的张量先进行全联接,再使用softmax,而向下面这样使用K.softmax,就没有了全联接的过程。
#实验下来,小编尝试使用dense(activate='softmax')训练出来的效果很差。
softmax = Lambda(lambda x: K.softmax(x))(add_biases)
#编译模型
model = Model(inputs=[input_words,samples], outputs=softmax)
#使用categorical_crossentropy多分类交叉熵作损失函数
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.summary()
训练
model.fit([x,y],z, epochs=nb_epoch, batch_size=512)
这里我们没有切分训练集和测试集,小伙伴们可以自己尝试切分验证集。那么如何验证训练的词向量质量好坏呢?我们可以通过计算词语相似度进行验证。
model.save_weights('word2vec.model')
#embedding层的权重永远在模型的第一层
embeddings = model.get_weights()[0]
def most_similar(w):
v = embeddings[word2id[w]]
sims = np.dot(embeddings, v)
sort = sims.argsort()[::-1]
sort = sort[sort > 0]
return [(id2word[i],sims[i]) for i in sort[:10]]
import pandas as pd
pd.Series(most_similar(u'科学'))
结果为
0 (科学, 13.68143)
1 (灿坤, 5.599081)
2 (知情权, 5.578944)
3 (创新, 5.0190754)
4 (在外, 4.942095)
5 (深度, 4.86686)
6 (获取, 4.6781273)
7 (精神, 4.55865)
8 (为例, 4.535615)
9 (筹资, 4.51618)
dtype: object
pd.Series(most_similar(u'女'))
0 (女, 20.131395)
1 (男, 8.825096)
2 (联系电话, 8.602478)
3 (010, 8.465874)
4 (00, 8.302881)
5 (131, 7.862992)
6 (梭织, 7.7005587)
7 (代码, 7.60074)
8 (网址, 7.4306855)
9 (&#, 7.0047092)
dtype: object
苏神写的这个计算词向量相似度的方法,也让我终于恍然大明白了一件事,就是 gensim 里也有 most_similar 方法,我一直在想它是如何在几秒之内就能快速从几十万甚至是几百万的词中,计算出相似度并可以排序输出的?苏神的代码给了启示。显然不是用 for 循环逐个计算的,矩阵乘法对于人来说很复杂,但是对计算机来说就很简单了,通过让 embeding 矩阵与目标词向量进行点乘得到相似值,然后使用 numpy 的内置函数 argsort 进行排序,从而得到索引,这样就可以得到与词相似度有高到低的一个排序。大神还是大神,之前小编搜索过类似的问题,但就是怎么也找不到。下一篇小编将会手把手带你用 keras 实现 skip-gram 模型代码。
BTW,之前一个师兄和我们说,他在面试一家公司的时候,面试官让他只用 numpy 实现 word2vec 算法。怎么样,有难度吧?如果大家对此有需求,请在留言处留言告知,小编也会带大家手把手实现用 numpy 做 word2vec。
参考资料
[1] 个人博客: https://spaces.ac.cn/archives/4515
扫码下图关注我们不会让你失望!
