你的浏览器禁用了JavaScript, 请开启后刷新浏览器获得更好的体验!
假设学习模型是,训练误差是模型关于训练数据集的平均损失:其中N是训练样本的容量训练误差是关于数据集的平均损失:其中
当损失函数是0-1损失时,测试误差就变成了常见的测试数据集上的误差率error rateI是指示函数,即时为1,否则为0;相应的测试集上的准确率为明显的:
error rate
总结
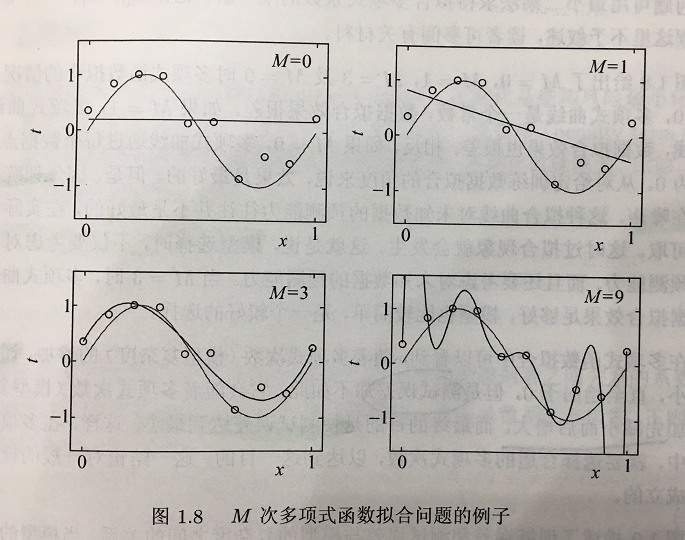
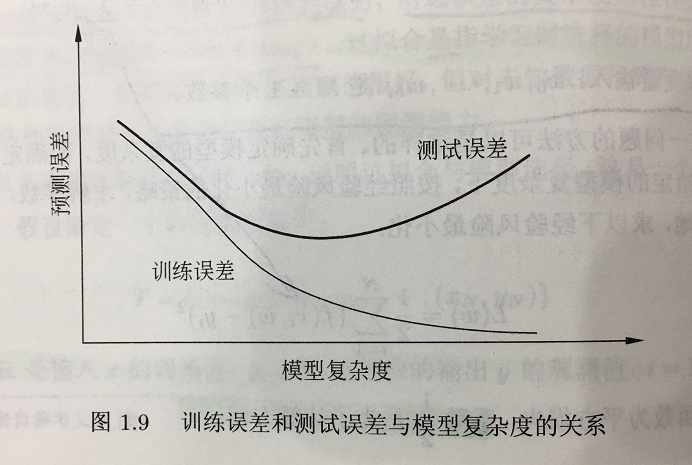
过拟合:一味地追求提高对训练数据的预测能力,所选模型的复杂度会比真实模型高,这种现象称之为过拟合。
过拟合
栗子:对M次多项式进行拟合
解决办法:
正则化和交叉验证
模型选择的典型方法是正则化。正则化是结构风险最小化策略的实现,在经验风险的基础上加上了一个正则项regularrizer或者罚项penalty term。正则化的一般形式
regularrizer
penalty term
正则化作用:选择经验风险和模型复杂度同时较小的模型
普通模型选择方法
进行模型选择的一般做法是指将数据集分成三个部分:
一般做法
training set
validation set
test set
在学习到不同复杂度的模型中,选择对验证集有最小预测误差的模型
简单交叉验证
交叉验证cross validation的做法是数据分成两部分:
cross validation
通过训练集在不同的条件下进行模型的训练,从而得到模型,再把测试集数据放入模型进行评估,选择出测试误差最小的模型
S折交叉验证
S-fold cross validation 的做法是:
S-fold cross validation
S
留一交叉验证
S折交叉验证的特殊情形是S=N,变成留一交叉验证 leave-ont-out cross validation,往往是在数据缺乏的情况下使用
S=N
留一交叉验证 leave-ont-out cross validation
学习方法的泛化能力是指由学习方法得到的模型对未知数据的预测能力,是学习方法重要的性质。通常是采用通过测试误差来评估学习方法的泛化能力。缺陷是
如果学到的模型是,用该模型对未知数据预测的误差称为泛化误差generalization error,通过泛化误差来反映学习的泛化能力:
generalization error
泛化误差就是所学习到的模型的期望风险
泛化能力分析往往是通过研究比较泛化误差的概率上界来实现的,称之为泛化误差上界 generalization error bound。泛化误差两个特质:
generalization error bound
泛化误差上界定理对于二分裂问题,当假设空间是有限个函数的集合,,d是函数的个数,任意的,至少有以概率使得如下式子成立:,其中
要回复文章请先登录或注册