
问题描述:
一家婚恋网站公司希望根据已注册用户的历史相亲数据,建立新用户相亲成功可能性的预测模型,数据存放在“date_data2.csv”中。
1、分析思路:
在对客户流失与否的影响因素进行模型研究之前,首先对各解释变量与被解释变量进行两变量独立性分析,以初步判断影响流失的因素,进而建立客户
流失预测模型
主要变量说明如下:
#income-月均收入(元)
#attractive-由婚恋网站评定出的个人魅力值,分值从0-100。
#assets-资产(万元)
#edueduclass-教育等级:1=小学,2=初中;3=高中,4=本科,5=硕士及以上
#Dated-是否相亲成功:1代表成功
2、作业安排:
2.1 基础知识:
1)比较逻辑回归、决策树、神经网络的算法差异。
2.2 案例解答步骤如下:
1)使用决策树、神经网络建立相亲成功预测模型并通过调节超参数进行模型调优,比较两个模型的优劣。
2)对income,attractive,assets进行分箱(5分箱)处理,用分箱后的数据建模,并比较与1)步骤中模型的表现是否有差异。
1)使用决策树、神经网络建立相亲成功预测模型并通过调节超参数进行模型调优,比较两个模型的优劣。
import pandas as pd
import os
os.chdir(r'D:\Learningfile\天善学院\280_Ben_八大直播八大案例配套课件\提交-第六讲:使用决策树和神经网络预测客户流失倾向\作业')
#%%
data=pd.read_csv('date_data2.csv')
print(data.head())
data.Dated.value_counts()
#%%
import sklearn.model_selection as cross_validation
target = data['Dated'] # 选取目标变量
data2=data.ix[:, 'income':'edueduclass'] # 选取自变量
data2['income']=data2['income']/1000
train_data, test_data, train_target, test_target = cross_validation.train_test_split(data2,target, test_size=0.2, train_size=0.8 ,random_state=12345) # 划分训练集和测试集
# ## CART算法(分类树)
# 建立CART模型
# In[14]:
import sklearn.tree as tree
clf = tree.DecisionTreeClassifier(criterion='entropy', max_depth=5, min_samples_split=2, min_samples_leaf=1, random_state=12345) # 当前支持计算信息增益和GINI
clf.fit(train_data,train_target)
#%%
# 查看模型预测结果
train_est = clf.predict(train_data) # 用模型预测训练集的结果
train_est_p=clf.predict_proba(train_data)[:,1] #用模型预测训练集的概率
test_est=clf.predict(test_data) # 用模型预测测试集的结果
test_est_p=clf.predict_proba(test_data)[:,1] # 用模型预测测试集的概率
pd.DataFrame({'test_target':test_target,'test_est':test_est,'test_est_p':test_est_p}).T # 查看测试集预测结果与真实结果对比
# ## 模型评估
# In[19]:
import sklearn.metrics as metrics
print(metrics.confusion_matrix(test_target, test_est,labels=[0,1])) # 混淆矩阵
print(metrics.classification_report(test_target, test_est)) # 计算评估指标
print(pd.DataFrame(list(zip(data.columns, clf.feature_importances_)))) # 变量重要性指标
# In[20]:
#察看预测值的分布情况
import seaborn as sns
import matplotlib.pyplot as plt
red, blue = sns.color_palette("Set1", 2)
sns.distplot(test_est_p[test_target == 1], kde=False, bins=15, color=red)
sns.distplot(test_est_p[test_target == 0], kde=False, bins=15,color=blue)
plt.show()
# In[21]:
fpr_test, tpr_test, th_test = metrics.roc_curve(test_target, test_est_p)
fpr_train, tpr_train, th_train = metrics.roc_curve(train_target, train_est_p)
plt.figure(figsize=[6,6])
plt.plot(fpr_test, tpr_test, color=blue)
plt.plot(fpr_train, tpr_train, color=red)
plt.title('ROC curve')
plt.show()
print('AUC = %6.4f' %metrics.auc(fpr_test, tpr_test))
预测值的分布情况
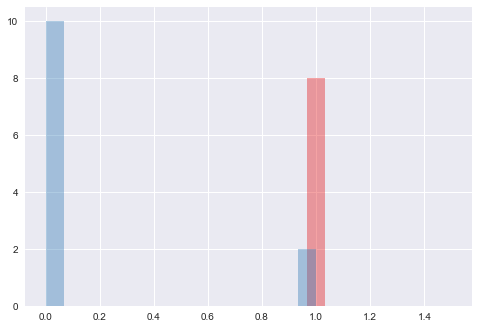
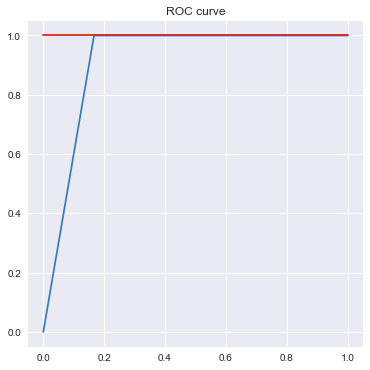
AUC = 0.9167
#%%
#参数调优
from sklearn.model_selection import GridSearchCV
from sklearn import metrics
param_grid = {
'max_depth':[2,3,4,5,6,7,8],
'min_samples_split':[2,4,8,12,16]
}
clf = tree.DecisionTreeClassifier(criterion='entropy')
clfcv = GridSearchCV(estimator=clf, param_grid=param_grid,
scoring='roc_auc', cv=4)
clfcv.fit(train_data, train_target)
#%%
# 查看模型预测结果
train_est = clfcv.predict(train_data) # 用模型预测训练集的结果
train_est_p=clfcv.predict_proba(train_data)[:,1] #用模型预测训练集的概率
test_est=clfcv.predict(test_data) # 用模型预测测试集的结果
test_est_p=clfcv.predict_proba(test_data)[:,1] # 用模型预测测试集的概率
#%%
fpr_test, tpr_test, th_test = metrics.roc_curve(test_target, test_est_p)
fpr_train, tpr_train, th_train = metrics.roc_curve(train_target, train_est_p)
plt.figure(figsize=[6,6])
plt.plot(fpr_test, tpr_test, color=blue)
plt.plot(fpr_train, tpr_train, color=red)
plt.title('ROC curve')
plt.show()
print('AUC = %6.4f' %metrics.auc(fpr_test, tpr_test))
#%%
clfcv.best_params_
#%%
clf = tree.DecisionTreeClassifier(criterion='entropy', max_depth=2, min_samples_split=2) # 当前支持计算信息增益和GINI
clf.fit(train_data, train_target) # 使用训练数据建模
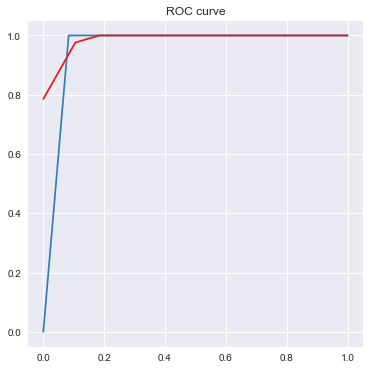
AUC = 0.9583
#%%
#神经网络建模
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaler.fit(train_data)
scaled_train_data = scaler.transform(train_data)
scaled_test_data = scaler.transform(test_data)
# In[5]:
from sklearn.neural_network import MLPClassifier
mlp = MLPClassifier(hidden_layer_sizes=(10,),
activation='logistic', alpha=0.1, max_iter=1000)
mlp.fit(scaled_train_data, train_target)
mlp
# ### 预测
# 预测分类标签
# In[6]:
train_predict = mlp.predict(scaled_train_data)
test_predict = mlp.predict(scaled_test_data)
# 预测概率
# In[7]:
# 计算分别属于各类的概率,取标签为1的概率
train_proba = mlp.predict_proba(scaled_train_data)[:, 1]
test_proba = mlp.predict_proba(scaled_test_data)[:, 1]
# ### 验证
# In[8]:
from sklearn import metrics
print(metrics.confusion_matrix(test_target, test_predict, labels=[0, 1]))
print(metrics.classification_report(test_target, test_predict))
# In[9]:
mlp.score(scaled_test_data, test_target) # Mean accuracy
# In[10]:
fpr_test2, tpr_test2, th_test2 = metrics.roc_curve(test_target, test_proba)
fpr_train2, tpr_train2, th_train2 = metrics.roc_curve(train_target, train_proba)
plt.figure(figsize=[4, 4])
plt.plot(fpr_test2, tpr_test2, '')
plt.plot(fpr_train2, tpr_train2, '')
plt.title('ROC curve')
plt.show()
print('AUC = %6.4f' %metrics.auc(fpr_test2, tpr_test2))
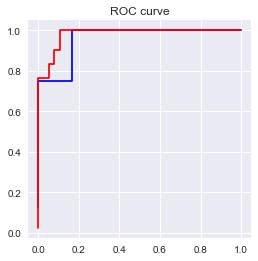
AUC = 0.9583
# In[ ]:
#参数调优
from sklearn.model_selection import GridSearchCV
from sklearn import metrics
param_grid = {
'hidden_layer_sizes':[(10, ), (15, ), (20, ), (5, 5)],
'activation':['logistic', 'tanh', 'relu'],
'alpha':[0.001, 0.01, 0.1, 0.2, 0.4, 1, 10]
}
mlp = MLPClassifier(max_iter=1000)
gcv = GridSearchCV(estimator=mlp, param_grid=param_grid,
scoring='roc_auc', cv=4, n_jobs=-1)
gcv.fit(scaled_train_data, train_target)
# In[ ]:
gcv.best_score_
# In[ ]:
gcv.best_params_
# In[ ]:
gcv.best_estimator_
# In[ ]:
gcv.score(scaled_test_data, test_target) # Mean accuracy
#%%
train_predict = gcv.predict(scaled_train_data)
test_predict = gcv.predict(scaled_test_data)
# 预测概率
# In[7]:
# 计算分别属于各类的概率,取标签为1的概率
train_proba = gcv.predict_proba(scaled_train_data)[:, 1]
test_proba = gcv.predict_proba(scaled_test_data)[:, 1]
# ### 验证
# In[8]:
from sklearn import metrics
print(metrics.confusion_matrix(test_target, test_predict, labels=[0, 1]))
print(metrics.classification_report(test_target, test_predict))
# In[9]:
gcv.score(scaled_test_data, test_target) # Mean accuracy
fpr_test2, tpr_test2, th_test2 = metrics.roc_curve(test_target, test_proba)
fpr_train2, tpr_train2, th_train2 = metrics.roc_curve(train_target, train_proba)
plt.figure(figsize=[4, 4])
plt.plot(fpr_test2, tpr_test2, '')
plt.plot(fpr_train2, tpr_train2, '')
plt.title('ROC curve')
plt.show()
print('AUC = %6.4f' %metrics.auc(fpr_test2, tpr_test2))
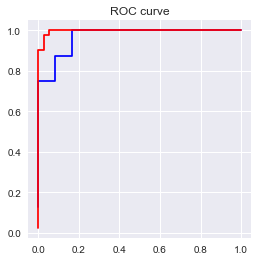
AUC = 0.9688
2)对income,attractive,assets进行分箱(5分箱)处理,用分箱后的数据建模,并比较与1)步骤中模型的表现是否有差异
#%%
train_data['income_bins'] = pd.qcut(train_data.income,5) # 将duration字段切分为数量(大致)相等的5段
train_target.astype('int64').groupby(train_data['income_bins']).agg(['count', 'mean'])
# In[14]:
bins_1 = [2.999, 4.5, 6.5, 9.0, 13.0, 34.0]
train_data['income_bins'] = pd.cut(train_data['income'], bins_1, labels=False)
train_data['income'].astype('int64').groupby(train_data['income_bins']).agg(['mean', 'count'])
#%%
test_data['income_bins'] = pd.cut(test_data['income'], bins_1, labels=False)
test_data['income'].astype('int64').groupby(test_data['income_bins']).agg(['mean', 'count'])
#%%
train_data['attractive_bins'] = pd.qcut(train_data.attractive,5) # 将duration字段切分为数量(大致)相等的5段
train_target.astype('int64').groupby(train_data['attractive_bins']).agg(['count', 'mean'])
# In[14]:
bins_2 = [0.999, 21.0, 39.5, 65.5, 79.0, 99.5]
train_data['attractive_bins'] = pd.cut(train_data['attractive'], bins_2, labels=False)
train_data['attractive'].astype('int64').groupby(train_data['attractive_bins']).agg(['mean', 'count'])
#%%
test_data['attractive_bins'] = pd.cut(test_data['attractive'], bins_2, labels=False)
test_data['attractive'].astype('int64').groupby(test_data['attractive_bins']).agg(['mean', 'count'])
#%%
train_data['assets_bins'] = pd.qcut(train_data.assets,5) # 将duration字段切分为数量(大致)相等的5段
train_target.astype('int64').groupby(train_data['assets_bins']).agg(['count', 'mean'])
# In[14]:
bins_3 = [0, 25.0, 52.6, 94.0, 166.0, 486.0]
train_data['assets_bins'] = pd.cut(train_data['assets'], bins_3, labels=False)
train_data['assets'].astype('int64').groupby(train_data['assets_bins']).agg(['mean', 'count'])
#%%
test_data['assets_bins'] = pd.cut(test_data['assets'], bins_3, labels=False)
test_data['assets'].astype('int64').groupby(test_data['assets_bins']).agg(['mean', 'count'])
#%%
train_data2=train_data.drop(['income','attractive','assets'],axis=1)
test_data2=test_data.drop(['income','attractive','assets'],axis=1)
#%%
from sklearn.model_selection import GridSearchCV
from sklearn import metrics
param_grid = {
'max_depth':[2,3,4,5,6,7,8],
'min_samples_split':[2,4,8,12,16]
}
clf = tree.DecisionTreeClassifier(criterion='entropy')
clfcv = GridSearchCV(estimator=clf, param_grid=param_grid,
scoring='roc_auc', cv=4)
clfcv.fit(train_data2, train_target)
#%%
# 查看模型预测结果
train_est = clfcv.predict(train_data2) # 用模型预测训练集的结果
train_est_p=clfcv.predict_proba(train_data2)[:,1] #用模型预测训练集的概率
test_est=clfcv.predict(test_data2) # 用模型预测测试集的结果
test_est_p=clfcv.predict_proba(test_data2)[:,1] # 用模型预测测试集的概率
#%%
fpr_test, tpr_test, th_test = metrics.roc_curve(test_target, test_est_p)
fpr_train, tpr_train, th_train = metrics.roc_curve(train_target, train_est_p)
plt.figure(figsize=[6,6])
plt.plot(fpr_test, tpr_test, color=blue)
plt.plot(fpr_train, tpr_train, color=red)
plt.title('ROC curve')
plt.show()
print('AUC = %6.4f' %metrics.auc(fpr_test, tpr_test))
#%%
clfcv.best_params_
#%%
clf = tree.DecisionTreeClassifier(criterion='entropy', max_depth=3, min_samples_split=16) # 当前支持计算信息增益和GINI
clf.fit(train_data, train_target) # 使用训练数据建模
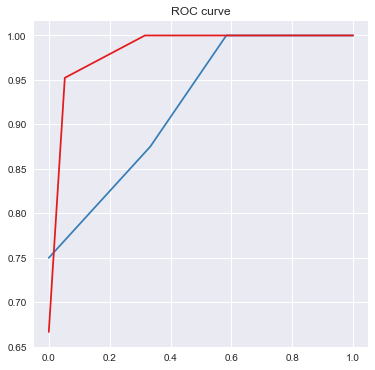
AUC = 0.9219
#%%
#神经网络建模
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaler.fit(train_data2)
scaled_train_data = scaler.transform(train_data2)
scaled_test_data = scaler.transform(test_data2)
# In[5]:
from sklearn.neural_network import MLPClassifier
mlp = MLPClassifier(hidden_layer_sizes=(10,),
activation='logistic', alpha=0.1, max_iter=1000)
mlp.fit(scaled_train_data, train_target)
mlp
# ### 预测
# 预测分类标签
# In[6]:
train_predict = mlp.predict(scaled_train_data)
test_predict = mlp.predict(scaled_test_data)
# 预测概率
# In[7]:
# 计算分别属于各类的概率,取标签为1的概率
train_proba = mlp.predict_proba(scaled_train_data)[:, 1]
test_proba = mlp.predict_proba(scaled_test_data)[:, 1]
# ### 验证
# In[8]:
from sklearn import metrics
print(metrics.confusion_matrix(test_target, test_predict, labels=[0, 1]))
print(metrics.classification_report(test_target, test_predict))
# In[9]:
mlp.score(scaled_test_data, test_target) # Mean accuracy
# In[10]:
fpr_test2, tpr_test2, th_test2 = metrics.roc_curve(test_target, test_proba)
fpr_train2, tpr_train2, th_train2 = metrics.roc_curve(train_target, train_proba)
plt.figure(figsize=[4, 4])
plt.plot(fpr_test2, tpr_test2, '')
plt.plot(fpr_train2, tpr_train2, '')
plt.title('ROC curve')
plt.show()
print('AUC = %6.4f' %metrics.auc(fpr_test2, tpr_test2))
# In[ ]:
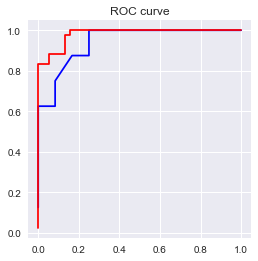
AUC = 0.9427
#参数调优
from sklearn.model_selection import GridSearchCV
from sklearn import metrics
param_grid = {
'hidden_layer_sizes':[(10, ), (15, ), (20, ), (5, 5)],
'activation':['logistic', 'tanh', 'relu'],
'alpha':[0.001, 0.01, 0.1, 0.2, 0.4, 1, 10]
}
mlp = MLPClassifier(max_iter=1000)
gcv = GridSearchCV(estimator=mlp, param_grid=param_grid,
scoring='roc_auc', cv=4, n_jobs=-1)
gcv.fit(scaled_train_data, train_target)
# In[ ]:
gcv.best_score_
# In[ ]:
gcv.best_params_
# In[ ]:
gcv.best_estimator_
# In[ ]:
gcv.score(scaled_test_data, test_target) # Mean accuracy
#%%
train_predict = gcv.predict(scaled_train_data)
test_predict = gcv.predict(scaled_test_data)
# 预测概率
# In[7]:
# 计算分别属于各类的概率,取标签为1的概率
train_proba = gcv.predict_proba(scaled_train_data)[:, 1]
test_proba = gcv.predict_proba(scaled_test_data)[:, 1]
# ### 验证
# In[8]:
from sklearn import metrics
print(metrics.confusion_matrix(test_target, test_predict, labels=[0, 1]))
print(metrics.classification_report(test_target, test_predict))
# In[9]:
gcv.score(scaled_test_data, test_target) # Mean accuracy
fpr_test2, tpr_test2, th_test2 = metrics.roc_curve(test_target, test_proba)
fpr_train2, tpr_train2, th_train2 = metrics.roc_curve(train_target, train_proba)
plt.figure(figsize=[4, 4])
plt.plot(fpr_test2, tpr_test2, '')
plt.plot(fpr_train2, tpr_train2, '')
plt.title('ROC curve')
plt.show()
print('AUC = %6.4f' %metrics.auc(fpr_test2, tpr_test2))
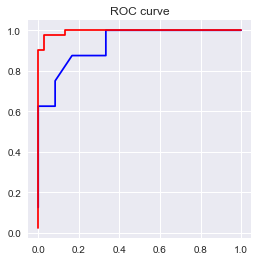
AUC = 0.9323
本站文章版权归原作者及原出处所有 。内容为作者个人观点, 并不代表本站赞同其观点和对其真实性负责。本站是一个个人学习交流的平台,并不用于任何商业目的,如果有任何问题,请及时联系我们,我们将根据著作权人的要求,立即更正或者删除有关内容。本站拥有对此声明的最终解释权。