

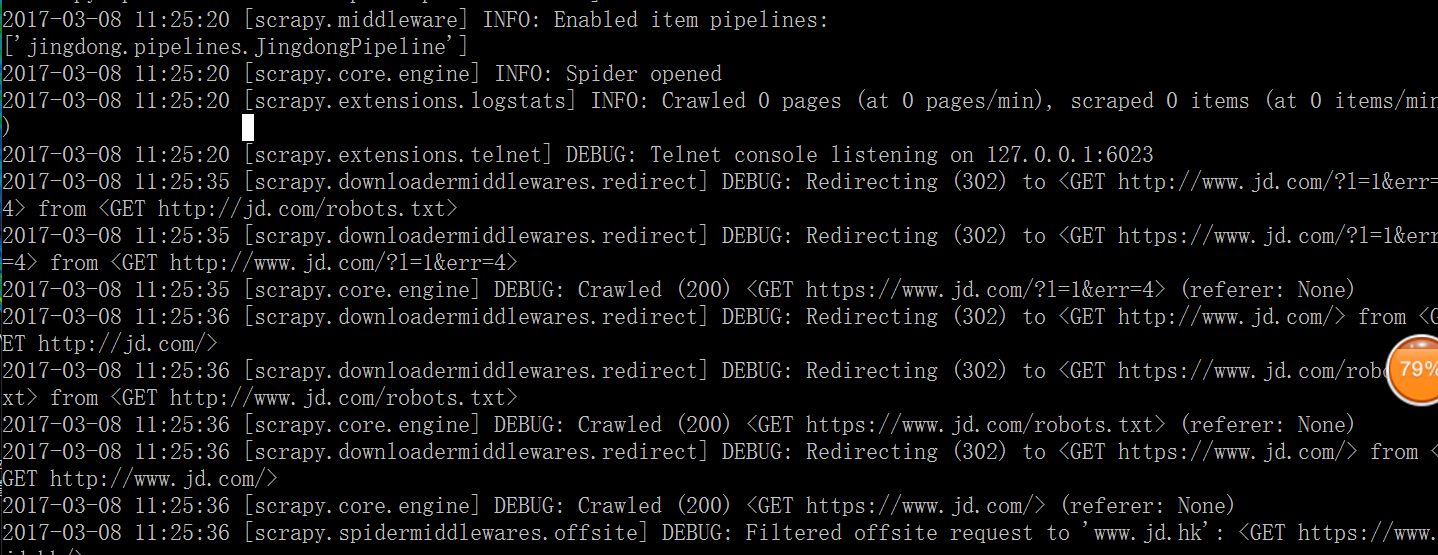
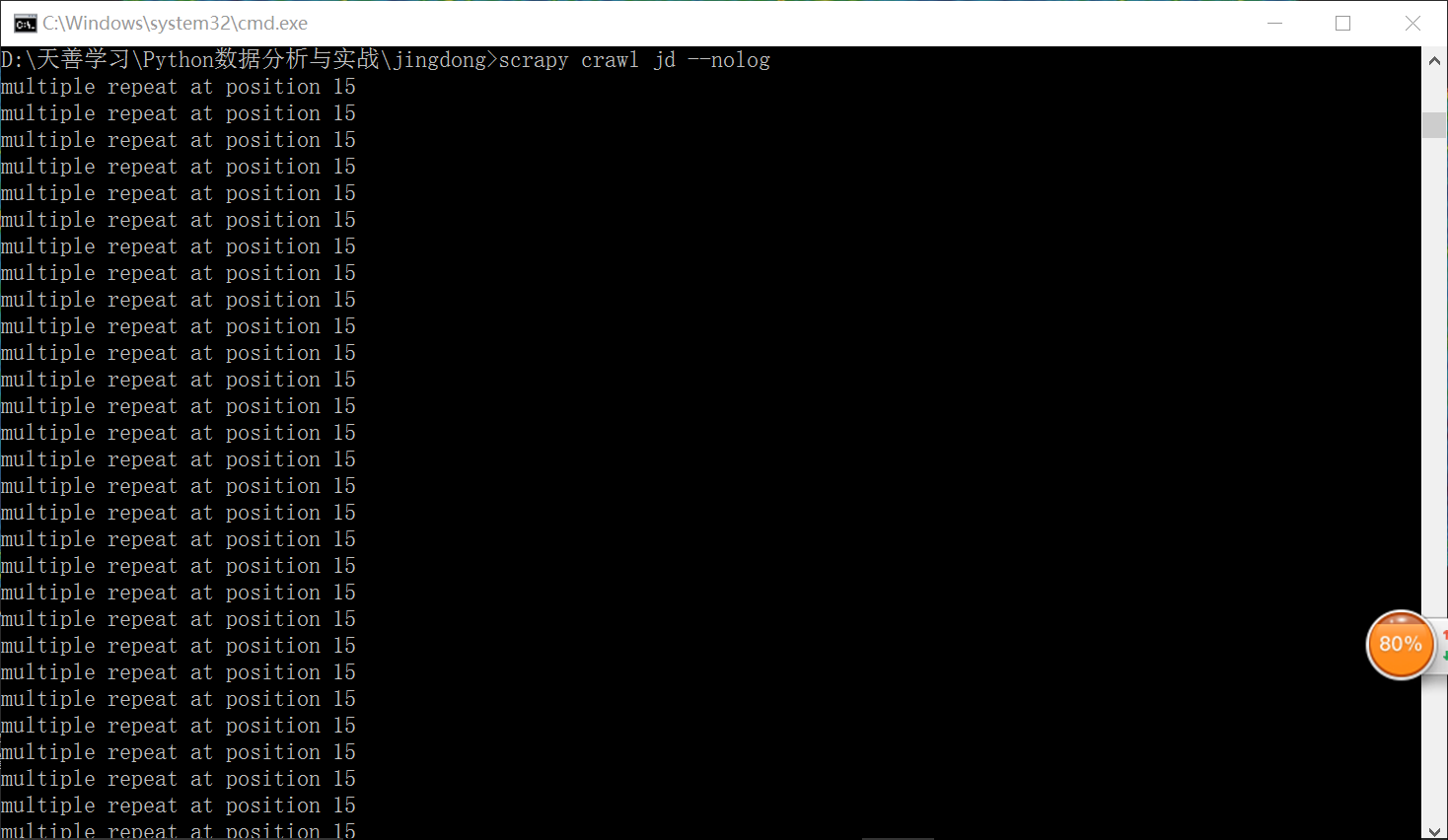
scrapy一直出现302
0
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from scrapy import Request
from jingdong.items import JingdongItem
import re
import urllib.request
class JdSpider(CrawlSpider):
name = 'jd'
headers={"User-Agent","Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.8 Safari/537.36"}
allowed_domains = ['jd.com']
start_urls = ['http://jd.com/']
def start_requests(self):
for url in self.start_urls:
yield Request(url, cookies={'jd.com': 'False'})
rules = (
Rule(LinkExtractor(allow=''), callback='parse_item', follow=True),
)
def parse_item(self, response):
try:
i = JingdongItem()
thisurl=response.url
pat="item.jd.com/(.?*).html"
x=re.search(pat,thisurl)
if(x):
thisid=compile(x).findall(thisurl)[0]
title = response.xpath("//li[@class='img-hover']/img/@alt").extract()
shop = response.xpath("//div[@class='name']/a[@target='_blank']/text()").extract()
shopurl = response.xpath("//div[@class='name'']/a/@href").extract()
print(title)
print(shop)
print(shopurl)
priceurl="https://p.3.cn/prices/mgets%3F ... hisid
commenturl="https://club.jd.com/comment/pr ... ot%3B
pricedata=urllib.request.urlopen(priceurl).read().decode("utf-8","ignore")
commentdata=urllib.request.urlopen(commenturl).read().decode("urf-8","ignore")
pricepat='"p":"(.?*)"'
commentpat='"goodRateShow":(.?*),"'
price=compile(pricedata).findall(pricepat)[0]
comment=compile(commentdata).findall(commentpat)[0]
if(len(title) and len(shop) and len(shopurl) and len(price) and len(comment)):
print(title[0])
print(shop[0])
print(shopurl[0])
print(price[0])
price(comment[0])
print("------------")
else:
pass
return i
except Exception as e:
print(e)
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from scrapy import Request
from jingdong.items import JingdongItem
import re
import urllib.request
class JdSpider(CrawlSpider):
name = 'jd'
headers={"User-Agent","Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.8 Safari/537.36"}
allowed_domains = ['jd.com']
start_urls = ['http://jd.com/']
def start_requests(self):
for url in self.start_urls:
yield Request(url, cookies={'jd.com': 'False'})
rules = (
Rule(LinkExtractor(allow=''), callback='parse_item', follow=True),
)
def parse_item(self, response):
try:
i = JingdongItem()
thisurl=response.url
pat="item.jd.com/(.?*).html"
x=re.search(pat,thisurl)
if(x):
thisid=compile(x).findall(thisurl)[0]
title = response.xpath("//li[@class='img-hover']/img/@alt").extract()
shop = response.xpath("//div[@class='name']/a[@target='_blank']/text()").extract()
shopurl = response.xpath("//div[@class='name'']/a/@href").extract()
print(title)
print(shop)
print(shopurl)
priceurl="https://p.3.cn/prices/mgets%3F ... hisid
commenturl="https://club.jd.com/comment/pr ... ot%3B
pricedata=urllib.request.urlopen(priceurl).read().decode("utf-8","ignore")
commentdata=urllib.request.urlopen(commenturl).read().decode("urf-8","ignore")
pricepat='"p":"(.?*)"'
commentpat='"goodRateShow":(.?*),"'
price=compile(pricedata).findall(pricepat)[0]
comment=compile(commentdata).findall(commentpat)[0]
if(len(title) and len(shop) and len(shopurl) and len(price) and len(comment)):
print(title[0])
print(shop[0])
print(shopurl[0])
print(price[0])
price(comment[0])
print("------------")
else:
pass
return i
except Exception as e:
print(e)
没有找到相关结果
重要提示:提问者不能发表回复,可以通过评论与回答者沟通,沟通后可以通过编辑功能完善问题描述,以便后续其他人能够更容易理解问题.

0 个回复