
本文作者:数据取经团 - JQstyle
本期给大家带来一些启发式算法的介绍和代码实现。严格来说,启发式算法并不属于机器学习领域的方法,其解决的问题也并不是分类和回归预测,因此本篇属于该系列番外篇。
启发式算法简介
在数学建模的经典问题当中,有一种问题是最优化问题,即在给定条件下,给出能够是的目标实现最优的答案的方法。对预测类问题,如果要确保找出最优的解,那么可能需要遍历尝试所有可能的选择,在绝大多数场景下,面对指数增长的搜索空间,几乎是不可取的。
在这种背景下,启发式算法应运而生,其目标在于,在有限的时间和资源下(可接受的范围内),寻找出能够解决问题的可行解,可行解和通常不是全局最优解,但可能是一个较为优秀的局部最优解。启发式算法主要是基于直观和经验来构造,目前主要的几种方法,如遗传算法、模拟退火、蚁群算法等,都是基于仿生学而发明的。
本期所要介绍的两种启发式算法,分别是遗传算法(GA)和模拟退火算法(SA)。
遗传算法的原理
基本原理
遗传算法是仿照进化论“物竞天择,适者生存”的理论来构造的。其基本思想是,每一代种群(候选解集合)中,根据对目标的适应程度(目标函数值),适应性强的个体能够生存繁衍下去,通过这些个体之间交叉和变异,产生了下一代种群,通过若干代的进化,最后得到的种群的个体已经是对目标适应性够强的解。
下面给出遗传算法的流程:
(1)随机产生初始包含N个解的种群;
(2)目标函数f评估当前种群的适应度,并且选择适应度强的种群;
(3)交叉运算:将这些种群彼此之间进行部分染色体(解的随机某部分)进行交换,产生下一代种群;
(4)变异运算:对其中部分个体染色体某部分进行变异;
(5)终止条件之前(迭代次数,目标等),进行2-4步进行迭代。
基本性质
遗传算法是搜索算法的一种,每一次迭代产生的是一组解而非单个解,覆盖的空间较大,不容易陷入局部解,且容易进行并行化优化运算;在运算流程中,其不需要搜索空间的其他信息,只需要依靠适应性函数来评价,不受连续可微的影响,算法适用面较广;此外,遗传算法还具有自组织、自适应和自学习性等特点。但是该算法有时在局部搜索效率较低,难以收敛。
模拟退火算法的原理
算法原理
模拟退火算法源于物理上固体退火的原理,借鉴热力学的思想,将搜索空间内的点视为一个分子,分子的能量就是其本身运动的动能(目标函数),在退火过程的初期,由于温度较高,分子运动的随机性很大,即使是一个不正确的方向,也有较大的可能发生运动,随着温度下降以后,分子的运动会不断趋于正确的方向(向错误的方向运动的概率会越来越低)。最后,退火完成,分子停止运动,得到一个较好的解。
模拟退火的标准算法流程如下:
(1)初始温度t=t0,当前分子在一个随机的初始解X0;
(2)在退火过程中,在温度t一次下降,随机产生一个新的解Xn+1(通常由当前解经过简单变换而来);
(3)计算Xn和Xn+1在目标函数f的差值,若f(Xn+1)优于f(Xn),则当前分子直接运动到Xn+1作为下一轮的位置;否则,就以一个概率exp(-|(Xn+1)-f(Xn)|/t)来选择Xn+1作为下一轮的位置;
(4)对2-3步进行迭代,直到满足停止条件(温度t降到一个阈值t1);
基本性质
模拟退火算法思想简单,在局部搜索过程中表现较好,运行效率较高。但是容易陷入局部最优,且受参数影响明显。
类TSP问题的实践
这次对算法时间的场景是一种经典的优化问题——旅行商问题(TSP)。假设有一个旅行商人要拜访n个城市,从一座指定的城市出发,而终点也被指定(通常回到起点)。他必须选择所要走的路径,路径的限制是每个城市必须拜访且只能拜访一次。如何去选择一条最短的路径。
当情况较为复杂时,该问题已经被证实是基本难以取得全局最优的解,因此可以用启发式算法来求解一个相对不错的结果。接下来本文将用python来实现这个流程。
准备工作
首先我们随即在二维空间中产生30个点,规定第一个点(1号点)为起点,最后一个点(29号点)为终点。
import numpy as npimport randomimport copyimport matplotlib.pyplot as plt
np.random.seed(20)
all_points = np.random.randint(0,100,(30,2))
#all_points_num = np.array(range(30))接下来,计算任何两个点之间的距离矩阵:
#距离函数
def dist_calc(points):
dist_mat = np.zeros((points.shape[0],points.shape[0]))
for i in range(points.shape[0]):
for j in range(points.shape[0]):
dist_mat[i,j] = np.sqrt(np.sum((points[i,:]-points[j,:])**2))
return dist_mat#示例距离矩阵
exam_mat = dist_calc(all_points)遗传算法的尝试
首先定义遗传算法类,需要传入参数包括了距离矩阵、起点号、终点号。另外,可选参数包含了:传入点的位置(用于绘图)、迭代次数、每一次迭代的种群样本数、用于交换的优质样本比例、种群中发生变异的比例、每一次直接可进入下一代的最优样本比例。
#定义遗传算法类
class gen_alg(object):
#传入参数
def __init__(self,dist_mat,start_point,end_point,points=None,init_time=100,
pop_num=100,p_cros=0.5,p_vari=0.1,p_best=0.1):
self.dist_mat = dist_mat
self.start_point = start_point
self.end_point = end_point
self.init_time = init_time
self.pop_num = pop_num
self.p_cros = p_cros
self.p_vari = p_vari
self.p_best = p_best
self.points = points下一步,定义目标函数,目标函数的定义是依据当前解的路径顺序依次将上一个点和下一个点的距离进行相加得到:
#目标函数定义(以欧氏距离和为准)
def aim_func(self,order):
aim = 0
for i in range(len(order)-1):
aim += self.dist_mat[order[i],order[i+1]] #print aim
return aim定义随机产生样本的函数,先定义随机生成一条路径的函数,在定义生成一个种群的函数,后者将调用前者来进行:
#随机生成单个顺序
def rand_order(self):
start = self.start_point
end = self.end_point
org_order = range(self.dist_mat.shape[0])
org_order.remove(start)
org_order.remove(end)
random.shuffle(org_order)
new_order = [start] + org_order + [end]
return new_order #随机生成的种群样本
def get_org_population(self,pop_num):
pop_init = []
for i in range(pop_num):
pop_init.append(self.rand_order())
return pop_init然后,我们要定义遗传算法中两个关键步骤,交叉和变异。交叉函数每一次传入两个解,该函数会随机选择两个解上的一些位置进行交换操作(注意:一个序列上,某位置的上a变成b需要同时将等于b的位置变成a才能完成一次变化)。而变异函数则会将传入解的某些位置上进行变换。
#两个个体交叉函数
def cross_func(self,order1,order2):
order1 = copy.copy(order1)
order2 = copy.copy(order2)
order1.remove(self.start_point)
order1.remove(self.end_point)
order2.remove(self.start_point)
order2.remove(self.end_point)
num_cros = random.randint(1,(len(order1)-1))
sel_cros = random.sample(range(len(order1)),num_cros)
order1_cp,order2_cp = copy.copy(order1),copy.copy(order2)
for i in sel_cros:
order1_cp[i] = order2[i]
order1_cp[order1.index(order2[i])] = order1[i]
order2_cp[i] = order1[i]
order2_cp[order2.index(order1[i])] = order2[i]
order1 = copy.copy(order1_cp)
order2 = copy.copy(order2_cp)
return [self.start_point]+order1_cp+[self.end_point],[self.start_point]+order2_cp+[self.end_point]
#变异函数
def vari_func(self,order):
num_vari = random.randint(1,(len(order)/2))
sel_vari = random.sample(order[1:(len(order)-1)],num_vari)
order_cp = copy.copy(order)
for i in sel_vari:
value_tmp = random.sample(order[1:(len(order)-1)],1)[0]
order_cp[i] = value_tmp
order_cp[order.index(value_tmp)] = order[i]
order = copy.copy(order_cp)
return order_cp最后,是遗传算法主函数的定义,主函数包括了遗传算法流程的的初始化种群、适应性函数评估、交叉、变异等过程。在编写过程中笔者定义每一次迭代都会有一些比例的最优个体直接进入下一代,以保留当前的最优解,而最优解和交叉产生样本以外,也会产生部分随机解来作为下一代,这样避免局部收敛,为跳出局部提供可能。算法每迭代10次,都会打印当前的最优解的适应性结果,并且输出当前的最优路径(在传入点的位置的情况下)。
#训练主函数
def gen_alg(self):
#初始化:产生初代群落样本
init_pop = self.get_org_population(self.pop_num)
for i in range(self.init_time):
#按目标值排序
aims_tmp = [self.aim_func(o) for o in init_pop]
index_aims = range(len(aims_tmp))
index_aims.sort(key=lambda i: aims_tmp[i])
print "for the init %s, the best aim value is %s" % (i,aims_tmp[index_aims[0]])
#分别抽取用于交叉的优秀样本和可以直接进入下一代的最有样本群落
good_pop = [init_pop[j] for j in index_aims[:int(self.pop_num*self.p_cros)]]
best_pop = good_pop[:int(self.pop_num*self.p_best)]
#绘图
if (i+1)%10 == 0:
if self.points is not None:
plt.plot(self.points[best_pop[0],0], self.points[best_pop[0],1],
marker='o', mec='r', mfc='w')
plt.show()
#判断迭代次数是否结束
if i == self.init_time-1:
print "Finally the best aim value is %s" % aims_tmp[index_aims[0]]
print "And the best order is: "
print best_pop[0]
self.best_pop = best_pop[0]
return best_pop[0]
#交叉过程
random.shuffle(good_pop)
cros_pop = [0]*len(good_pop)
#print len(cros_pop)
for l in range(0,len(good_pop),2):
cros_tmp = self.cross_func(good_pop[l],good_pop[l+1])
cros_pop[l] = cros_tmp[0]
cros_pop[l+1] = cros_tmp[1]
#交叉和最优继承的样本以外再增加一些随机样本,作为下一代群落
init_pop = init_pop+cros_pop+best_pop
vari_idx = random.sample(range(len(init_pop)),int(self.pop_num*self.p_vari))
for m in vari_idx:
init_pop[m] = self.vari_func(init_pop[m])
#变异过程
init_pop = init_pop + self.get_org_population(self.pop_num-int(self.pop_num*self.p_cros)-int(self.pop_num*self.p_best))我们使用定义好的遗传算法来求解30个点的TSP最优路径。定义迭代200次,每一代种群包含3000个个体,交叉保留样本是60%,10%的最优样本继承,10%的变异比例。
a = gen_alg(exam_mat,0,29,points=all_points,pop_num=3000,init_time=200,p_cros=0.6,
p_vari=0.1,p_best=0.1)
a.gen_alg()从30次到200次迭代的结果来看,遗传算法在30个点的TSP规划中还是取得了不错的结果,很大程度上规避了路径交叉的情况。但是从局部来看,当前的结果仍有进一步优化的空间。通过对参数的调整(如增加迭代次数或者种群数量等),可能会取得更好的结果。另外,并行化还可以进一步增加遗传算法的执行效率。

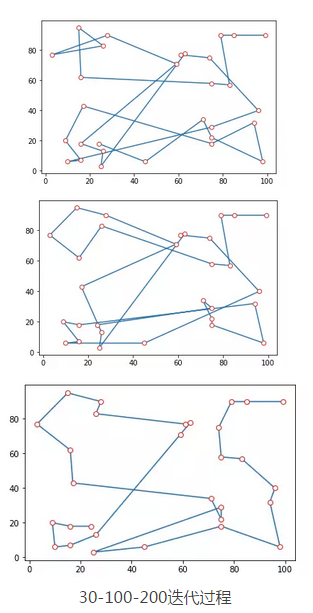
30-100-200迭代过程
模拟退火算法的尝试
下面,我们将尝试用模拟退火算法来求解这个问题。同样的,首先模拟退火算法类,传入的参数和之前相同。模型设定的参数包括了初始温度t0、最终降温阈值t1、降温乘子alpha、双交换操作概率值)
class Sim_Ann(object):
#传入参数
def __init__(self,dist_mat,start_point,end_point,points=None,t0=100,t1=1,
alpha=0.99,p_two_exchange=0.5):
self.dist_mat = dist_mat
self.start_point = start_point
self.end_point = end_point
self.points = points
self.t0 = t0
self.t1 = t1
self.alpha = alpha
self.P_two_exchange = p_two_exchange在类定义中,同样也包括了目标值计算函数aim_func和随机产生样本的函数rand_order(与先前完全相同)。接下来定义模拟退火流程中根据当前解产生新解的变换函数,在此定义两类变换,即双交换函数和三交换函数,分别是将传入的当前解的随机2/3部分的数字进行彼此交换。在后面的主函数中,每一次迭代只会选择两个函数之一来执行产生新解。
#双交换函数
def two_exchange(self,order):
while True:
loc1 = np.random.randint(1,len(order)-1)
loc2 = np.random.randint(1,len(order)-1)
if loc1 != loc2:
break
order_new = copy.copy(order)
order_new[loc1],order_new[loc2] = order_new[loc2],order_new[loc1]
return order_new
#三交换函数
def three_exchange(self,order):
while True:
loc1 = np.random.randint(1,len(order)-1)
loc2 = np.random.randint(1,len(order)-1)
loc3 = np.random.randint(1,len(order)-1)
if loc1 != loc2 and loc1 != loc3 and loc2 != loc3:
break
order_new = copy.copy(order)
order_new[loc1],order_new[loc2],order_new[loc3] = order_new[loc2],order_new[loc3],order_new[loc1] return order_new最后定义的是模拟退火执行的主函数。该函数包括了算法流程中的初始化,降温,选择变化方式产生新解,目标函数对比和下一步解的选择等。每次降温由当前温度t乘以降温算子实现,定义每经过1000次降温,会输出当前温度解的适应性函数结果,并画图。
#训练主函数
def Sim_Ann_fit(self):
t = self.t0
order_init = self.rand_order()
l=0
while t >= self.t1:
if random.random() <= self.P_two_exchange:
order_new = self.two_exchange(order_init)
else:
order_new = self.three_exchange(order_init)
aim_new = self.aim_func(order_new)
aim_old = self.aim_func(order_init)
if aim_new < aim_old:
order_init = order_new
else:
if np.exp(-(aim_new-aim_old)/float(t)) > random.random():
order_init = order_new
if l%1000 == 0:
print 'Now the temperature is ' + str(t)
print 'And the aim value is: ' + str(self.aim_func(order_init))
if self.points is not None:
plt.plot(self.points[order_init,0], self.points[order_init,1],
marker='o', mec='r', mfc='w')
plt.show()
t = t*self.alpha
l += 1
self.final_order = order_init
print 'Finally the Order is: '
print self.final_order
print 'And the aim value is: ' + str(self.aim_func(order_init))
plt.plot(self.points[order_init,0], self.points[order_init,1],
marker='o', mec='r', mfc='w')
plt.show()
return order_init运用模拟退火算法求解TSP问题,我们设定初始温度为t0为10000,降温乘子为0.9999,每次迭代中,双交换和三交换变换等概率发生。
b = Sim_Ann(exam_mat,0,29,points=all_points,t0=10000,alpha=0.9999)
b.Sim_Ann_fit()从执行过程来看,模拟退火算法在温度较高时迭代收敛较慢,由于分子的不稳定性,每次迭代都有较大概率可能运动到目标更差的位置,而随着温度降低以后,分子运动则更为明确,收敛速度加快。事实上我们可以看出,模拟退火在30个点的TSP问题的求解上取得了相当完美的结果。
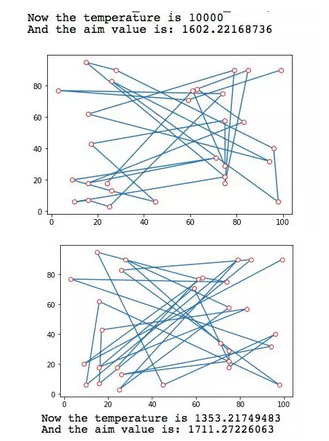
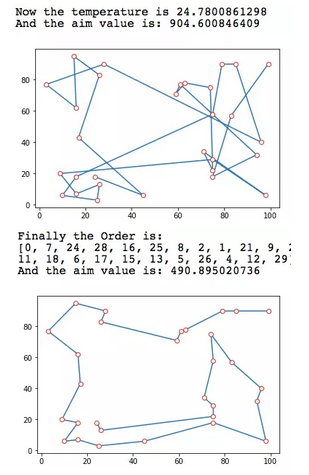
初始-1353度-24度-最终 迭代流程
然而,值得一提的是,尽管在本次示例中,模拟退火算法无论是在求解结果还是在执行效率上相比于遗传算法更具有竞争力,但是并不能因此判断其一定优于遗传算法。在一些更为复杂的场景下,遗传算法可能会表现地相对更为有效。
系列相关:
本文代码及数据获取方式:下图扫码关注公众号,在公众号中回复 旅行商问题 即可~
联系作者:当你对文章有任何疑问和建议可以在公众号直接发消息,我们看到都会回复哒,一起交流数据~
