近期展现表里的数据,初始使用Hive连接数据,发现速度太慢了,因此把Hive数据上传到es,提高了速度,以下列出一系列对es的操作
1.建立索引
from elasticsearch import Elasticsearch
es = Elasticsearch('192.168.12.131:9200')
mappings = { "mappings": { "type_doc_test": {
"properties": {
"id": { "type": "text", "index":True },
"saledate": { "type": "text", "index": "false"},
"vipid": { "type": "text", "index":True },
"nickname": { "type": "text", "index": "false"},
"SaleNO": { "type": "text", "index":"false" },
"ProdUID": { "type": "text", "index": "false"},
"ItemNo": { "type": "text", "index":"false" },
"Name": { "type": "text", "index": "false"}} } } }
res = es.indices.create(index = 'crm_vip_product_info',body =mappings) # 建立索引 crm_vip_product_info
2.插入数据
from impala.dbapi import connect
conn = connect(host='192.168.12.67', port=10000, auth_mechanism='PLAIN', user='root', database='recommend')
cur=conn.cursor()
sql="select * from crm_vip_product_info"
cur.execute(sql)
data_product=cur.fetchall()
conn.close()
#crm_vip_product_info插入数据到es
import pandas as pd
from elasticsearch import helpers
data_product=pd.DataFrame(data_product)
data_product.columns=['id','saledate','vipid','NickName','saleno','produid','ItemNo','Name']
data_product['id']=data_product['id'].astype(str)
data_product['vipid']=data_product['vipid'].astype(str)
action=[]
for i in range(len(data_product)):
action.append(
{"_index": "crm_vip_product_info",
"_type": "type_doc_test",
"_id":data_product.iloc[i]['id']+str(i),
"_source":data_product.iloc[i].to_json()})
helpers.bulk(es, action)
3.读取数据
from elasticsearch import Elasticsearch
es = Elasticsearch('192.168.12.131:9200')
res=es.search(index="crm_vip_product_info", body={'query': {'match': {'vipid':'%s'%('2106411')}}})
#res=es.search(index="crm_vip_product_info", body={ "query": {"function_score": {"query": { "match_all": {} },"random_score": {}}} ,"size": 30}) #随机排序,且定义取得数据大小
res['hits']['hits']
或
from pandasticsearch import DataFrame
df = DataFrame.from_es(url='http://192.168.12.131:9200', index='crm_vip_product_info')
df.print_schema() #数据结构
df.collect()
另外linux读取docs数量
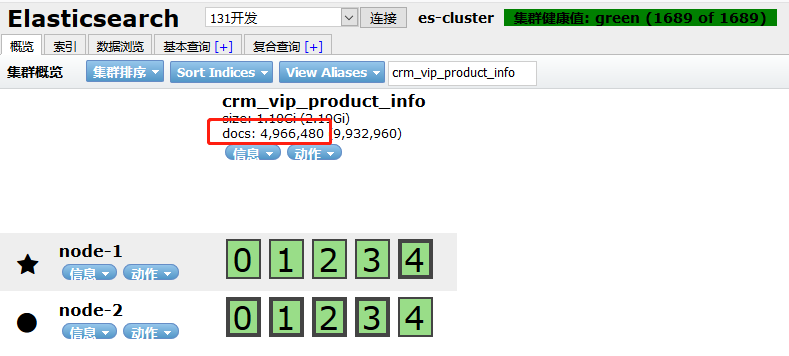
$curl -X get http://192.168.12.131:9200/_cat/indices/crm_vip_product_info?pretty
修改最大读取es数据量
$curl -XPUT http://192.168.12.131:9200/crm_vip_product_info/_settings -d '{ "index" : { "max_result_window" : 5000000}}'
4.删除数据
from elasticsearch import Elasticsearch
es = Elasticsearch('192.168.12.131:9200')
body = { "query": { "match_all": {}} } #删除全部数据
#body = { "query": { "match": {'vipid':'100000085'}} } #删除部分数据
es.delete_by_query(index="crm_vip_product_info",body=body)
5.删除文档
from elasticsearch import Elasticsearch
es = Elasticsearch('192.168.12.131:9200')
es.indices.delete(index="crm_vip_product_info")
