虚拟机直接网上下载后,按照流程一键安装就行,这个比较简单就不多叙述
一、安装linux系统
1.1
安装好虚拟机后,直接去官网下载CentOS7,链接http://mirrors.shu.edu.cn/centos/7/isos/x86_64/CentOS-7-x86_64-Everything-1804.iso
在虚拟机上按照安装引导一步步确认(内存设置依据自己实际内存多大调整),网络选择桥接方式,软件选择>gnome桌面
也可以参考网上资料:https://jingyan.baidu.com/article/a3f121e4b18b74fc9052bb14.html
1.2
安装好系统后,桌面没有终端图标,直接去路径/usr/share/applications,找到图标copy到桌面
网络没有网,在终端输入ifconfig没有ip显示,这时候可能是网络未打开,直接在右上角找到多电脑的图标Wired Connected>Connect(火狐浏览器默认用Google搜索)
二、安装python3.6
在根目录建个python文件夹,存放下载的python3.6文件
$cd / &&sudo mkdir python #如果要删除文件夹的话 $sudo rm -rf /python
$cd python
$sudo wget https://www.python.org/ftp/python/3.6.5/Python-3.6.5.tar.xz #下载文件
$sudo xz -d Python-3.6.5.tar.xz
$sudo tar -xf Python-3.6.5.tar
$yum -y groupinstall development #确保CentOS 7系统安装好所需要的依赖
$yum -y install zlib-devel
$./configure
$make && sudo make install
$cd / &&sudo chown -R chris:users python #修改文件权限,免得老是要sudo,命令中chris是用户名
$cd /python/Python-3.6.5/
$python3 #能够运行就表示成功
另外在系统中添加环境变量,这样以后直接输入python就可以运行
$vi ~/.bashrc #打开bashrc文件
#添加环境变量 export PATH=$PATH:/python/Python-3.6.5
$source ~/.bashrc
在linux根目录输入python能够运行表示安装成功,参考资料:https://www.jb51.net/article/108938.htm
修改下默认的python2.7变成python3.6
sudo mv /usr/bin/python /usr/bin/python.bak
ln -s /usr/local/bin/python3 /usr/bin/python
python3.6变成python2.7
sudo mv /usr/bin/python /usr/bin/python.bak && sudo mv /usr/local/bin/python /usr/local/bin/python.bak
sudo ln -s /usr/bin/python2.7 /usr/bin/python
三、安装spark
$sudo mkdir spark
$sudo chown -R chris:users spark
$wget http://mirrors.hust.edu.cn/apache/spark/spark-2.3.1/spark-2.3.1-bin-hadoop2.7.tgz #spark官网下载地址
$tar -xf spark-2.3.1-bin-hadoop2.7.tgz #解压文件
$cd /spark/spark-2.3.1-bin-hadoop2.7/bin #spark存放位置
$./pyspark #能够运行表示安装OK
$vi ~/.bashrc #打开bashrc文件
#和python一样在bashrc文件中添加spark路径 export PATH=$PATH:/spark/spark-2.3.1-bin-hadoop2.7/bin
$source ~/.bashrc
同样在linux根目录输入pyspark能够运行表示安装成功
四、安装kafka
4.1 安装JDK
安装kafka之前需要先安装JDK,在网站http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html下载适合的版本,然后复制到目录/spark中
$cd /spark
$tar -xf jdk-8u171-linux-x64.tar.gz
$vi ~/.bashrc
在bashrc文件中添加语句
export JAVA_HOME=/spark/jdk1.8.0_171
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
然后重启环境变量
$source /etc/bashrc
$java -version #查看JDK版本
4.2 启动Zookeeper
$cd /spark
$wget http://archive.apache.org/dist/kafka/0.9.0.0/kafka_2.11-0.9.0.0.tgz
$tar -xf kafka_2.11-0.9.0.0.tgz #解压kafka压缩包
$cd kafka_2.11-0.9.0.0
$bin/zookeeper-server-start.sh config/zookeeper.properties #启动kafka自带的Zookeeper
4.3 启动Server
linux打开终端,并输入
$cd /spark/kafka_2.11-0.9.0.0/
$bin/kafka-server-start.sh config/server.properties #启动kafaka服务打开终端
4.4 打开发送消息界面
再打开终端,输入命令:
$cd /spark/kafka_2.11-0.9.0.0/
$bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test #创建test的主题
4.5测试
终端里启动4.2的Zookeeper和4.3的server服务,以及4.4的发送消息窗口后在该窗口随意输入字符,然后打开终端输入命令
$cd /spark/kafka_2.11-0.9.0.0/
$bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning #读取消息窗口
成功的话应该能够在读取消息的窗口里看到刚输入的消息
参考:https://blog.csdn.net/fenglailea/article/details/52458000
五 、建立postgres数据库
官网上有相关示例https://www.postgresql.org/download/linux/redhat/
$sudo yum install https://download.postgresql.org/pub/repos/yum/10/redhat/rhel-7-x86_64/pgdg-centos10-10-2.noarch.rpm #安装数据库
$sudo yum install postgresql10 #安装客户端
$sudo yum install postgresql10-server #安装服务端
$sudo /usr/pgsql-10/bin/postgresql-10-setup initdb #初始化数据库
$systemctl enable postgresql-10 #设置开机启动
$systemctl start postgresql-10
开启远程访问
$sudo vim /var/lib/pgsql/10/data/postgresql.conf
修改#listen_addresses = 'localhost' 为 listen_addresses='*'
#post=5432 改为 post=5432
信任远程连接
$sudo vim /var/lib/pgsql/10/data/pg_hba.conf
#修改文件的内容
host all all 127.0.0.1/32 ident 改成 host all all 127.0.0.1/32 trust
添加内容 host all all x.x.x.x/32 trust #x.x.x.指要连接的ip地址
修改密码
$sudo -u postgres psql
postgres=#posALTER USER postgres WITH PASSWORD 'postgres';
postgres=#\q
修改防火墙
$firewall-cmd --permanent --add-port=5432/tcp
$firewall-cmd --permanent --add-port=80/tcp
$firewall-cmd --reload
启动服务:
$systemctl restart postgresql-10
在这里利用Navicat测试数据库:
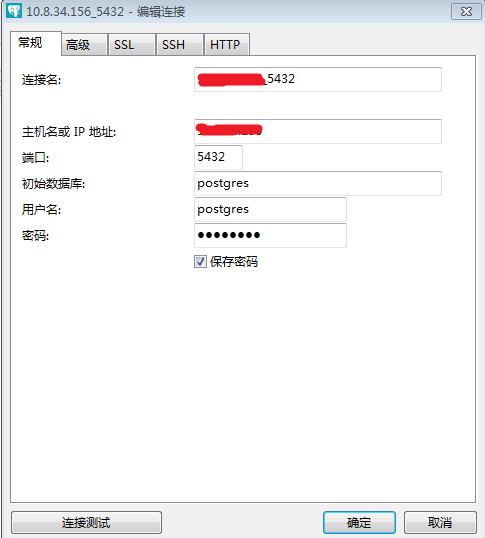
参考:https://www.cnblogs.com/stulzq/p/7766409.html
总结
安装各种软件还是有很多需要注意的地方,在此记录下来,再次安装就方便多了,只要电脑配置跟得上,后续还可以在多个机器中尝试Hadoop集群等
另外有问题的地方希望能够指正出来

