'''
date:2018年6月21日
data:
purpose:
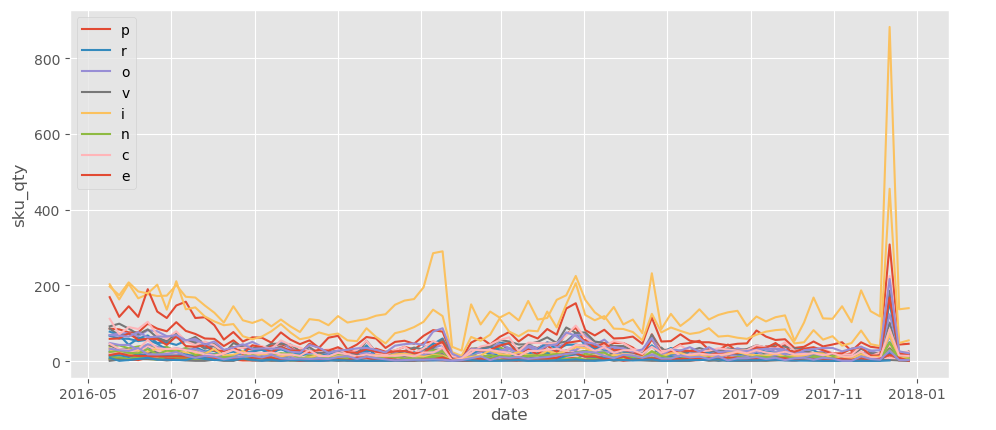
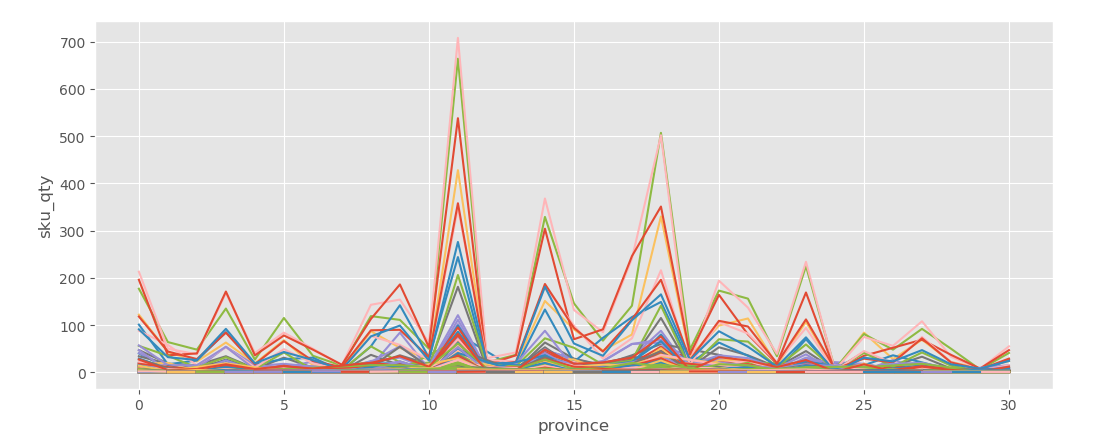
两张图,第一张横坐标轴是datetime 第二张图横坐标轴是省份
查看sku 销量 省份
注意点:
1、第一张图把省份做成list作区分
2、第二张图,做list的时候要先把string转换成float
3、转换方法 先把这列作为索引(也要保证唯一) 然后.to_dict(),然后指向这个索引位置即可
'''
import os
import sys
import pandas as pd
from datetime import date,datetime
import numpy as np
import matplotlib.pylab as plt
import warnings
warnings.filterwarnings('ignore')
dir_path = 'E:\\Data\\'
wdata = pd.read_csv(dir_path+'order_jx_y3',sep='\x01',encoding='utf-8',header=None)
wdata = wdata[[1,2,3,4,5]]
wdata.columns = ['province','city','sku','sku_qty','date']
wdata['date2'] = pd.to_datetime(wdata.date)
wdata['day'] = pd.to_datetime(wdata.date2).dt.dayofweek
mask = (wdata['date2'] > '2016-05-15') & (wdata['date2']< '2018-01-01')
mask1=(wdata['day']==1)
sku_info = pd.read_excel(dir_path+'/sku_info.xlsx',header=1,
names=['company','sku_no','item_name','length','width','height','vol','weight','class','level1','level2','level3','promotion'],
dtype={'company':str,'sku_no':str,'length':np.float64,'width':np.float64,'height':np.float64,'vol':np.float64,'weight':np.float64,'class':int,'promotion':int},
encoding='utf-8')
#不同省份不同sku的销量随时间变换
g1 = wdata.loc[mask & mask1]
plot_data = g1[['province','sku_qty','date2']].groupby(['province','date2']).sum()
plot_data = plot_data.reset_index()
plot_data = plot_data.sort_values(by=['province','date2'])
#plot_data.head(5)
province_list = plot_data['province'].drop_duplicates().tolist()
for i, province in enumerate(province_list):
plt.style.use('ggplot')
mask_plot = plot_data['province'] == province
#plt.figure()
plt.legend('province')
plt.xlabel('date')
plt.ylabel('sku_qty')
plt.plot(plot_data['date2'].loc[mask_plot],plot_data['sku_qty'].loc[mask_plot])
#p = plot_data.groupby(['date2']).sum()
#plt.plot(p.index,p['sku_qty'])
#plt.savefig("E:\\Data\\allprovince.jpg")
plt.show()
#不同省份的sku销量
df=g1.copy()
tmp = df['sku'].drop_duplicates().reset_index().drop('index',axis=1).reset_index().set_index('sku')
dict_map = tmp['index'].to_dict()
df['sku'] = df['sku'].map(dict_map)
tmp1 = df['province'].drop_duplicates().reset_index().drop('index',axis=1).reset_index().set_index('province')
dict_map1 = tmp1['index'].to_dict()
df['province'] = df['province'].map(dict_map1)
plot_data1 = df[['province','sku_qty','sku']].groupby(['province','sku']).sum()
plot_data1 = plot_data1.reset_index()
plot_data1 = plot_data1.sort_values(by=['province','sku'])
sku_list = plot_data1['sku'].drop_duplicates().tolist()
plot_data1.head(2)
for i, sku in enumerate(sku_list):
mask_plot1 = plot_data1['sku'] == sku
plt.xlabel('province')
plt.ylabel('sku_qty')
plt.plot(plot_data1['province'].loc[mask_plot1],plot_data1['sku_qty'].loc[mask_plot1])
plt.show()