
谈到数据读取,大家估计想到本周浩彬老撕要开始介绍源节点了。可能你会说源节点不就是读取数据嘛,选择路径读取就好了,但是本期浩彬老撕还会告诉你,在读取数据后,不但有时候我们会遇到一些意想不到问题(例如数据和字段对应不上),而且我们需要做一定的设置(例如我们应该怎么在Modeler中设置它的角色和类型,这一点可以说是至关重要)。另外有很多童鞋曾经问过浩彬老撕Model读取数据库数据的问题,本周也会给大家详细介绍。


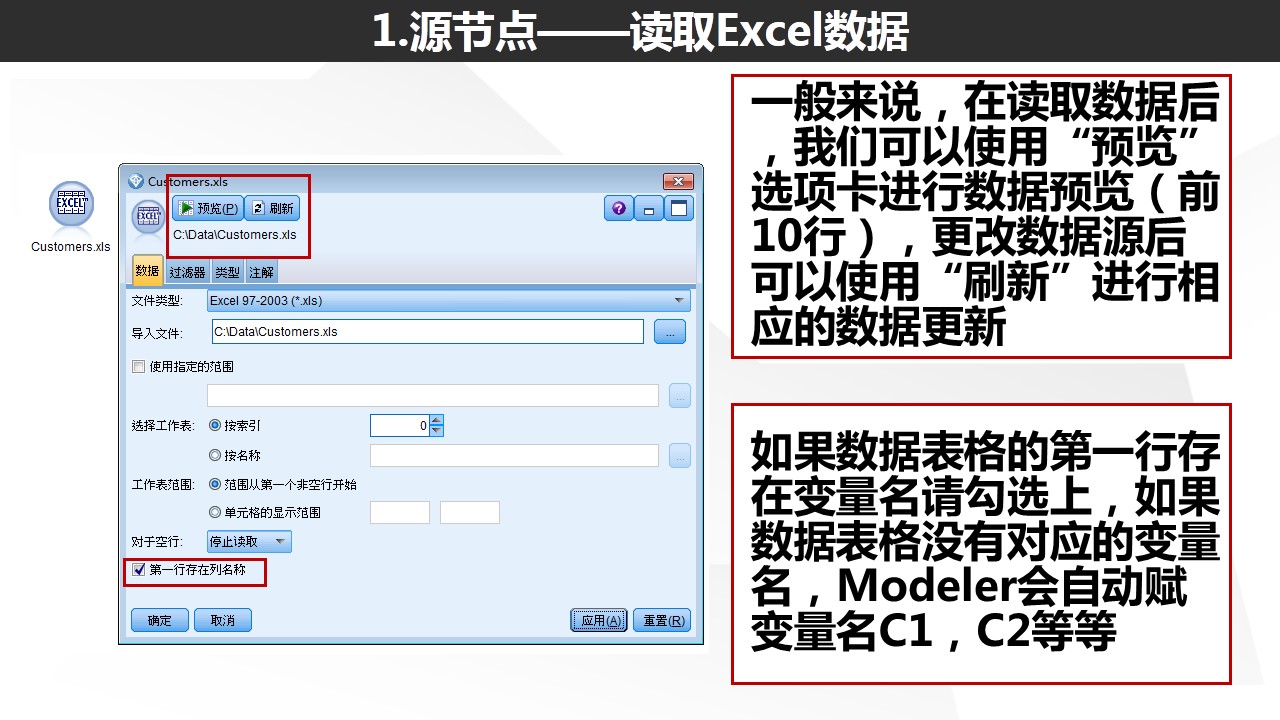
预览功能可是非常重要的一个功能,建议在每次读取数据或者对数据进行一定的操作后通过预览节点检查一下
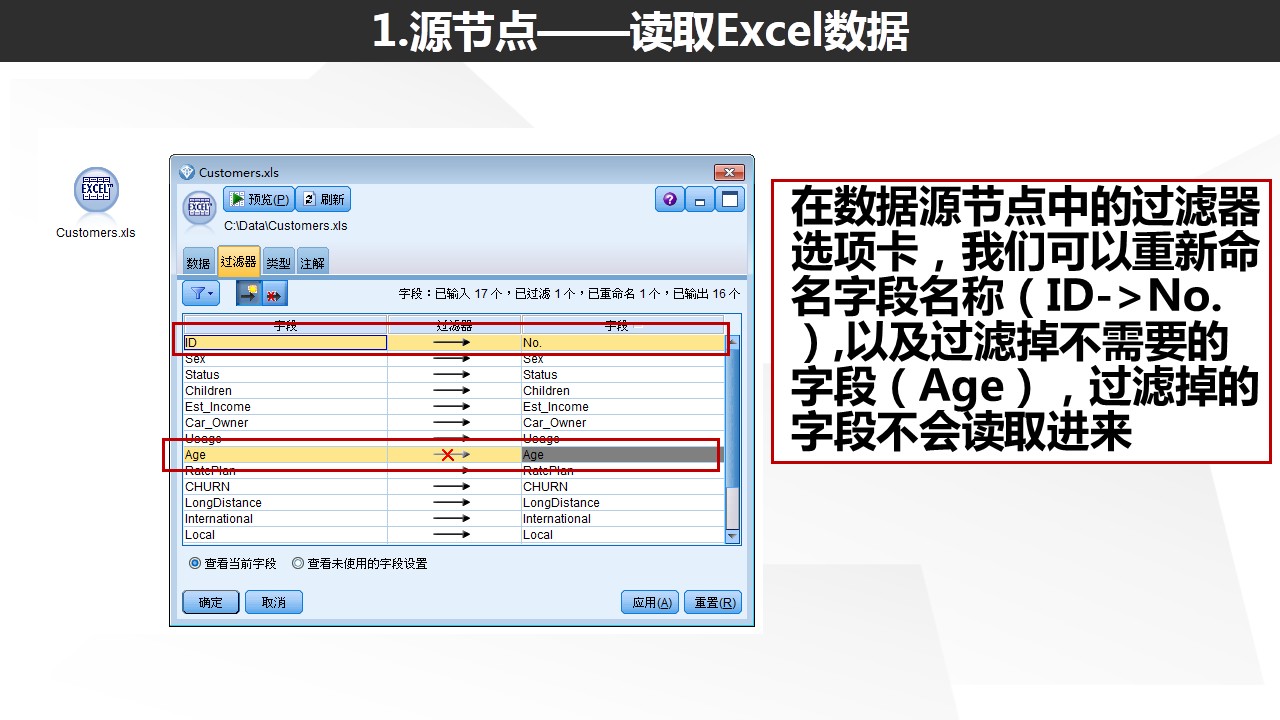
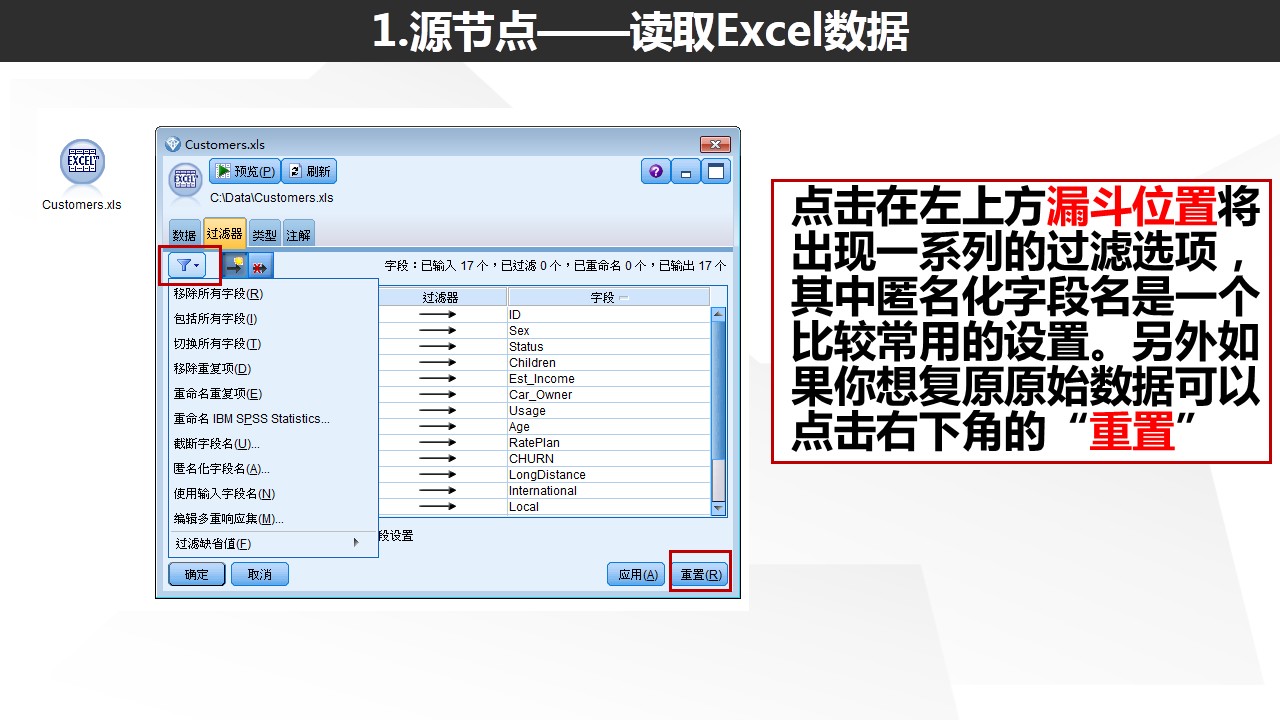
匿名化字段功能也是一个非常有效的功能,可以实现一键匿名化字段的名字,对于保护数据安全性非常有效
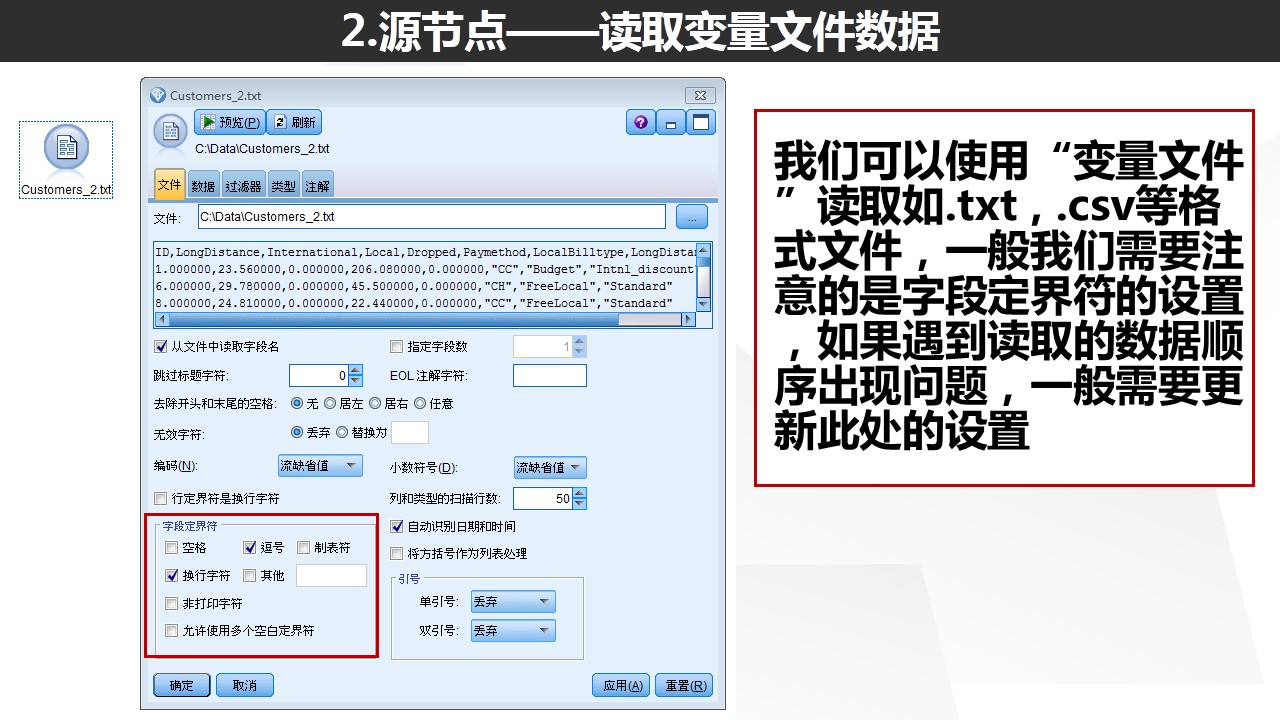
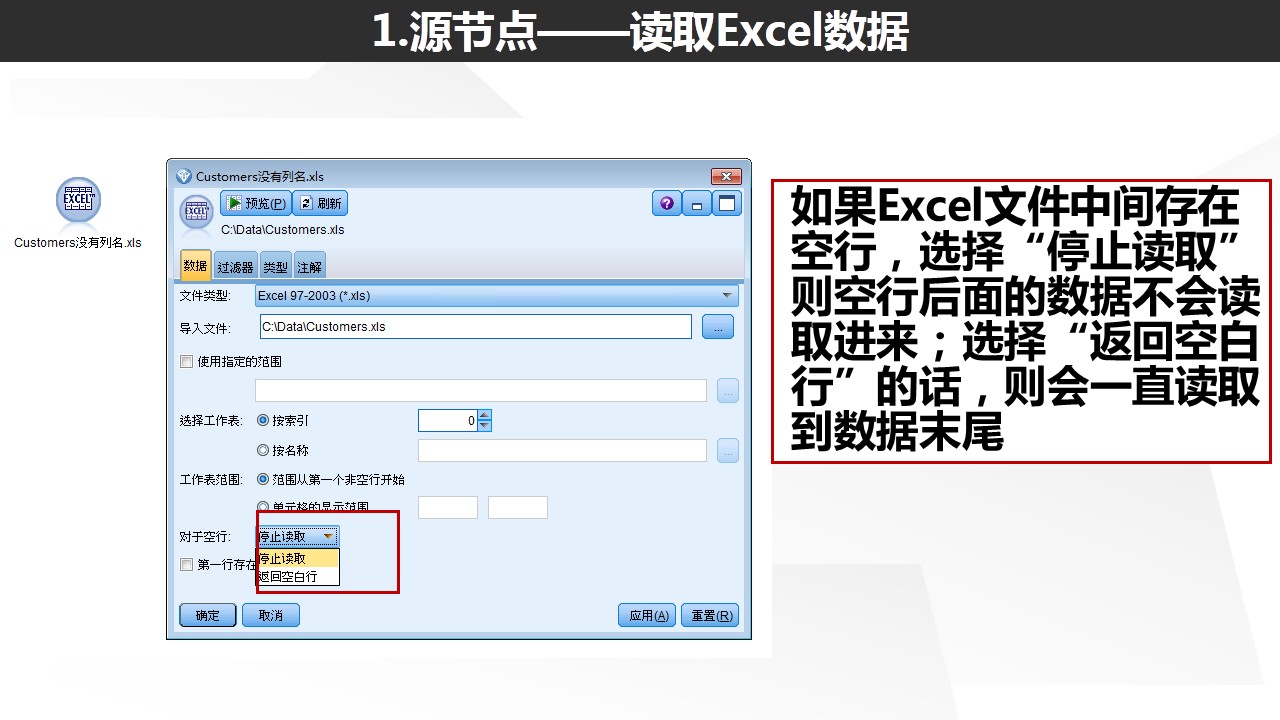
常见问题:一般来说,由于变量文件的格式没有那么直观,经常有童鞋咨询浩彬老撕说变量文件读取后出现数据和字段对不上的问题,一般这种情况,可能是因为在变量文件中的定界符出现问题。问题出现后,我们可以检查原始数据文件,定位到出现问题的位置,检查是否多了一个空格或者使用了其他的定界符。
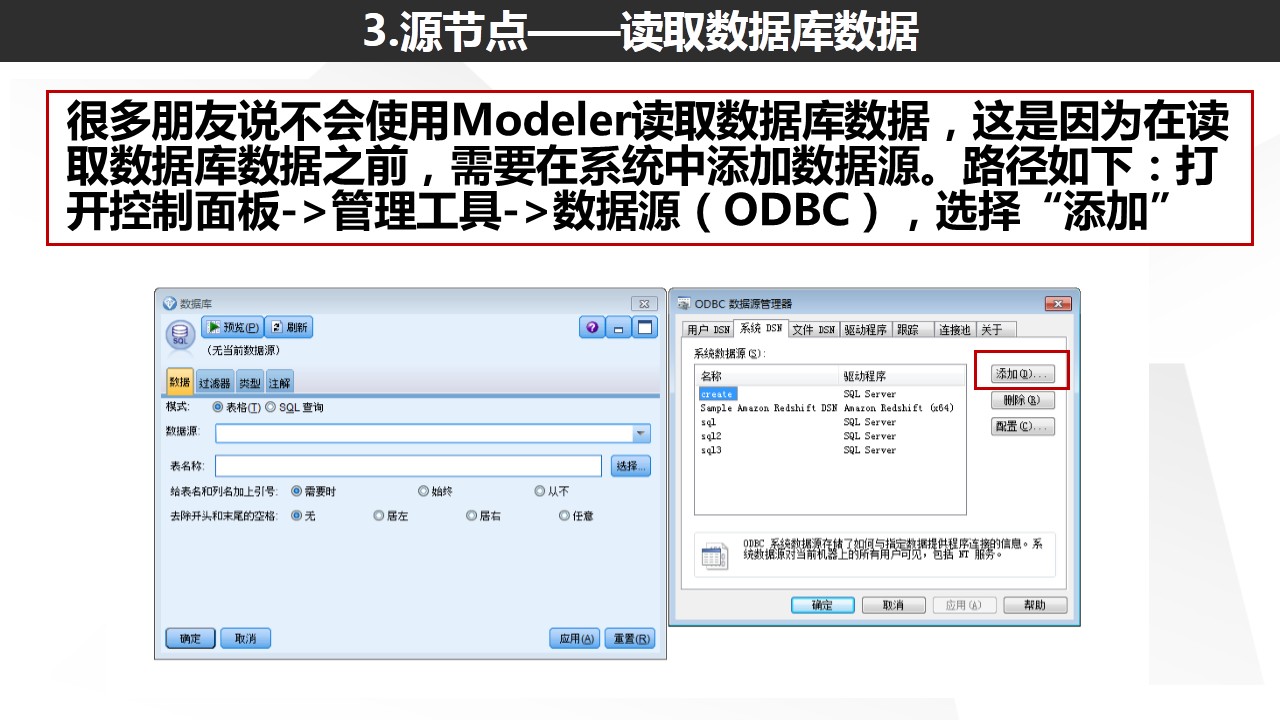
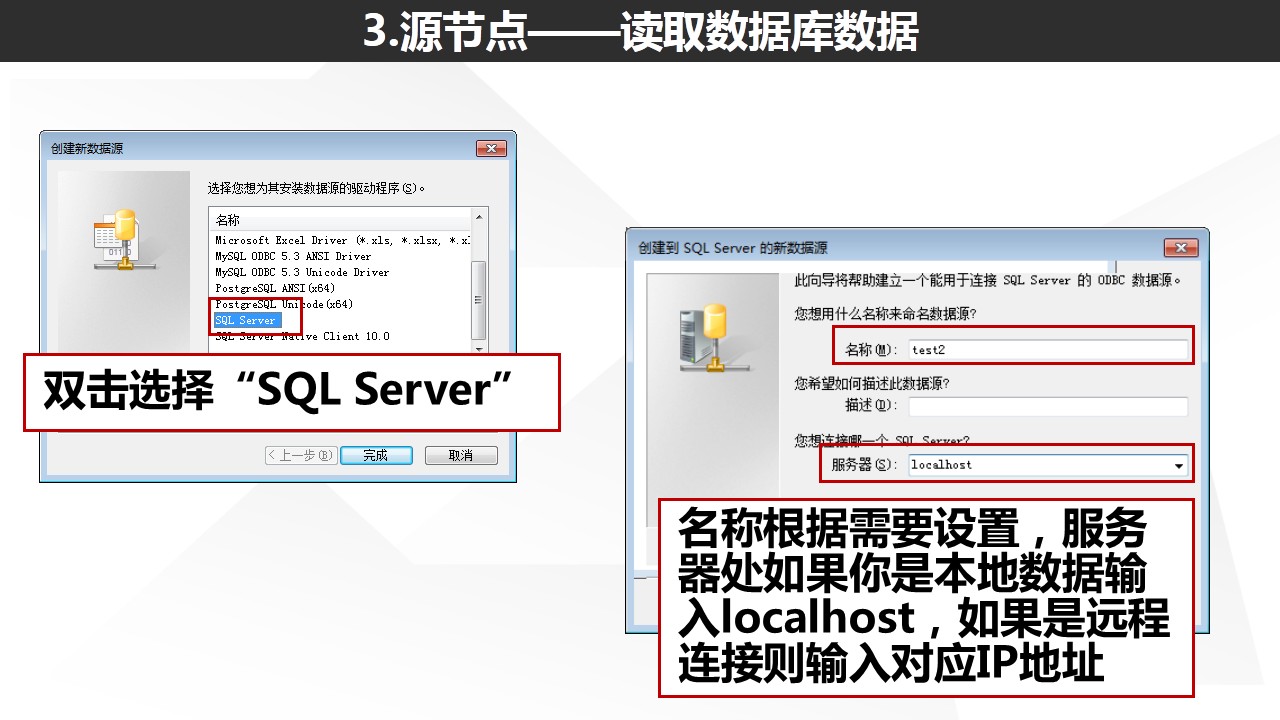

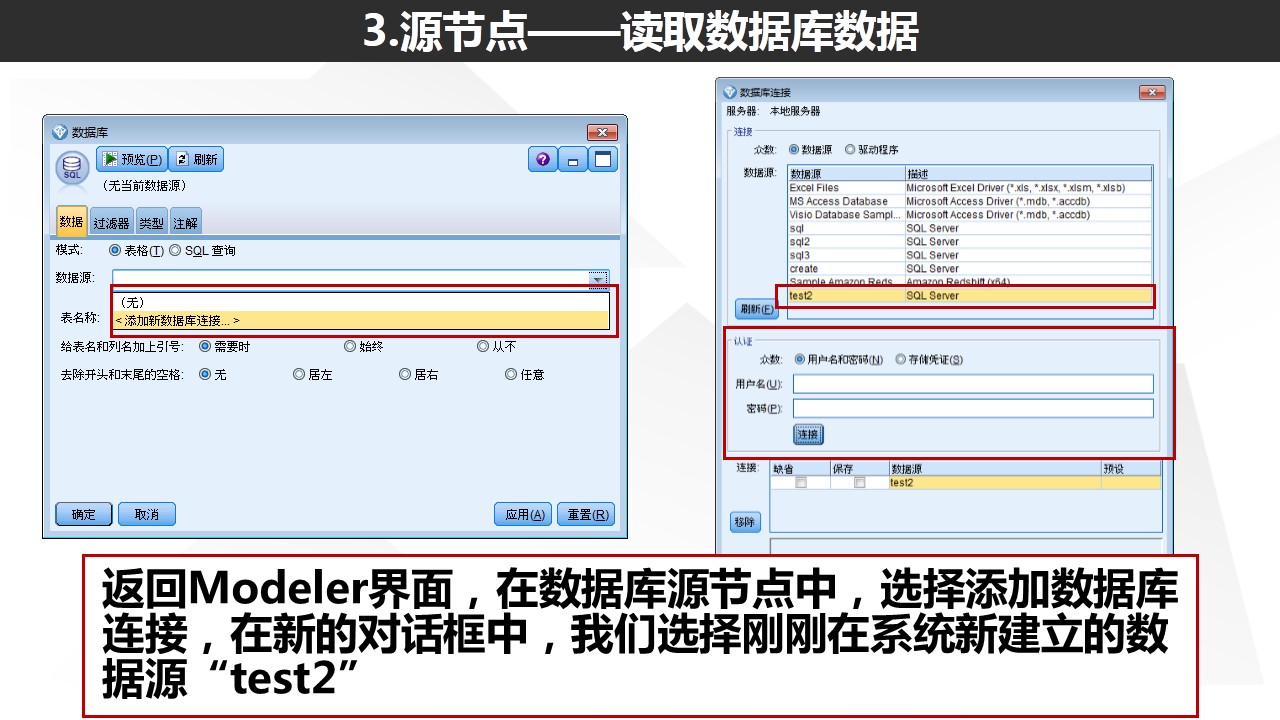
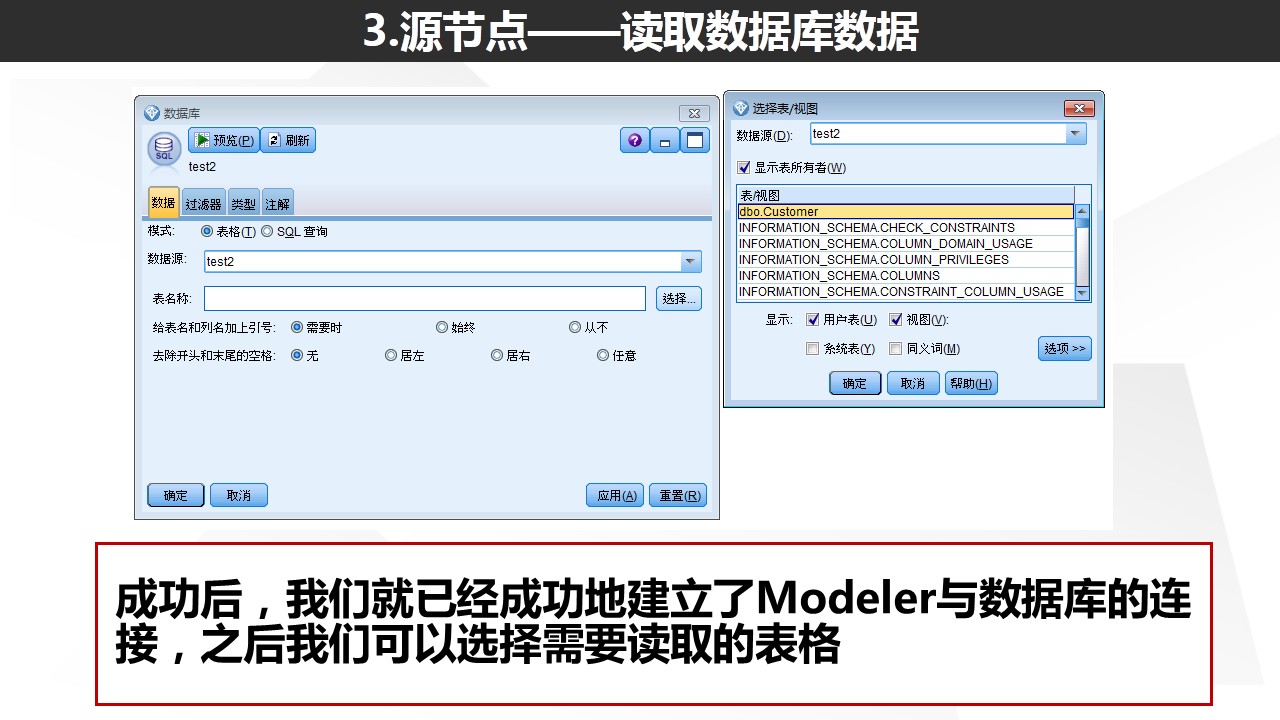
实际上,相比于其他的数据源读取方式,读取数据库数据的话需要我们在系统配置对应的ODBC连接。
SQL Server的对应连接Windows系统本身已经自带,所以无需额外安装。但如果你需要连接Oracle数据库或者DB2数据库,则需要安装对应的ODBC连接,最方便的方式是安装SPSS Modeler Data Access程序
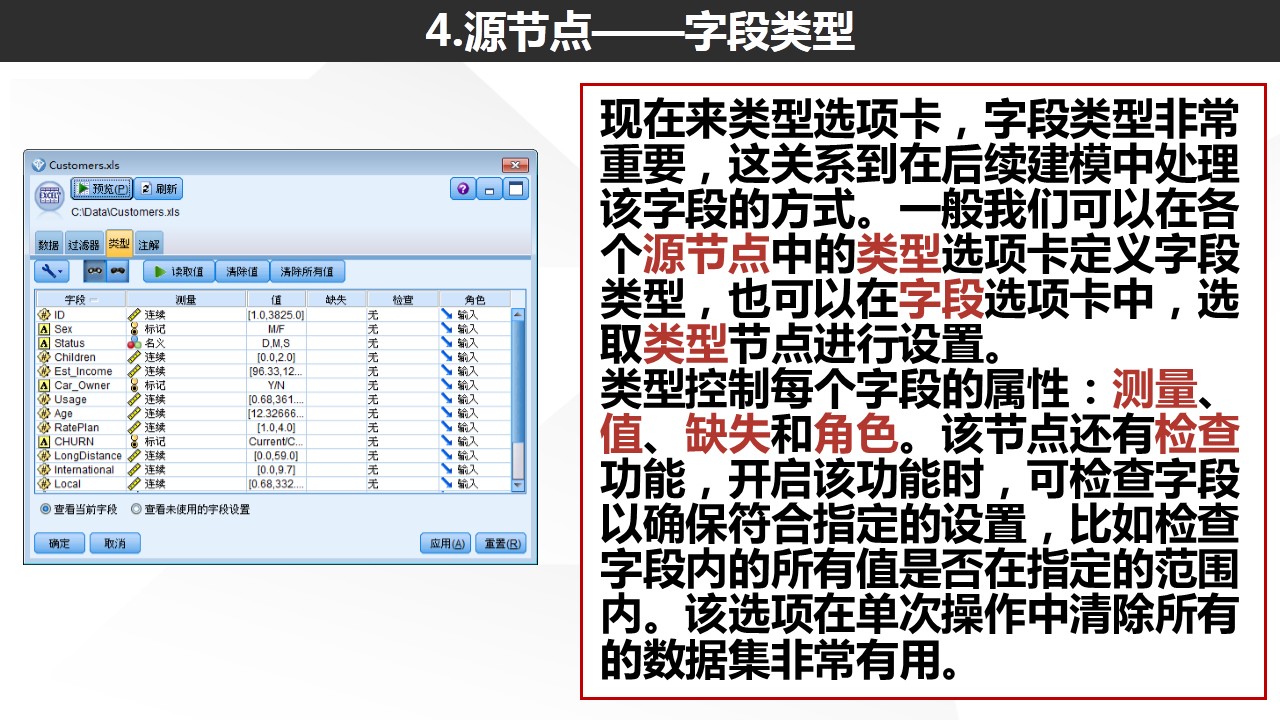
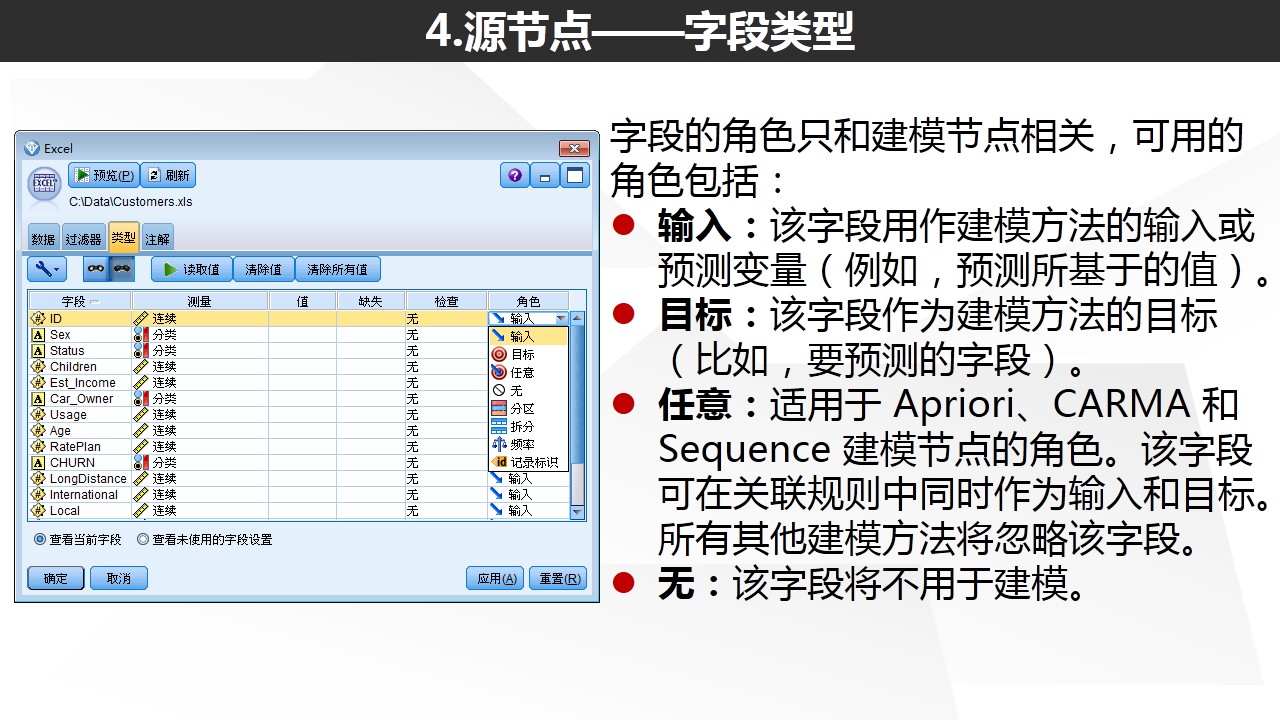
类型设置非常重要!强烈建议各位在使用Modeler的时候,在读取数据的源节点或者在源节点后选择“读取值”,对数据进行实例化

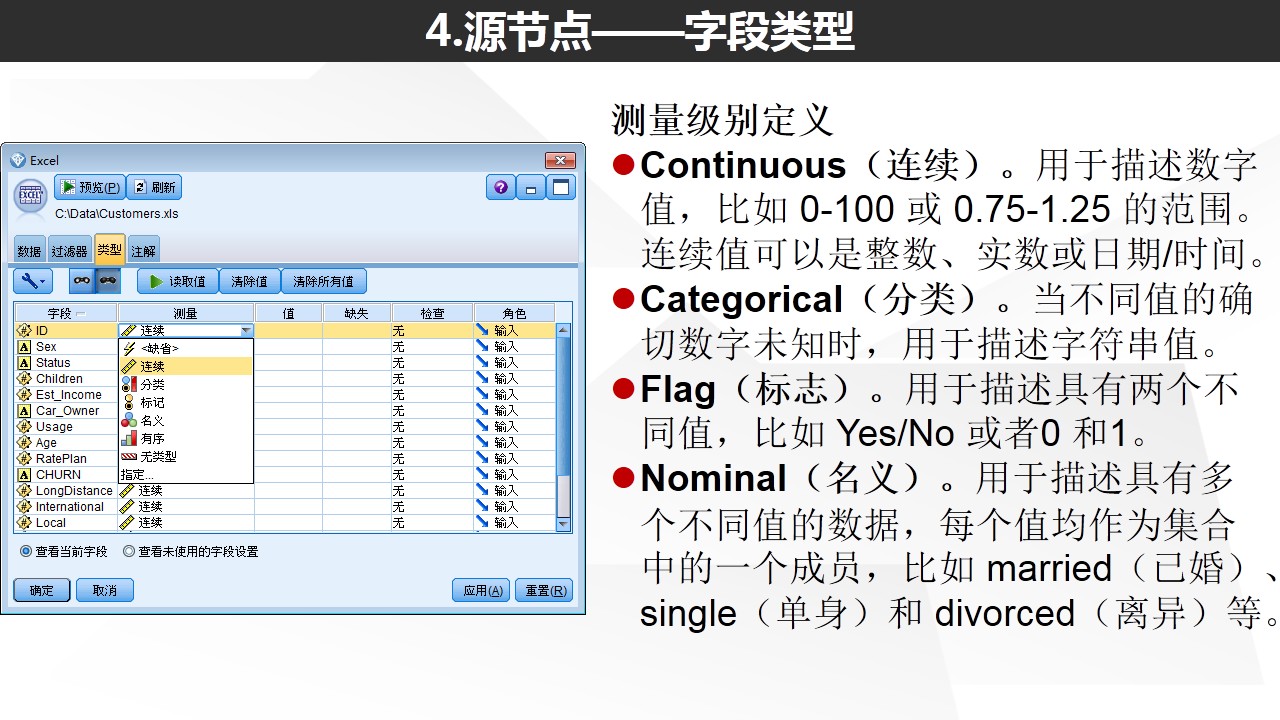

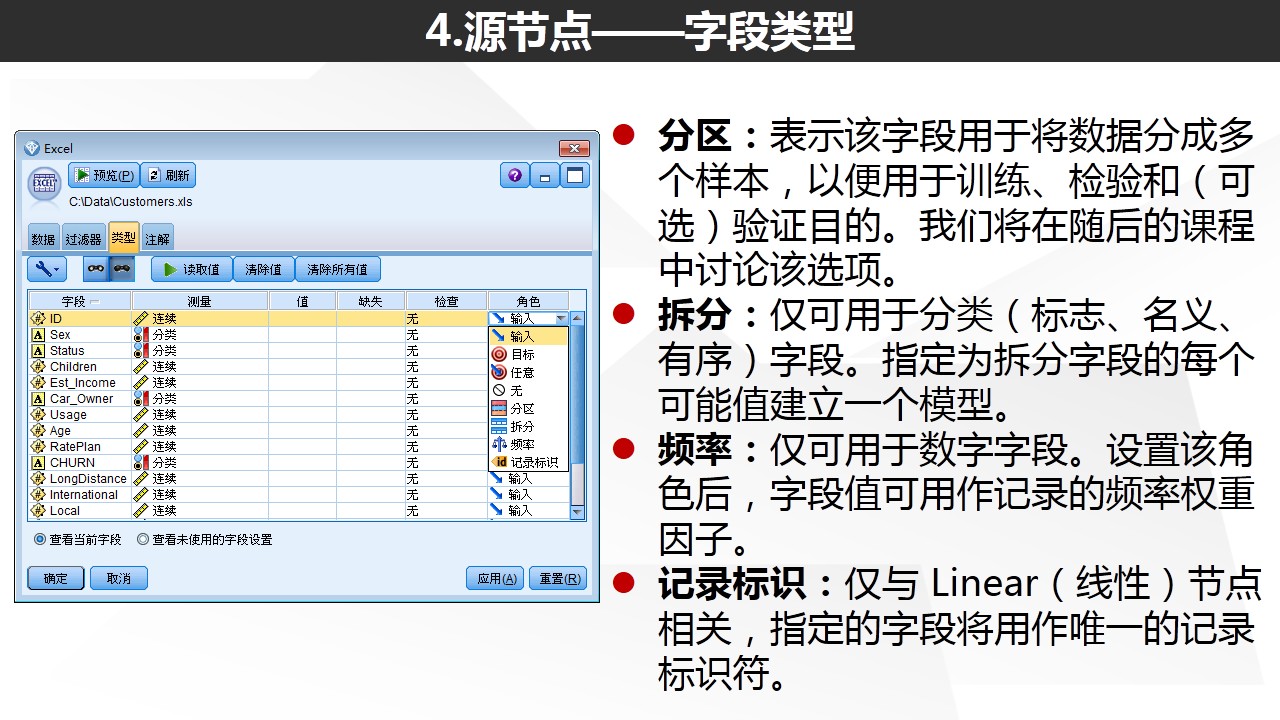
常见问题:当我们发现有数据被Modeler设置为“无类型”,但是这个字段并不是属于ID,那我们就可能要考虑是否该字段的类别数超过了250.
关于浩彬老撕
浩彬老撕正在努力做一些事情,希望能够以比较轻松的方式为大家讲述一些统计学,数据挖掘的知识,包括算法,包括工具使用问题,也包括一些科技八卦,同时也会举办一些送书活动,希望大家能够喜欢。另外如果你想联系我,欢迎在公众号中直接发送你想说的话与浩彬老撕直接交流~
长按二维码即可关注!如果你觉得浩彬老撕的内容还不错,希望你可以推荐给其他小伙伴↓↓↓

更多书籍更多数据挖掘知识,敬请期待

