记忆RFM模型的方法
悲剧地发现已经把业务部分忘得差不多了。虽然RFM模型还有印象,但是其中8个客户维度叫不出名字。
学到这一课的时候刚好复习一下,强化记忆。分享一下我对这8个部分的记忆方法。

R:recency,最近一次消费
F:frequency,消费频率
M:monetary,消费金额
1、区分“重要”和“一般”:有钱的大佬比较重要
每个维度最前面都有一个副词修饰,要么是“重要”,要么是“一般”。
这个词的划分维度就是M(money!)。钱多的重要,钱少的一般。
2、R近F多,有价值;R远F少,要挽留
划分好重要和一般,接下来“客户”前的定语有四个,根据R和F定位不同象限。
R近F多的客户,最近才买过产品,且买的频率很多,说明经常光顾,有价值;
R远F少的客户,许久没来了,很少买产品,最好能够挽留他们。
3、R近F少,有潜力,可发展
最近买过产品,但购买频次很少的客户,可能才刚刚了解我们的产品,并对此很感兴趣。
随着时间的推移,他们可能购买频次会不断增加,说明很有潜力,能够持续发展为有价值的客户。
4、R远F多,要唤回,保持联系!
最近没有买过产品,但曾经多次购买的客户,可能因各种原因放弃了产品。
最好能和他们保持联系,唤回他们。
结合上面三点用象限图来表示:
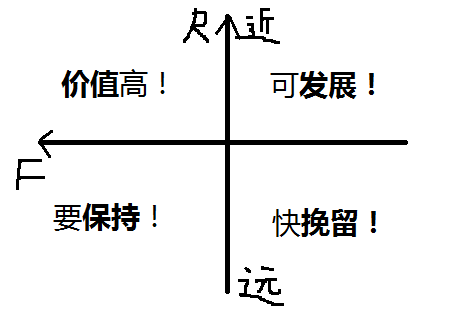
分清这四个再结合M,很轻松就记住啦!
练习中的小补充
还有2处个人觉得秦老师可能讲得有点问题的地方。
1、分层问题
秦老师在课程中把‘111’定义为‘重要价值客户’,我认为有问题。
我们算R的时候,是(最晚时间-order_dt)的负数,R越大距今越远。这里R>R.mean()意味着时间过了很久了,并不是最近的。
因此R的1应该改成0,‘011’才是重要价值客户。

↑ 我的分法。
2、按lebal用户分层,聚合时看人数应该用count()函数,而不是sum()
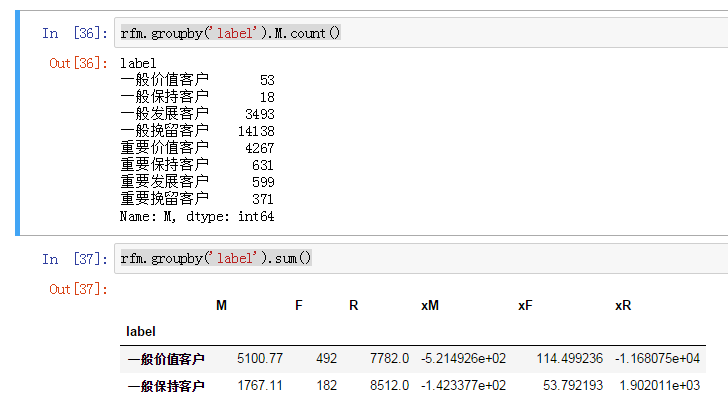
得到一般挽留客户14138人,为最多的一类。这个结论才比较符合上下文以及实际业务。
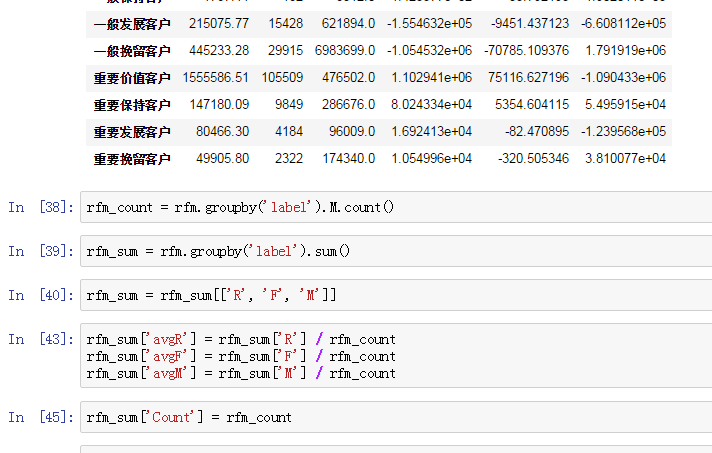
(这里我求了RFM的人均值)


(本来想学一学plot画个图的,然而水平不够……山高路远,道阻且长!!加油加油!!)
