公告
周五BI飞起来,每周一个主题,一场跟数据有关的行业、工具、技术的交流盛宴,锁定在每周五晚20:30,不见不散!
未来几期的微信直播活动分享主题将包括谈谈BI在生产企业的应用、数据科学家应用 、SPSS数据挖掘、腾讯大数据分析与挖掘应用、R语言实战、数据挖掘经典案例赏析等,具体日期安排请关注天善智能问答社区活动版块https://www.hellobi.com/events
主持人:加入本群的同学们,感谢大家参加由天善智能举办的 Friday BI Fly 活动,每周五微信直播,每周一个话题敬请关注。
【群规】本群为商业智能和大数据行业、技术、工具的交流学习群。不准发广告,只能发红包,发广告者一律移除微信群。
本期分享内容
机器学习技术在R语言中的商业应用
本期嘉宾介绍
丘祐玮(DavidChiu)
大数软件(LargitData)创办人,是一位致力于提供舆情分析服务的创业者与数据科学家,熟悉Hadoop,Spark 等巨量数据平台,及擅长使用R,Python与机器学习技术进行数据分析。曾任多家上市公司顾问及担任知名大数据应用程序竞赛的评审,自身着有MachineLearning With R Cookbook [Packt] 与 R Cookbook [Packt] 二书
主持人:大家好,我是微信直播活动的主持人咖啡,每周一个主题,一场跟数据有关的行业、工具、技术的交流盛宴。我们的口号是“Friday BI Fly 周五BI飞起来”。有请嘉宾进行下面的分享,机器学习技术在R语言中的商业应用,有请!
机器学习技术在R语言中的商业应用

大家好!我是丘佑玮,很荣幸今天有这个机会跟大家分享「机器学习R语言的商业应用」。
首先先介绍一下我自己。我目前是台湾大数软件的创办人,公司主要营运大数据相关产品,包含舆情观测与推荐系统等数据产品与服务,客户涵盖金融、寿险、半导体、与各大中小企业。目前著作Machine Learning With R Cookbook [2015 PACKT] 与 R Coobook [2016 PACKT],之后Machine Learning With R Book有幸被机械工业出版社于今年翻译成机器学习与R语言实战(简体书)。
今天要谈一下R语言在商业的应用。
为什么要用R做机器学习
资料分析的步骤可以拆解为四大步骤,包含数据搜集,数据处理,数据分析与数据可视化,其中资料处理大概就佔据了80%的时间,剩下20%的时间都在做资料分析与诠释结果。
比如说,你今天发现了尿布跟啤酒的关系,你如果不去探明就理,便容易被老板打枪,所以诠释结果又会占据了其中80%的时间,所以真正做数据分析的时间少的可怜, 只剩下4%,但其中大多做的都是加总跟平均, 算不上高深的技术,可想而知, 如果要真正做上机器学习, 时间可算可贵。
但是每个机器学习背后,都有其学问与算法。因此,我们就需要一个好工具帮我们解决机器学习的问题。而R 语言发展至今, 已经有超过6000多个套件, 你想的到的机器学习套件都可以在上面找到。因此, 他可以当成是你入门机器学习的一个好工具。
机器学习说穿了, 其实就是让计算机从数据中归纳出规则,像人类一样,,我们原本是透过观察习得经验值, 计算机的学习过程就是从数据中推导规则,
而其实机器学习发展至今也过了好几个年头, 他不是新技术, 但最近又火红了起来。
为什么?
就是因为以前的数据量不够大, 计算机没有足够的样本学习, 因此不够聪明,现在是大数据时代, 因此可以取用的数据与维度很多,,我们便可以让计算机习得足够的经验值,,让他做更聪明的推导。
机器学习发展至今,也过了好几个年头,各种方法百家争鸣,眼花撩乱, 而R的好处就是可以快速替代各种学习算法,让你可以马上用各种算法建立模型,产生预测结果。
例如要做个分类,你就可以从e1071 套件中取得naïve bayes,svm 等各种分类算法。你可以不用懂每个机器学习背后的算法, 便可以快速使用套件进行数据实验。
以下, 我们就分享几个机器学习在商业上的应用。
机器学习可以分为两大类,四种问题。
两大类分别是监督式学习与非监督式学习,听起来有点饶口,但区别就在于一个是根据有历史答案的资料进行学习。而监督式学习又可以根据预测的响应型态分为回归分析与分类问题。回归分析是用做连续型数字或二元数据的预测, 因此像是房价, 股价的预测, 都可以使用回归分析来建立预测模型。而相对于回归分析的问题即是分类问题,该问题的主要目标就是要预测类别数据, 因此当要预测的响应是类别数据(股市涨跌, 顾客是否流失)就可以用这种方法产生预测模型。
我们来举几个使用R可以完成的监督式学习案例。
案例一:房价预测
拿房价预测来当例子,现在在台湾的房价很高, 一般屌丝可能要不吃不喝数年, 才有机会买一套房。之前我去看房时, 一位房仲跟我说, 他的价格最公道, 比旁边区域要好上很多。为了要能预测这件事, 我们必须真实验证这数据的合理性,我们看一下该如何验证:
首先,我先写了一个爬虫抓取买屋网的信息,https://rent.591.com.tw/
这是台湾买屋网的信息,我刚刚也试爬了一下青客的信息http://www.qk365.com/room/20650。如果有兴趣者,可以使用rvest 等R套件抓取该房价信息。
例如
library(rvest)
read_html('
http://www.qk365.com/room/20650'
)
%>%
html_nodes('dd') %>% html_text() %>% iconv(from='UTF-8',
to='UTF-8')
就可以将房价等信息爬取下来,我们接着就可以将数据整理成表格
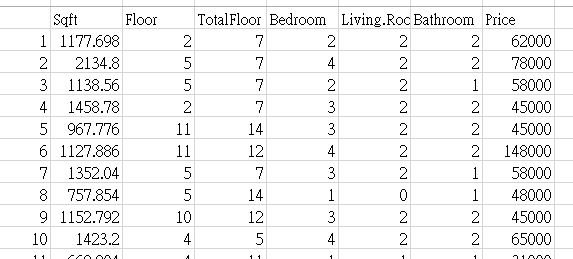
像這樣的格式,透过R便可以简单做回归分析
house = read.csv('house_rental.csv', header=TRUE)
我们载入这资讯
plot(Price ~ Sqft, data=house)
R透過一行指令便可以绘图,做回归分析更加容易
fit = lm(Price ~ Sqft, data=house)
一行指令我们便可以针对地坪与房价做回归线,如果要判断哪个变量是否有用
fit = lm(Price ~ ., data=house)
先将所有变量丢下去建立模型
step(fit)
Step 一行指令便可以帮我们挑出最有用的变量,例如地坪与楼层,房数很重要,但总楼层数就显得不太重要。之后我们可以再用predict 函式,快速产生预测结果。
使用R做机器学习,简直小菜一碟。
案例二:电商数据预测热销产品
另外举个电商数据的案例:他想要从上一个月客户的交易纪录预测下个月热销前20商品。
我们看一下真实数据的长相
203.145.207.188 - - [01/Feb/2015:00:00:00 +0800] "GET /action?;act=view;uid=;pid=0005158462;cat=J,J_007,J_007_001,J_007_001_001;erUid=41ee27d6-5f83-b982-69f9-f378dc9fc11b; HTTP/1.1" 302 160 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0"
这是log 信息,很杂,,很乱,很大,一个月可以累积数百G的数据。
我们首先可以将数据清洗,整理成表格格式,具体项目包含去除掉测试数据,爬虫数据,切使用者session 跟补齐浏览时间,因为log 记录只保留了用户每次点击的时间点, 因此我们要推算大概他一页会停留多久。之后我们可以将数据整理成这样表格形式的数据
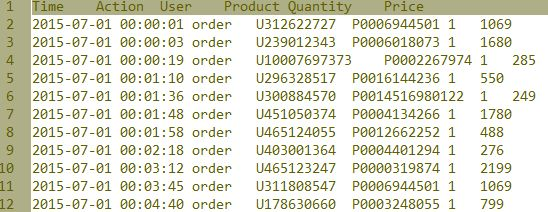
之后我们将浏览次数跟比例从数据中拉取出来,此时用判定树便可以根据使用者浏览情况决定该使用者是否可能购买该商品。
下个月的前20热销也可以用这方法预测。而R 语言的好处就是可以快速实验使用各种方法,当我们改使用了randomforest,便可以100%预测中前20的商品,除了推算出隔月的热销产品外,我们发现如果一个使用者观看该商品的重复性与在一session 的观看比例占比高,他购买的机会也就越高。
因此之后我们请前端做了一个功能,当发现有一个使用者重复看了这商品两次,我们便让前端再打一次,这样就可以快速促进商品的销售,也就让机器学习的成果跟商业应用有实质的连结。
另外我们主力产品是做舆情分析的,因此也有应用分群等技术在探索文章主题,抽取用户关键意见,另外也有使用分类技术追踪主题,将机器学习应用在文字处理上, 更可以帮助客户倾听用户的心声。
今天就先简单介绍到这边, 给点时间让大家问问问题吧
主持人:好的,感谢丘老师给大家带来的精彩分享,老师通过实际案例给大家讲解了如何用R语言实现机器学习,而R的好处就是可以快速替代各种学习算法,让你可以马上用各种算法建立模型,产生预测结果,用老师的话就是“小菜一碟”,大家快去试试吧!下面进入自由提问环节,对今天的分享内容有疑问的,大家可以提出来啦!
自由讨论
问题1:将机器学习应用在文字处理上 这个能不能举个应用的例子?
David Chiu:以往舆情分析专注在于用声量了解民声,但我觉得这根本不通, 重点是要摘要出民众讨论的议题有哪些.
给个范例: 今天有些人在商城上购买电饭锅, 势必会留下评价. 我们就想是否可以能将这些评价做摘要, 让我们针对摘要做统计, 而不只是单纯看声量,因此我们实际的作法如下:
1. 先利用jiebaR 将文本断词,
2. 接者求出词频矩阵
3. 将文章做分群
4. 根据同一群的资料做Multiple Sequence Alignment
5. 抽出句子
6. 最后对句子贴标
问题2:1.如何读取房子的地理坐标数据;2.搜房网等是不是设置了一些防止爬取的东东呀,怎么应付;3.如何在网页上爬到并整理自己需要的数据4.你做的房价分析的有代码例子吗
David Chiu:地理坐标很容易读取, 因为都是用javascript 贴上去的, 所以只要找到javascript 的位置就好. 爬虫是只要看的到就爬的到, 多半防止的方式就是检查Header, AJAX 还有档IP 的方式, 不过魔高一尺, 道高一丈. 都能爬就是了
问题3:R可以爬取app的数据么?
David Chiu:APP 里面也是用HTTP 请求去要求数据,所以也可以去抓取
但是因为他的接口藏在APP中,所以一般我们会先反组译APP,然后用wireshark 监听接口,麻烦了一点, 但还是可以抓取。
最近外国很疯的pokemon, 就有人已经干了这一回事,将他的数据开放成API。
问题4:机器学习一般用什么数据库?
David Chiu :哪一种数据库其实都好, 因为运算时还是要载到内存中。
问题5:r语言和hadoop关系是什么样的?
David Chiu:R 只是语言工具,他当然可以存取Hadoop 中的HDFS。
如果是使用商业版的R,你可以参考RHadoop 项目,微软的RevoR 也支持Hadoop 的数据存取。
问题6:当发现有一个使用者重复看了这商品两次,我们便让前端再打一次,这个是什么意思啊?打什么标签?
David Chiu :是这样的,我们发现使用者是否购买,跟在一个session 中看的商品次数有关,因此如果有一个使用者看了同款笔电两次,我们会请前端再打一次该笔电广告,让使用者观看,促进购买欲望。
问题7:R 如何处理单机无法加载的大量数据?
David Chiu:几招,RMPI,RCPP. 'parallel' 或用商业版的R
问题8:判定树是什么
David Chiu :判定树是什么?我们叫Decision Tree 为决策树,判定树是Word 帮我翻译的。
问题9:老师能不能讲一下,如果学机器学习的话要学哪些技术? 而且还想知道大数据哪些技术比较有前途,或者说大数据的未来哪些方向是比较有潜力的?
David Chiu :大数据百家争鸣,老实说选哪个都不是明智选择,举个例吧,比如说现在最火红的是Spark,但是Hadoop 也说他出3.0 后会比Spark 快10 倍,所以这个技术坑追不完。但多数企业没有大数据,专注在资料科学是唯一救赎。我觉得投资在机器学习,并学习如何用R 与Python 是最佳投资。
问题10:老师,我想问一下,如果不懂算法源代码,不懂怎么修改算法,在建模的时候,建模预测比较准,但用来预测就不准了,这个是什么原因,比如用随机森林预测,怎么去调优模型呢?
David Chiu:实际上我们很少动到算法, 多半动到的是特征(Feature Engineering) 以及参数的挑选, 以及必须要根据数据特征挑选算法, 算法基本上演化很久了, 多半的解都是通解, 很少有机会让你去修改理面的算法。
问题11:好早就听说Matlab做机器学习,能比较一下Matlab和R语言么?
David Chiu :Matlab 要钱, R 不用, 你用的Matlab 有付过钱吗?
伟:百度的吴恩达很推崇Matlab,也许是因为他之前在斯坦福教书不用交钱。
问题12:能发下爬取房价的代码吗?
David Chiu:
library(rvest)
house = read_html('http://www.qk365.com/list/a16-k217')
house %>% html_nodes('.boxList li') %>%
html_nodes('.oddsText') %>% html_text() %>%
iconv(from='UTF-8', to='UTF-8') %>%
strsplit(x=., split='[ \n\r\t]+' )
像这样,就可以把价格抓出來。
问题13:再请教个问题,也没有比较好的算法分析低频次数据,比如汽车的启动,行驶,等红绿灯的短停,如何精确计算每次的行驶时间,行驶里程,这还涉及到过滤掉一些错误数据的问题?
David Chiu:低频次吗? 是所发生的特别少吗?
伟:比如10秒一个数据,有时间,车辆编码,瞬时速度,瞬时里程等等,里程是逐步增长的,还有经纬度等信息,实际上速度和里程还有经纬度是时刻在变的。
问题14:@David Chiu 请问,R如何实现大量日志数据的处理?使用了哪些平台?如何实现R的分布式算法?
David Chiu:SparkR 会是你的好朋友,RMPI 也不错, 但会single point failure,如果要考虑到地理咨询的话,可以用spatio-temporal analysis。
锋:SparkR目前只能做数据处理,算法比较少。
David Chiu:可以用rJava 接MLLib 的接口,不过你说对了,就很麻煩
Michael:对,我觉得sparkR太搓了,连逻辑回归都不能用。
David Chiu:请各位大神开发。
锋:老师通常的解决方案呢?
David Chiu:我用pyspark ,哈哈,是透过rJava 接MLLib 没错,因为也不需要呼叫太多指令, 這是目前唯一救赎。
锋:感谢解答!看来得好好学习python。
问题15:请问自变量与因变量的取样频率不一样,有适合这种情况的模型么?
David Chiu:自变量跟因变量的取样频率不一样? 是分开取的吗, 怎么会不一样?
曹敏:比如说对生产过程中的某个属性,取样频率是10分钟一次,但是最后的因变量,也就是测试指标,是1小时每次~
David Chiu:哦,那通常就是看资料特徵, 适合取中间值, 中位数, 时间一开始最初始值, 或最后一个值,要数据实验才知道哪一个比较恰当
曹敏:这样做就会丢失很多数据信息了,数据量也会变得比较小。还有其他什么方法么,听说虚拟变量可以,没用过,请问行嘛?
David Chiu :Dummy Variable 不适合用在这个案例上,数据少一些,倒不是重点,还是要先探索一下这自变量跟因变量的关系,相识我们之前做产线感测器的数据,多数的资料不太重要,因为他会一直发类似的数据,所以我们只有取一个代表点来用就好。
不过有另外一种方法,有时我们会决定这时间的数字是否异常,我们会这样做,去平均线或是boolean通道 。没有超过这些接线的可以给他一个类别0,超过的给1,天数据跟月数据的方法差不多。
叶鹏:你好,关于天数据的销售预测您会怎么做,请给些建议?月数据周期性明显些,天数据不明显啊
曹敏:但是这跟因变量如何联系起来呢?
David Chiu:惟一要注意的是,消费者周间与周末购买的品项不太相同,所以建模型是根据周做周期,但也要考虑月的因素,通常月底的销售量会比较好,猜测是当天发工资。
叶鹏:这种模式用什么机器模型学习比较好呢?
David Chiu:特征选择还是比较重要
叶鹏:我目前做的是回归分析,模式还没分析抽取,特征我大概能列出一些
David Chiu:我们之前是做分类,我只是先预测这个客户会不会买,然后再测算是否购买去推算金额。
叶鹏:怎么选出显著的呢,但是明天你不知道哪些客户来啊
David Chiu:有很多方法, 用rminer 她就可以根据不同算法帮你挑显著的,rminer 是R的一個套件,https://cran.r-project.org/web/packages/rminer/rminer.pdf
叶鹏:嗯,好的,我记下了,谢谢
问题16:house.r 中rvest无法安装,是不是与R版本不支持
David Chiu:要升級到最新版的R,Hadley 最近的套件都只支持最新版的。
问题17:您现在研究预测吗,有人在研究基于事件驱动的预测,您是一般怎么做的?David Chiu:RTB 吗?类似Real time bidding这种的?
叶鹏:是的
David Chiu:这用spark streaming
叶鹏:这种研究您怎么评价?有没有成功案例?
David Chiu:还是使用RMSE,RTB 就评估CPC, CTC 有沒有lift 就可以了
叶鹏:应该是用r语言
David Chiu:
TopK 广告活动
记住最近一周使用者浏览来源
如何辨识统一为的使用者
成功转换活动的客户特征
使用者年纪与行为分布
我们会考虑这些,R语言不能做即时系统呀,正确的说是不合适,不过谈到RTB,预测精准不是最重要的,预测对手价格更重要。
叶鹏:哦,您主要是通过筛选特征,然后机器学习来做吗
David Chiu:是呀,大多还是用机器学习,不过用的范围很广,要找出同一群客戶 , 分群,抓出特征后,做使用者贴标,然后根据Ontology 我们会用AHP筛选显著使用者
叶鹏:我现在对回归分析与机器学习特征怎么有效结合很困惑
David Chiu:困惑的话让step 帮你忙,他用AIC 筛选特征
叶鹏:分类我使用过svm,step是在哪个包
David Chiu:SVM... 数据大时会很慢..
David Chiu:预设就有step,stats中
叶鹏:哦,基础包啊
西蒙:逐步回归很好的做的查查就知道了,先谢谢David Chiu老师今晚的讲解,实验室要关门要回宿舍了。
叶鹏:您分类一般用哪个算法?据说分类有2个算法是最准的
David Chiu:沒有最准的说法啦 只有合不合适 当然比赛的时候用gradian boosting 跟 random forest 都是常胜的两个方法。
叶鹏:好的,学到很多,我周围都有您的书
David Chiu:感謝~ [流泪]
叶鹏:其实还有很多想请教的,您公司有主页吗,去看看你们的产品
David Chiu:www.largitdata.com
下期预告:
2016年07月29日晚8点半微信直播腾讯大数据分析与挖掘交流会第26场
https://www.hellobi.com/event/72
今天的微信直播活动到这里就结束了,喜欢天善智能的朋友们请继续关注我们,每周五晚8:30,我们不见不散哦!
参与方式
每周 Friday BI Fly 微信直播参加方式,加个人微信:fridaybifly,并发送微信:公司+行业+姓名,即可参加天善智能微信直播活动。
天善智能介绍
天善智能 www.hellobi.com 是一个专注于商业智能BI、数据分析、数据挖掘和大数据技术的垂直社区平台。
问答社区和在线学院是国内最大的商业智能BI 和大数据领域的技术社区和在线学习平台,技术版块与在线课程已经覆盖 商业智能、数据分析、数据挖掘、大数据、数据仓库、Microsoft BI、Oracle BIEE、IBM Cognos、SAP BO、Kettle、Informatica、DataStage、Halo BI、QlikView、Tableau、Hadoop 等国外主流产品和技术。
线上活动:Friday BI Fly 每周五晚 20:30,技术和行业交流,30余个微信直播群互动交流。
线下活动:Saturday BI Fly 在全国各大城市巡回举办200人-500人规模的大数据沙龙交流活动,每月1-2次。
天善智能积极地推动国产商业智能 BI 和大数据产品与技术在国内的普及与发展


