卢育峰:推荐的介绍
大家好,我是卢育峰,途牛任职。说到推荐系统,我就流程方面来大致讲一下推荐的过程。
先说个题外话,大家平常都听音乐,不知道大家用QQ音乐多不多?之前用的酷狗还有咪咕神马的。现在我经常用QQ音乐,为什么呢?因为它有个功能非常的吸引我,没错就是它的猜你喜欢,它经常会推荐一些很好的音乐,有时候会推荐一些很让人惊喜的音乐,让人喜欢使用它的功能,这是从自身感觉到的推荐的魅力。
现在大家每天都可以收到各种推荐,新闻啊,游戏啊等等。例如:亚马逊、eBay、京东的商品推荐,Facebook的好友推荐,腾讯QQ朋友圈推荐,豆瓣猜你喜欢,网易云音乐等。
撇开行业来说,推荐已经被应用的很成熟了,已经有一些开源的推荐系统Mahout、EasyRecd、RapidMiner等 大家有兴趣可以去网上查查看。
当然使用这些开源的平台也需要一定的开发工作量,目前有很多企业已经将推荐做出了很棒的效果。相信大家都用过京东购物啊,我现在已经是黄金会员了。以京东的推荐系统来说,为京东整体带来近10%的订单量,表现非常的出色。
这就是好的推荐带来的商业价值。如何基于大数据的环境下实现个性化推荐,实现千人千面,吸引用户转化订单,是推荐需要达到的目的。
推荐可以做的产品有很多:猜你喜欢、个性化push、买了还买,看了还看,热门推荐等等,不同的推荐产品基于的场景也不相同,纵观各大主流的旅游网站如:途牛、携程、去哪儿、同程、驴妈妈等,除了热销的产品推荐之外,均有猜你喜欢这样的个性化推荐产品。
下面简单说一下我们做推荐系统的过程:
熟悉业务场景、整合服务资源
首先,我们要对我们做推荐的目的非常明确,没错就是提高转化率,提高商业价值,这是我们要做推荐的目的。其次,就是要清楚自身的资源情况,有多少服务器,有多少人力去投入。再次,需要了解业务场景,清楚什么可以做推荐什么不需要做推荐,推荐需要做到什么程度。最后,预先对数据的复杂程度及数据量级别有个估计。从数据计算层面来说:每天只有1GB的数据,几台机器就可以搞定了。如果每天有几百TB的数据,那么几台服务器就基本很难处理下来。基于这些基本状况的了解,对推荐系统也可以有一个大致的简单流程,如图所示:
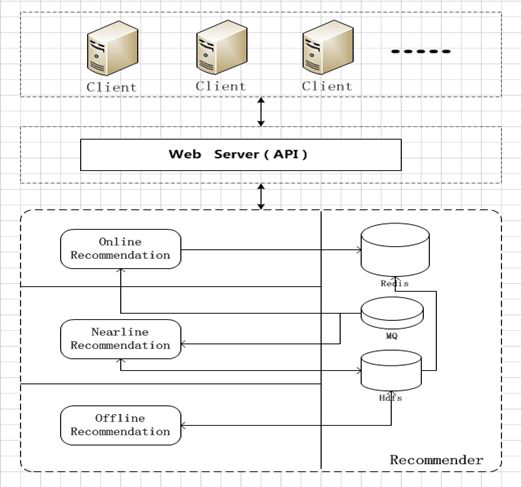
主要分为三个流:
1、实时推荐,能在用户访问的时候,迅速调整规则集合,尽快响应用户的访问行为提升推荐产品的更新效率和合理性。
2、近实时推荐,矫正实时推荐的产品的错误率,能更好的推荐相应产品。
3、离线推荐,提供丰富的离线推荐产品,有利于规则模型的训练。
结合三种推荐方式能很好的提升推荐的实时性、准确性及多样性,同时在考虑服务资源的时候需要周全。
先定义个大概的流式框架,下一步是技术选型。
推荐框架设计
结合我们现有的业务环境,网站访问量大,产品品类繁多,糅合团期概念的产品更加复杂,这些情况导致总体数据量非常庞大,从技术上来说,一般的传统数据也很难满足高效的数据处理。
我们用的sqlserver 第一版也是基于它推荐效果延时太长。
基于现有的大数据平台以及多角度的考虑各种大数据处理技术的优劣情况,我们选择Flume+Kafka+Storm+Spark+Hbase来实现实时推荐。
说下为什么选择这么选型,先说说各个工具的优势:
Flume从OG到NG之后,从分布式日志收集系统转型到数据传输工具,不仅支持Memory还支持File的数据传输,数据传输的稳定性更好,Flume变得更加灵活轻便、扩展性更好,而且在功能上更加强大,更容易集成Jdbc、Hbase,数据可以直接写入到Hdfs。
Kafka作为高吞吐高性能的分布式系统,支持大量数据的快速传输,能长期保持稳定,并且支持KafkaServer间的消息分区。
Storm主要是处理实时流式数据,它的特点是可靠性好,容错较强,每个组件负责一项特定的处理任务结构比较清洗,处理效率非常快,重点是编写容易,支持几种语言。
这几种工具组合是推荐比较成熟的选型,Flume与Hadoop可以很好的整合,Storm可以直接调用Kafka的接口,那么自然就是Flume+Kafka+Storm+Hbase的组合,除此之外,近实时的数据处理,无疑Spark是个很好的选择,虽然Storm处理一个事件可以达到秒内的延迟,但是Storm无法做数据批处理,仅仅是接收数据,简单的实时处理就分发出去。Spark能基于内存运算做某个时间段内的小量批处理,达到近实时效果。
再上个图,大家先view一下,可以指正啊。
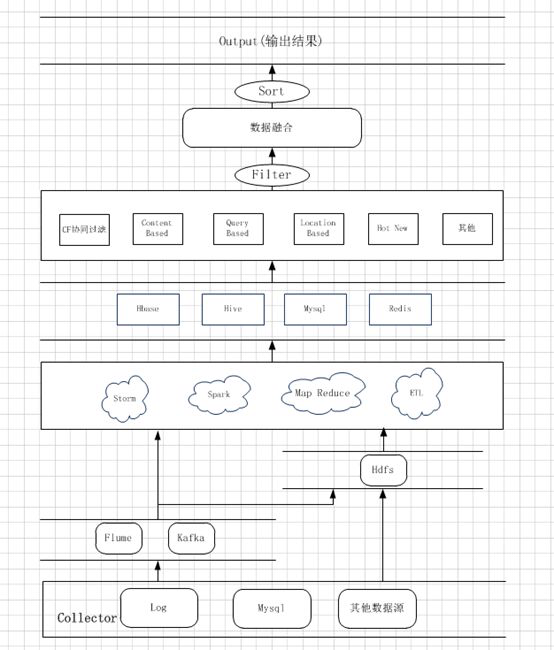
这个框架主要包括这几个流程:数据收集、数据清洗、数据存储、训练模型、筛选排序、输出结果(其中包含参数调优,落地实现等)。
通过网络日志收集、生产库以及其他方式得到数据,数据经过加工处理存储到HDFS文件系统,再经过算法训练模型,通过模型规则产生相应的候选数据集合,最终推送到缓存中,通过push通道或者接口推荐给用户。
流程和模型设计好了,下面是数据准备了。当然算法也是我们后续要考虑到的。
数据准备
首要考虑的是业务场景,其次是数据,其实两者都是一样重要的。
推荐的核心是数据,第一步我们要了解数据,我们有什么的数据,我们还能获取什么数据,根据相应的数据才好了解合适的推荐算法。
先说一下我这边推荐有准备的数据,主要有6个来源。
1、网站行为:搜索、浏览、下单、支付、收藏等
用户访问网站或者APP各种操作行为,这些操作行为可以为离线和事实提供很好的支持,不同的操作行为也具有不同的用户意图,用户的行为倾向也是可以从中识别的,尤其是在线行为能快速更新较为落后的规则,加强推荐的及时性。
2 用户画像:注册填写,出游相关补充信息
用户画像是通过用户的基础属性、社会属性等经过挖掘提炼所获取到的,用户画像带有行业特征,不同行业的用户画像的倾向点不同,旅游行业自然是会带有旅游相关的标签了,比如:出游行程长短、目的地类型偏好等,这些属性对某些推荐可以进行权重配比,对重排序也可以作为feature来用。
3、 产品标签:目的地方向提炼,产品主题抽象等
产品标签是推荐的非常核心的属性,旅游行业主要几种在行程的主题概念的提炼、目的地的划分、日程、价格等。主题主要凸显在旅游的特色,类似蜜月、亲子、毕业以及留学等等,这些主题的划分能很好的从时段归纳产品的类别,给各个时段的用户推荐;目的地划分可以划分出境、国内、当地等,对有出境意愿的用户,我们可以仅仅只推荐出境相关的产品;产品的其他几个属性也是比较影响模型训练的,如:价格、团期、行程安排。
4、负反馈:取消收藏、负点评、取消订单、投诉等
用户的负面反馈反映了某些方面给用户带来不好的体验,可能是产品的质量或者产品的服务,有可能是某些旅游产品看了一段时间出游的团期没有合适的,然后取消关注。这些负反馈可以用于对某些feature降权,或者可以作为feature用于模型的训练,以减少推荐不合适的产品,提高用户的体验。
5、UGC(UserGenerated Content):点评、攻略、游记、BBS等
通过用户对产品的点评、游记体验以及产品攻略的分析,用文本挖掘或者分词技术可以提取非常多的关键词和用户特征,可以用于用户的情感分析和个性化标签。
6、其他数据,有一些数据是比较难以获取的,比如社交信息等。若想获取社交信息,可以基于一些营销手段来刺激用户相互推送消息来获取社交关系,或者从第三方获取到相关信息。
以上是一些数据来源准备。遇到的两个难点就是, 一个是用户画像,如何打上合适的标签,另外一个是旅游行业有团期的概念(出游日期),对产品的团期和价格的前期处理也尤为重要。
数据预处理
光有数据也不行,还需要高质量的数据,高质量的数据可以提高推荐的效果,数据预处理也算是一个大工程,有效的预处理能使得数据挖掘事半功倍,一般底层数据存在空缺、不一致、重复、含噪声、维度高等问题,如果不把这些问题处理掉,会对整个挖掘的效果产生一定影响。数据预处理包含数据清洗、数据集成、数据变换和数据归约几种(其中部分是在做数据收集的时候就可以操作的)。
数据预处理的人工干预是非常多的,少数部分还是需要特殊办法去处理,其中数据集成、空值填补、归一化等用的比较多。数据预处理不多说,想了解的可以私下交流。
推荐算法
下面简要的说一下算法哈,万法归宗,算法主流:分类、聚类、关联。
目前的推荐算法比较多,一般来说有这样几种:协同过滤推荐、基于内容推荐、LBS、基于分类推荐、关联规则推荐、基于聚类推荐、SVD 、基于社交推荐、基于知识推荐等。
当然其中有部分是基于KDD或者规则的。
在繁杂的算法中,如何选型是一个比较头疼的事情,实际上可以基于两个方面去考虑,一个是性能,一个是业务场景。如果服务器足够多,人力足够可以把每种算法和业务场景都作为候选集拿来验证结果,但是现实是你的资源非常少,所以呢,必须要先了解各种算法的特点和作用。
先就其中几个简单介绍一下:(其实网上有蛮多教程哦,可以看看天善的课程)[坏笑]
1、 基于内容推荐(Content-basedRecommendations) 根据用户以前买过的商品来推荐相关的商品,假若A用户对他去过的旅游地点有过喜好的判断,比如A喜欢旅游产品有购物项目,特别喜欢出境游不喜欢短途,基于用户喜欢来训练相应的模型,可以推荐一些相关的产品,比如:毛里求斯迪拜10日游+免税购物。
优点:用户之间是独立的,个性化强,能很快识别用户的新倾向。
缺点:冷启动问题,没有历史数据无法对新用户做相应推荐,无法挖掘用户潜在倾向。
2、 协同过滤(CollaborativeFiltering Recommendations):基于用户或者产品的推荐,基于用户:根据用户历史行为打分,来找出相似用户群体,若A与B是一个群体,A去过马尔代夫,还去过欧洲,B去过马尔代夫,会推荐B去欧洲。
优点:可以挖掘用户潜在倾向,推荐个性化,随着时间推移性能提高,自动化程度高。
缺点:扩展性差,依赖历史数据较强,初期效果较差;
3、 基于分类推荐(Naive Bayes): 基于用户的某些feature进行分类,按照类别进行产品推荐,比如A,B用户,A是iPhone,B是android,给A推荐高质量高价格产品,给B推荐性价比合适的产品。
优点:无需行业知识,可以发现新的item,解决冷启动问题。
缺点:个性化程度低 。
4、 基于地理位置(Location BasedService),基于LBS信息推送相关服务信息,比如周边的旅游景点、美食、购物、娱乐服务设施等。
LBS主要是做场景应用,提炼其中的feature 不是一个单独的算法。
5、 基于搜索内容推荐,可以根据用户的搜索关键词,来匹配相似结果,比如搜索了这个词的人也搜索那个词并且找到他想要的结果,那么可以反馈相应的产品提示给该用户。主要计算相似度。
6、 基于社交推荐,这是一种基于用户社交网络上的好友的推荐,如果用户的好友给他推荐相应的产品,那么用户更加偏好好友的推荐。
以上的推荐方法我们也做过一些尝试,单一算法的效果并不是很理想,需要组合考虑各种算法,通过加权、变换把多种推荐算法的结果集进行结合,通过组合避免和降低各个算法的弱势,突出算法的优势。
经过多次尝试到现在的组合算法,也是一步一步走过来的,根据具体的业务场景选择对应的算法,并进行迭代,选择计算性能满足要求、计算结果精度较好的几种算法进行组合,来实现自动化推荐系统。
产品相关算法:LR(Logistic Regression)、K-means、Item Based
用户行为算法:GBDT、User Based、ContentBased
冷启动算法:基于注册信息的NB(Naive Bayes),访问属性的NB
重排序算法: FTRL(Follow-The-Regularized-Leader)
这个是现有的推荐框架使用到的一些算法。
除了上述的算法之外,还需要一些统计的热门产品、新产品等作为候选集补充,并加入时间衰减因子,减少整个模型的历史推荐权重过大,让用户的新行为优先于历史行为。
最后一步就是部署上线,算法要可配置化,图像界面化,这样才是一个完整的产品,最终产出也要做一定的衡量,可以加入一些反馈统计指标:点击量、转化率、Recall、Precision、调度时长等来判断模型的好坏。
主持人:感谢育峰的分享,很给力,从熟悉业务场景、整合服务资源->推荐框架设计->数据准备->数据预处理->算法设计->模型上线,以及后续要通过反馈统计指标来判断模型的好坏及模型优化,完整的给大家说明了实现一个推荐系统的流程。我们清楚了这个流程,下一步我们就要具体实现了,下面我们有请同程吴文波给大家分享如何搭建一个集群的hadoop环境来高效的实现我们的精准推荐。

