原话题来自商业智能BI社区 关于数据仓库模型的选取和大家进行一个讨论
关于数据仓库模型的选取和大家进行一个讨论
各位朋友大家好,我做数据仓库有快3年的时间了,项目也做个几个,不大不小,相关资料也看了不少,现在想把自己的理解和大家进行一个讨论,想听听大家的看法,说的对错请大家指点。
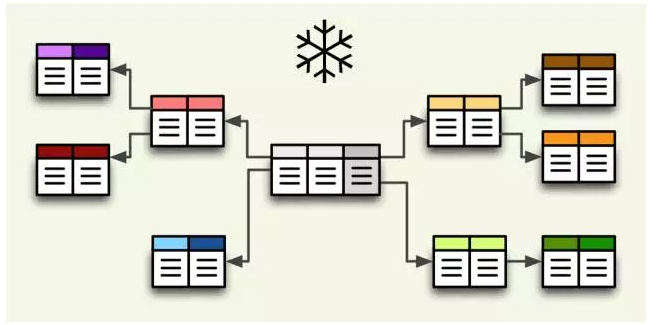
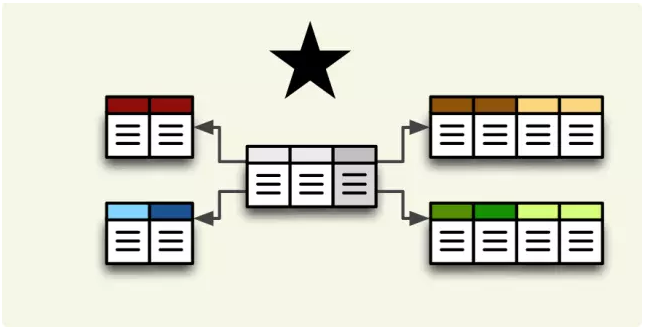
关于星型和雪花型的选取,有的资料上推荐使用星型,有的推荐使用雪花,个人认为还是星型结构值得推荐,虽然有的时候使用雪花有他的优点,但是我个人认为,雪花的优点,星型结构也可以规划业务维度、ETL过程处理掉。作为大数据量的数据集、效率还是王道。星型的效率(层次结构一样)应该会远高于雪花,不知道我这么理解是否正确,请各位指点。
参与话题讨论的有 BIWORK、老头子、XPIVOT、BAO胖子、微软BI
BIWORK 的观点:
个人理解:
星型模型和雪花型模型没有绝对的谁好谁不好之分,都是维度建模的一种设计思想,只是看在什么情形下使用。
星型模型的提出主要是方便业务人员理解业务模型,通过什么样的维度来看数据,星型模型更加直观,并且查询效率高。雪花型模型对于业务人员来说直观程度不够,并且在查询上效率略低。
但是我来举一个反例。
日-月-年,产品-产品小分类-中分类-大分类,国家-省份-地区 加一个事实度量。如果每一个日,月,年类似于这样的都是一张维度表的话,就意味着这张事实表的外键涉及到上述所有的维度,变成 10 个外键维度和一个事实度量。可以想象一下这样的事实就如同一条蜈蚣一样形成了一个蜈蚣事实表,维度外键过多,虽然是星型模型但是实则并不好。
退一步说,这张事实表只关联到日,产品,地区这三个维度,日-月-年 成为日期维度的一部分属性,这种情况最终三个维度+一个事实,这种星型模型要稍微好一点。
我继续基于这个星型模型再来说明,我假设在产品维度中(产品-小分类-中分类-大分类) 假设小分类,中分类,大分类各有5个非重复的值,但是却有10W个产品。也就意味着在产品维度中,小分类-中分类-大分类差不多要重复10W次。 也就意味中如果要统计分类的量需要从这10W条里面做去重统计操作,这种做法我认为效率很低。
再次,如果小分类,中分类,大分类不仅仅是一个标签而且还包含着标签描述信息和其它的属性,可想而知在星型模型下的处理方式就只能扩展同样重复的字段,这种重复率随着需要补充描述的属性越多变得越高。反之,如果再把这些单个的小分类,中分类拉出去形成维度和事实度量值构成一个星型模型,就又回到我刚才说的蜈蚣表了。
所以,没有最好的设计,只有最合适的选择,我们就从上面的几个设计推演就能考虑很多星型模型的弊端,在很多时候不一定就是最好的。
老头子 To BIWORK:
虽然我赞同你的最后结论观点,没有最好的模型,只有最合适的模型。
但是你的例子举得有点问题,
1.不知道“蜈蚣表”这个词为什么会出现,但是我想说的是所谓星型模型,如果你分成左右两侧看,确实比较像蜈蚣,星型模型的特性就是如此,中间一个事实表、关联很多维度表,事实表的模型就是一堆ID+事实数据,这个并没有什么太大的问题。
2. 你说的产品去重,如果是在数据库中实现,这个效率并不低,有非常高效的方法实现。如果在报表筛选器中实现,完全可以使用常量代替,而不从数据库中查询。
3. 数据仓库本身就是冗余的,其次作为数据仓库的服务器不是那么脆弱的,硬件如果太差就不要做BI了,OLAP、OLTP还是有区别的,从性能角度出发,OLAP系统是历史性的,低并发的,大数据量的。
所以从用户的体验出发,星型模型则相对更好。从DBA的角度出发,雪花模型则相对更好。
个人言论,请指正。
BIWORK to 老头子:
握个爪先,相亲相杀:
首先,站在用户角度优先考虑星型模型这个肯定没有错的,避免使用雪花模型这个观点我最开始就已经说明了的,这个大家应该都认同。
但是分歧在于是不是什么时候都一定要选择星型模型?
1. 蜈蚣表的概念在 Kimball 维度建模中很早就已经提出来过,我只是举了一个极端的例子,这个例子在我的第二步描述中已经解决了。
2. 你说的这种常量代替,只要有常量就一定需要人手工维护,更新 MAPPING 表,不知道你说的常量是不是这个意思。
3. 数据仓库冗余是没有错,星型模型就是冗余表。还是那一个案例,在产品维度表中有1000W笔产品记录,产品-小分类-中分类-大分类。每个分类去重大约5-10种,除了自身标签之外,还有各自分类的描述信息以长文本类型为主,以及分类等其它属性。你可以试想一下这个维度要存放多大的冗余?并且这些描述信息在80%到90%的查询中可能都用不上。另外当这种附加信息更新的时候就意味着每一笔产品都要发生更新,单表更新千万级重复字段至少这种结构从数据库设计上来来说就不是合理的。正确的做法就是应该拉出去,形成一个雪花维度模型,减少这种相对冗余以及更新的频率。
所以我觉得在设计阶段不要一味遵循星型模型至上的原则,某些场景下雪花模型比星型模型更合理。
至于用户体验,可以完全在数据展现阶段将雪花型还原成星型模型这个没有什么困难,并且这种关联查询效率也不低。最后的数据分析对象一定是一个宽的二维表,打破再还原这种成本我觉得并不高。
老头子 To BIWORK:
所以我觉得在设计阶段不要一味遵循星型模型至上的原则,某些场景下雪花模型比星型模型更合理。--这句是对的。
用什么模型要结合业务和用户,两者混合也是有可能的。
BAO胖子 To 老头子:
其实设计的时候基本都不太考虑到底是星型还是雪花,自然而然
XPIVOT To BAO胖子
我也推崇无招胜有招,基于对存储引擎工作原理以及业务场景的透彻理解,看似没有章法的设计未必糟糕,剑走偏锋也能出奇制胜。
BAO胖子 To XPIVOT
不过还是建议先规范化,再逆规范化,要不然有些复杂的情况容易出现设计问题,而且可能就设计者一个人知道怎么回事,后来的人会理不清数据之间的关系。
BIWORK To BAO胖子
比较同意先规范化再你规范化的说法 @XPIVOT “看似没有章法的设计未必糟糕,剑走偏锋也能出奇制胜”估计能让我的一些数据仓库的糟糕的设计找到一个台阶下了,哈哈!
老头子的观点:
雪花模型在报表的查询SQL中必定会设计多表关联,在业务逻辑复杂的情况下多表关联会导致Oracle CBO的错误评估,导致错误的执行计划,从而报表查询缓慢,尤其biee这种自动生成SQL的报表工具,所以星型模型会有更好的用户体验,当然也就导致了部分数据冗余,看你关注什么咯~
BAO胖子的观点:
如BIWORK所言,所谓模型无非也是根据实际情况而定,具体问题具体分析。
相比雪花模型,星型模型最大的问题是会带来数据不一致的隐患,而当维度表很大时,这个就比较成问题。另外还有一个问题就是,星型模型创建时,忽略和维度与维度之间的关系的描述,而将这种关系都体现在数据里,如果没有很好的模型管理,年深日久这些信息就会丢失以及出现问题。
此外,报表下拉时,需要从小表中取数,而不能从大维表里面做distinct,所以小表还是非常有必要保留的。
星型模型的好处是,非常有利于诸如BO, Cognos, BIEE这类需要语义层搭建的报表工具,会使模型简单而易于维护,而且这种模式下自动生成的SQL更容易优化,如果都按3NF模式来建,很多时候模型复杂得难以维护。
另外,蜈蚣表产生的原因很多是为了解决多对多的问题,不完全是星型模型引起的,即使是雪花模型也会有类似的问题。
和@老头子 观点也有些不一致的地方,OLAP并不代表低并发, 对于全民BI的系统而言,并发查询是非常高的。而报表筛选一般没有静态写入下拉列表的模式,都是动态从表中获取。
老头子 To BAO胖子:
全民BI这一点确实会相对高一点,但是相比OLTP这种事物系统相比还是差远了。即便是很多人用,用的频率也不会高,所以对系统的负载也不是并发访问给的。
参考x为xxBI系统,UV和PV的比例来看,频次比例比人次比例要低很多。
BAO胖子 To 老头子:
BI肯定是无法和OLTP比并发的,但所需要扫描的数据量也和OLTP不一样。也要看BI系统被开发成什么样子了,或者有的时候已经不能叫BI了,渗入到业务系统里面去了,跳开报表的展现模式去看就好了
老头子 To BAO胖子:
要看BI系统被开发成什么样子了,或者有的时候已经不能叫BI了----这一点无法再赞同。。。有些业务用户以为BI是万能的,要做搜索、做实时、做分析、做大数据,啥都要。
BAO胖子 To 老头子:
已经在变了,跳出报表思维,只是互联网这方面走的更早,传统企业晚一些,但人民群众的需求一直在那
老头子 To BAO胖子:
BI始终是BI,不是搜索引擎,不是大数据,不是监控,也不是ERP,用户有需求应该是有更符合需求的东西出现,而不是一味的给老的东西施压。曾经就接到过一个用户的需求,我说实现不了,对性能有极大影响,结果他说了一句“为什么百度可以实现”。。。 有时候真的是欲哭无泪,企业用一个产品首先要认识清楚这个产品的作用域,而不是上了BI就无脑提需求。
BAO胖子 To 老头子:
业务层的BI(所谓的Operational BI)会有很多不同,要结合到业务系统里面,这个没办法,客户的需求就是如此。BI这种东西一铺下去,性能的问题一下就凸显出来了,有些产品也扛不住高并发。保不齐哪天谁又发明出来个新名词,把这些需求重新归类。客户的需求不是问题,问题是他们又不肯多出钱...
微软BI 的观点:
都在讨论星形和雪花形,咱们多多少少也都用过。各自的优缺点在哪里。
有没有谁接触过其他的数据仓库模型的?
BAO胖子 To 微软BI:
还有Data Vault和Anchor, Data Vault适合多变的系统接入以及Data Audit, Anchor是6NF,不看也罢
每周、每天在商业智能 BI 社区都上演着这些不同观点的碰撞,每一个版区从商业智能、微软BI、Cognos、BIEE、ETL(Kettle、Informatica、DataStage)、QV、SAP BO 到大数据,只要你关心的我们都有,快到社区来与各位社区专家和热心网友一起碰撞共同提升吧。
商业智能 BI 社区有你更精彩 www.flybi.net