1. Job 和 Stage 靠什么关联?
SELECT
A.*
FROM
XMETA.DATASTAGEX_XMETAGEN_DSSTAGEC2E76D84AS A,
XMETA.DATASTAGEX_XMETAGEN_DSJOBDEFC2E76D84AS B
WHERE
A.NAME_XMETA = 'stage name' and
B.NAME_XMETA = 'job name' and
A.CONTAINER_RID=B.XMETA_REPOS_OBJECT_ID_XMETA
2. Transformer中这种玩意存在哪?
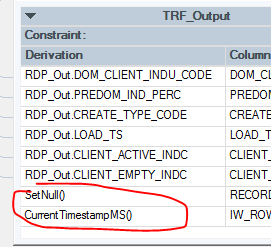
select
a.DSNAMESPACE_XMETA Projname,
a.category_xmeta folder_name,
a.NAME_XMETA as Job_Name,
b.name_xmeta as Stage_Name,
d.name_xmeta Link_Name,
e.sourcecolumn_xmeta Target_Column,
e.expression_xmeta Transformation
from
xmeta.DATASTAGEX_XMETAGEN_dsjobdefc2e76d84 a,
xmeta.DATASTAGEX_XMETAGEN_dsstagec2e76d84 b ,
xmeta.DATASTAGEX_XMETAGEN_dsoutputpinc2e76d84 c,
xmeta.DATASTAGEX_XMETAGEN_dslinkc2e76d84 d,
xmeta.DATASTAGEX_XMETAGEN_dsderivationc2e76d84 e
where
a.xmeta_repos_object_id_XMETA =b.container_rid and
c.container_rid = b.xmeta_repos_object_id_xmeta and
c.xmeta_repos_object_id_xmeta = d.from_outputpin_xmeta and
d.xmeta_lockingroot_xmeta=e.xmeta_lockingroot_xmeta
and B.NAME_XMETA = 'stage name'
and A.NAME_XMETA = 'job name'

3. 想知道一个infosphere server中,有哪些用了DB2 Connector的job怎么办?
Reference from: http://www.dsxchange.com/viewtopic.php?t=153788&sid=c9e913984e22d67b76c406e8b854e36f
SELECT J.DSNAMESPACE_XMETA AS PROJECT_NAME,
J.NAME_XMETA AS JOB_NAME,
J.CATEGORY_XMETA AS JOB_CATEGORY,
S.NAME_XMETA AS STAGE_NAME,
L.NAME_XMETA AS LINK_NAME,
'TARGET' AS CONNECTOR_USAGE
FROM XMETA.DATASTAGEX_XMETAGEN_DSJOBDEFC2E76D84 J,
XMETA.DATASTAGEX_XMETAGEN_DSSTAGEC2E76D84 S,
XMETA.DATASTAGEX_XMETAGEN_DSLINKC2E76D84 L,
XMETA.DATASTAGEX_XMETAGEN_DSINPUTPINC2E76D84 I
WHERE S.CONTAINER_RID = J.XMETA_REPOS_OBJECT_ID_XMETA
AND L.CONTAINER_RID = J.XMETA_REPOS_OBJECT_ID_XMETA
AND I.CONTAINER_RID = S.XMETA_REPOS_OBJECT_ID_XMETA
AND I.ISTARGETOF_LINK_XMETA = L.XMETA_REPOS_OBJECT_ID_XMETA
AND S.STAGETYPE_XMETA = 'DB2ConnectorPX'
UNION ALL
SELECT J.DSNAMESPACE_XMETA AS PROJECT_NAME,
J.NAME_XMETA AS JOB_NAME,
S.NAME_XMETA AS STAGE_NAME,
L.NAME_XMETA AS LINK_NAME,
'SOURCE' AS CONNECTOR_USAGE
FROM XMETA.DATASTAGEX_XMETAGEN_DSJOBDEFC2E76D84 J,
XMETA.DATASTAGEX_XMETAGEN_DSSTAGEC2E76D84 S,
XMETA.DATASTAGEX_XMETAGEN_DSLINKC2E76D84 L,
XMETA.DATASTAGEX_XMETAGEN_DSOUTPUTPINC2E76D84 O
WHERE S.CONTAINER_RID = J.XMETA_REPOS_OBJECT_ID_XMETA
AND L.CONTAINER_RID = J.XMETA_REPOS_OBJECT_ID_XMETA
AND O.CONTAINER_RID = S.XMETA_REPOS_OBJECT_ID_XMETA
AND O.ISSOURCEOF_LINK_XMETA = L.XMETA_REPOS_OBJECT_ID_XMETA
AND S.STAGETYPE_XMETA = 'DB2ConnectorPX'
ORDER BY 1, 3, 2, 4
WITH UR
Tips Sharing
附件中是所有DS Metadata的表/字段信息,我把我当前开发环境的各个Table的count统计进去了,作为参照,对于这种啥说明说都没有的表结构,我的学习思路一般是:
1. Google,找一些入手点。是的,确认是google,不是baidu
2. 查这种库的view, 从view的ddl中判断各个表之间的关系
3. 按名字猜,再查看数据验证自己的猜测
4. 按table的row count统计,根据数据规模以及配合table name猜表的含义,并定优先级,对于数据量大或者数据量小做不同的猜测。
比如,滤掉所有cnt为0的table
比如,这种ETL产品,对于数据量最大的,一般都是log表之类的东西
比如,数据量很小的,一般都是reference表
5. 猜到几个表的含义后,尤其对于master表,reference表,按照他们的pk,去其他表中找fk,层层展开分析
6. snapshot分析法,自己安装一套干净的环境,安装完成以后用个程序把当前所有表的rowcount记录一下,插入一个事先建好的snapshot表
然后做一个你想要分析的操作,比如增加一个job,里面是空的,没有stage,然后再snapshot一下所有表的rowcount,再和前面的结果比对,数据量有变化的,就是你这次操作中,系统对数据库的对应的操作。然后按这个线索一步一步的做下去,比如逐步增加stage,运行,之类。
---未完,待续---
推荐本人发布的课程:
数据仓库建模指南系列教程
上线日期:2016-01-17
目前:508 观众

