当单台数据库的数据量太大而影响性能时,可以把数据拆分到多台服务器上,每台服务器只承担部分计算压力,再由SPL合并计算结果。特殊地,数据可拆分为历史数据库和当前实时数据库,由SPL实现T+0计算。下面用几个典型例子来说明分库汇总的用法。
过滤
订单表orders分库存储在两个Oracle数据库中,数据源名分别为orclA、orclB,请过滤出金额amount大于等于10000的订单。
SPL代码如下:
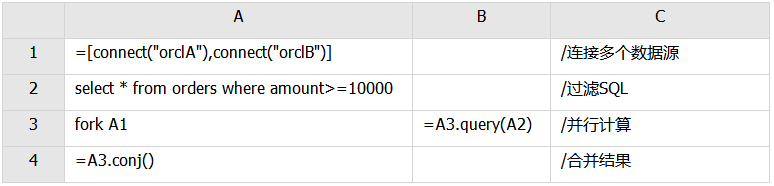
排序
请过滤出金额大于等于10000的订单,并按订单金额顺序排序。
分库排序算法中,各线程的计算结果不能简单合并,而要用merge函数归并,SPL代码如下:

分组汇总
请将订单表按年、月分组,对各组数据的amount字段求和。
分库分组汇总算法中,合并后的数据要做二次分组汇总,SPL代码如下:

如果分组数较多,则应当利用有序来提高性能,具体做法是:在SQL中事先按分组字段排序,使SQL结果有序,之后使用归并算法合并数据,并用group@o分组汇总。SPL代码如下:

分组汇总后过滤
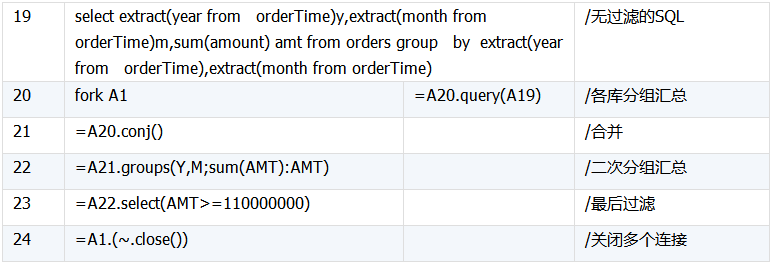
请将订单表按年、月分组,对各组数据的amount字段求和,再过滤出汇总值大于110000000的结果。
SQL实现本算法,通常在group by后带having语句,即:
select extract(year from orderTime)y,extract(month from orderTime)m,sum(amount) amt from orders group by extract(year from orderTime),extract(month from orderTime) having sum(amount)>=120000000
分库实现算法时,不能直接使用上述SQL,应该先实现分组汇总算法,再用SPL实现过滤。代码如下:
异构库分库
SPL除了支持同构库分库,也支持异构库分库。需要注意的是,不同数据库的SQL语法并不通用,比如数字截断函数,Oracle中写作trunc,在MySQL中写作truncate。为了正确处理不同的语法,应当先写出SPL标准SQL,再用SPL的sqltranslate函数翻译成不同的本地SQL。
比如:orders表分库存储在Oracle和mysql中,数据源名为orcl和my,请查询amount字段大于等于10000的记录,并将amount字段截断取整。
SPL代码如下:

连接
除了单表分库计算,SPL也支持多表连接分库计算。这种情况下应对事实表和维表分别处理,事实表应当分库存放,每个数据库存放一部分数据,维表不分库,应当全量复制到每一个数据库中。
比如销售人员表sales是订单表orders的维表,两者以salesID为关联字段,请按sales表的部门字段dept分组,求各部门的销售额。假设sales表已全量存储于各数据库,则SPL代码如下:

