1、最邻近算法
KNN方法的简单描述:KNN方法用于分类,其基本思想如下。我们已经有一些已知类型的数据,暂称其为训练集。当一个新数据(暂称其为测试集)进入的时候,开始跟训练集数据中的每个数据点求距离,挑选与这个训练数据集中最近的K个点看这些点属于什么类型,用少数服从多数的方法将测试数据归类。
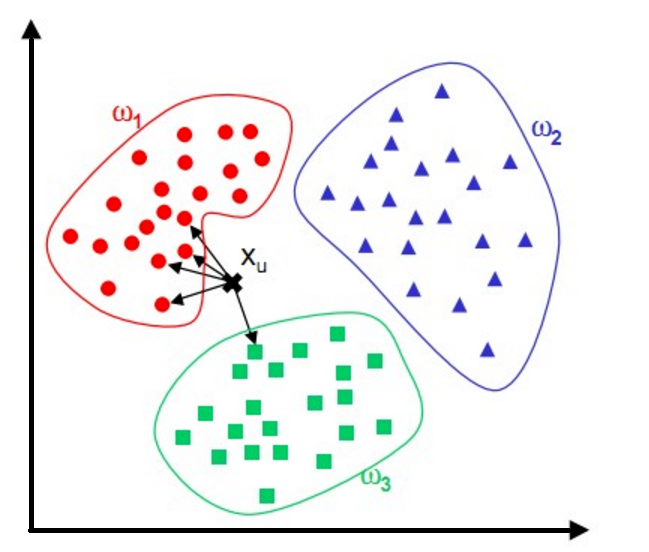
图示:这里我用一个常见到的图做介绍:1、有三类已知数据集(训练集),它们分别属于w1、w2、w3,这三类数据分别有自己的特征;2、有一个位置类别的数据(测试集)Xu;3、通过求Xu点到所有训练集数据的距离,取距离最近的n个点,查看这n个点所归属的类别,以少数服从多数的方式将Xu归类到已知训练集下
2、python实现最邻近算法案例
这里我构造了一个150*5的矩阵,分别代表三类数据。每行的前四个值代表数据的特征,第五个值代表数据的类别。如图:
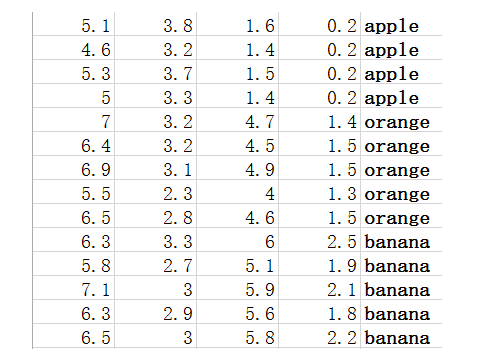
这三类数据分别属于apple、banana、orange
第一步:加载数据。以split参数传来的参数为限,将小于split的随机数对应的数据划分到训练集,将大于split的随机数划分到测试集
def loadDataset(self,filename, split, trainingSet, testSet): # 加载数据集 split以某个值为界限分类train和test
with open(filename, 'r') as csvfile:
lines = csv.reader(csvfile) #读取所有的行
dataset = list(lines) #转化成列表
for x in range(len(dataset)-1):
for y in range(4):
dataset[x][y] = float(dataset[x][y])
if random.random() < split: # 将所有数据加载到train和test中
trainingSet.append(dataset[x])
else:
testSet.append(dataset[x])
第二步:对每个测试集中的数据进行迭代,取其临近点。
计算测试集中每个点到训练集中每个点的距离,将这些距离按从小到大进行排序,取最近的k个点作为归类点
def getNeighbors(self,trainingSet, testInstance, k): # 返回最近的k个边距
distances = []
length = len(testInstance)-1
for x in range(len(trainingSet)): #对训练集的每一个数计算其到测试集的实际距离
dist = self.calculateDistance(testInstance, trainingSet[x], length)
print('{}--{}'.format(trainingSet[x], dist))
distances.append((trainingSet[x], dist))
distances.sort(key=operator.itemgetter(1)) # 把距离从小到大排列
neighbors = []
for x in range(k): #排序完成后取前k个距离
neighbors.append(distances[x][0])
return neighbors
计算距离函数
def calculateDistance(self,testdata, traindata, length): # 计算距离
distance = 0 # length表示维度 数据共有几维
for x in range(length):
distance += pow((testdata[x]-traindata[x]), 2)
return math.sqrt(distance)
length表示维度,这里数据是4维
第三步:判断那k个点所属的类别,选择出现频率最大的类标号作为测试集的类标号
def getResponse(self,neighbors): # 根据少数服从多数,决定归类到哪一类
classVotes = {}
for x in range(len(neighbors)):
response = neighbors[x][-1] # 统计每一个分类的多少
if response in classVotes:
classVotes[response] += 1
else:
classVotes[response] = 1
print(classVotes.items())
sortedVotes = sorted(classVotes.items(), key=operator.itemgetter(1), reverse=True) #reverse按降序的方式排列
return sortedVotes[0][0]
计算距离:

结果:

代码和测试数据点这里 :密码:iaqr
如果嫌下载麻烦,这里是全部code:
# -*- coding: UTF-8 -*-
import math
import csv
import random
import operator
'''
@author:hunter
@time:2017.03.31
'''
class KNearestNeighbor(object):
def __init__(self):
pass
def loadDataset(self,filename, split, trainingSet, testSet): # 加载数据集 split以某个值为界限分类train和test
with open(filename, 'r') as csvfile:
lines = csv.reader(csvfile) #读取所有的行
dataset = list(lines) #转化成列表
for x in range(len(dataset)-1):
for y in range(4):
dataset[x][y] = float(dataset[x][y])
if random.random() < split: # 将所有数据加载到train和test中
trainingSet.append(dataset[x])
else:
testSet.append(dataset[x])
def calculateDistance(self,testdata, traindata, length): # 计算距离
distance = 0 # length表示维度 数据共有几维
for x in range(length):
distance += pow((testdata[x]-traindata[x]), 2)
return math.sqrt(distance)
def getNeighbors(self,trainingSet, testInstance, k): # 返回最近的k个边距
distances = []
length = len(testInstance)-1
for x in range(len(trainingSet)): #对训练集的每一个数计算其到测试集的实际距离
dist = self.calculateDistance(testInstance, trainingSet[x], length)
print('训练集:{}-距离:{}'.format(trainingSet[x], dist))
distances.append((trainingSet[x], dist))
distances.sort(key=operator.itemgetter(1)) # 把距离从小到大排列
neighbors = []
for x in range(k): #排序完成后取前k个距离
neighbors.append(distances[x][0])
print(neighbors)
return neighbors
def getResponse(self,neighbors): # 根据少数服从多数,决定归类到哪一类
classVotes = {}
for x in range(len(neighbors)):
response = neighbors[x][-1] # 统计每一个分类的多少
if response in classVotes:
classVotes[response] += 1
else:
classVotes[response] = 1
print(classVotes.items())
sortedVotes = sorted(classVotes.items(), key=operator.itemgetter(1), reverse=True) #reverse按降序的方式排列
return sortedVotes[0][0]
def getAccuracy(self,testSet, predictions): # 准确率计算
correct = 0
for x in range(len(testSet)):
if testSet[x][-1] == predictions[x]: #predictions是预测的和testset实际的比对
correct += 1
print('共有{}个预测正确,共有{}个测试数据'.format(correct,len(testSet)))
return (correct/float(len(testSet)))*100.0
def Run(self):
trainingSet = []
testSet = []
split = 0.75
self.loadDataset(r'testdata.txt', split, trainingSet, testSet) #数据划分
print('Train set: ' + str(len(trainingSet)))
print('Test set: ' + str(len(testSet)))
#generate predictions
predictions = []
k = 3 # 取最近的3个数据
# correct = []
for x in range(len(testSet)): # 对所有的测试集进行测试
neighbors = self.getNeighbors(trainingSet, testSet[x], k) #找到3个最近的邻居
result = self.getResponse(neighbors) # 找这3个邻居归类到哪一类
predictions.append(result)
# print(correct)
accuracy = self.getAccuracy(testSet,predictions)
print('Accuracy: ' + repr(accuracy) + '%')
if __name__ == '__main__':
a = KNearestNeighbor()
a.Run()

