作者:sergiojune
个人公众号:日常学python
专注python爬虫,数据可视化,数据分析,python前端技术
上一篇文章:利用python爬取网易云音乐,并把数据存入mysql
喜欢爬虫的伙伴都知道,在爬网站的内容的时候并不是一爬就可以了,有时候就会遇到一些网站的反爬虫,折回让你爬不到数据,给你返回一些404,403或者500的状态码,这有时候会让人苦不堪言,就如我昨天发的爬网易云音乐评论,在你爬的数据较多时,网站认为你是一个机器,就不让你爬了,网易云就给我返回了一个{"code":-460,"msg":"Cheating"},你不看下他的返回内容还不知道自己被反爬虫,不过不用担心,既然网页有反爬虫,可我们也有反反爬虫,今天就给大家说说反爬虫与反反爬虫。

1.通过网页的请求头
首先我们先看看网易云音乐评论的请求头
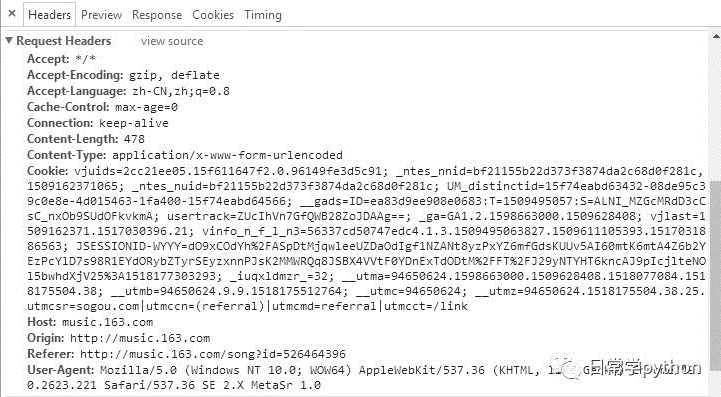
User-Agent:这个是保存用户访问该网站的浏览器的信息,我上面这个表示的是我通过window的浏览器来访问这个网站的,如果你是用python来直接请求这个网站的时候,这个的信息会带有python的字眼,所以网站管理员可以通过这个来进行反爬虫。
Referer:当浏览器发送请求时,一般都会带上这个,这个可以让网站管理者知道我是通过哪个链接访问到这个网站的,上面就说明我是从网易云音乐的主页来访问到这个页面的,若你是用python来直接请求是,就没有访问来源,那么管理者就轻而易举地判断你是机器在操作。
authorization:有的网站还会有这个请求头,这个是在用户在访问该网站的时候就会分配一个id给用户,然后在后台验证该id有没有访问权限从而来进行发爬虫。
2.用户访问网站的ip
当你这个ip在不断地访问一个网站来获取数据时,网页后台也会判断你是一个机器。就比如我昨天爬的网易云音乐评论,我刚开始爬的一首《海阔天空》时,因为评论较少,所以我容易就得到所有数据,但是当我选择爬一首较多评论的《等你下课》时,在我爬到800多页的时候我就爬不了,这是因为你这个ip的用户在不断地访问这个网站,他已经把你视为机器,所以就爬不了,暂时把你的ip给封了。

1.添加请求头
既然在请求网页的时候需要请求头,那么我们只需要在post或者get的时候把我们的请求头加上就可以了,怎样加?可以使用requests库来添加,在post,get或者其他方法是加上headers参数就可以了,而请求头不需要复制所有的信息,只需要上面的三个之中一个就可以,至于哪个自己判断,或者直接添加所有也可以,这样我们就可以继续爬了。
2.使用代理ip
若是网站把你的ip给封了,你添加什么的请求头也都没有用了,那我们就只有等他解封我们才可以继续爬吗?我可以十分自信告诉你:不需要,我们可以使用代理ip来继续爬,我们可以爬取网络上的免费ip来爬,至于免费的代理ip质量怎样你们应该知道,有必要可以买些不免费的,这样好点,我们平时的练习用免费的代理ip就可以了,可以自己爬取一些免费代理ip建成ip池,然后爬的时候就把ip随机取出来。
END
结束语:上面的只是个人在爬一些网站时候遇到的一些反爬虫,这只是很简单的,还有那些动态网站的反爬虫自己还没有接触,等到以后接触了,再一一补充。最后给大家在爬虫上的建议,就是爬取速度不要太快,最好每几个就隔几秒,不要给服务器造成太大的压力,也可以在爬虫的时候选择一些访问量少点的时间段,这是对服务器好,也是对你自己好!
Python爱好者社区历史文章大合集:
Python爱好者社区历史文章列表(每周append更新一次)
 福利:文末扫码立刻关注公众号,“Python爱好者社区”,开始学习Python课程:
福利:文末扫码立刻关注公众号,“Python爱好者社区”,开始学习Python课程:
关注后在公众号内回复“课程”即可获取:
小编的Python入门视频课程!!!
崔老师爬虫实战案例免费学习视频。
丘老师数据科学入门指导免费学习视频。
陈老师数据分析报告制作免费学习视频。
玩转大数据分析!Spark2.X+Python 精华实战课程免费学习视频。
丘老师Python网络爬虫实战免费学习视频。


