虽然从17年开始各地政府对房价进行了管控,二套房首付提高,利率上升,租售同权等政策,但是上海的房价居高不下,买不起,我看看还不行嘛,这次就来爬爬某网上上海的楼盘,练习一下如何用BeautifulSoup爬取数据。
一、页面信息查看
打开首页,按F12,点击左边这个图标,点击楼盘信息,出现对应的标签,所有信息在class="item-mod"下,
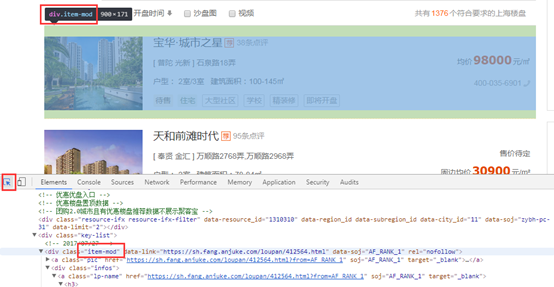
二、获取单个页面所有楼盘信息
import requests
from bs4import BeautifulSoup
# from pandas.core.frame import DataFrame
import pandas as pd
import xlwt
#获取所有信息
def get_lpdetail(url):
urllist = []
name=[]
address=[]
huxing=[]
price=[]
tag=[]
comments=[]
price_txt=[]
price_around=[]
res=requests.get(url)
res.encoding='utf-8'
#soup解析
soup=BeautifulSoup(res.content,"html.parser")
#class属性前面加.,
url=soup.select('.item-mod')
for ain url:
#print(a)
try:
#查找发现一页有60个class = item-mod标签,但是一页只有50个楼盘信息,所以有些item-mod标签并不是我们查找的内容
# 因此做了下面的if判断,h3标签对应楼盘名,因此我们判断,能找到楼盘名就能获取对应楼盘的信息
if len(a.select('h3'))> 0:
#获取name
if len(a.select('h3'))>0:
name.append(a.select('h3')[0].text)
else:
name.append('无')
#获取link
if len(a['data-link'])>0:
urllist.append(a['data-link'])
else:
urllist.append('无')
#获取地址
if len(a.select('.list-map'))>0:
address.append(a.select('.list-map')[0].text)
else:
address.append('无')
#获取户型
if len(a.select('.huxing'))>0:
huxing.append(a.select('.huxing')[0].text.replace('\r', '').replace(' ', '').replace('\n', '').replace('\t', '').strip())
else:
huxing.append('无')
#获取价格
if len(a.select('.price')) > 0:
price.append(a.select('.price')[0].text.replace('\r',',').replace(' ','').replace('\n',',').replace('\t',',').strip())
else:
price.append('无')
#获取价格文本,售价待定
if len(a.select('.price-txt')) >0:
price_txt.append(a.select('.price-txt')[0].text.replace('\r',',').replace(' ','').replace('\n',',').replace('\t',',').strip())
else:
price_txt.append('无')
#获取周边价格
if len(a.select('.favor-tag.around-price'))> 0:
price_around.append(a.select('.favor-tag.around-price')[0].text.replace('\r',',').replace(' ','').replace('\n',',').replace('\t',',').strip())
else:
price_around.append('无')
#获取标签
if len(a.select('.tag-panel'))>0:
tag.append(a.select('.tag-panel')[0].text.replace('\r',',').replace(' ', '').replace('\n',',').replace('\t',',').strip())
else:
tag.append('无')
#获取点评数
if len(a.select('.list-dp'))>0:
comments.append(a.select('.list-dp')[0].text.strip())
else:
comments.append('0条点评')
except:
continue
c={'name':name,'urllist':urllist,'address':address,'huxing':huxing,'price':price,'price_txt':price_txt,'price_around':price_around,'tag':tag,'comments':comments}
#以字典形式返回所有信息
return c
三、循环获取所有页面楼盘信息
#发现每一页的url规律
#https://sh.fang.anjuke.com/
#https://sh.fang.anjuke.com/loupan/all/p2/
#从第一页发现不了什么规律,从第二页发现规律,我们用第二页推第一页URL,https://sh.fang.anjuke.com/loupan/all/p1/发现返回的正是第一页的信息
#循环每一页获取所有页面的楼盘信息,存储到excel表格中
# 生成空的数据框
df=pd.DataFrame(columns=['name','urllist','address','huxing','price','price_txt','price_around','tag','comments'])
# print(type(df))
for i in range (1,29):
#构造URL
url='https://sh.fang.anjuke.com/loupan/all/p'+ str(i) +'/'
print(url)
detail=get_lpdetail(url)
data=pd.DataFrame(detail)
df = df.append(data,ignore_index=False)
df.to_excel('loupan.xlsx')
#保存为CSV
df.to_csv('loupan.csv',sep='|')
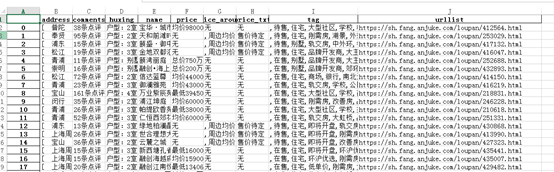
这就是整个上海楼盘的信息,爬完发现还是买不起,哈哈.....

