导读:相比于传统软件开发流程,机器学习开发更像是一个富有创造性的研究过程。
设计产品、编程实现、测试、修复漏洞、发布产品...... 敏捷开发在软件开发世界中无处不在。然而,机器学习开发更像是一个富有创造性的研究过程。
当然,这之间有很多相似之处,这里会简单罗列一下。
对于那些还没有自己亲手做过一个端对端(end-to-end)的机器学习解决方案的朋友们,我希望这个会对你们有所帮助。
1 明确你的期望,来确定回报率(ROI)
在机器学习中,我们的系统有一个明确定义的任务,比如说从图像上识别出文字。试想一下,如果我们有一个普通的基于规则的算法(还没有应用机器学习)来执行一个任务,比如说保险承保:如果它可以自动化70%的任务,但是应用了机器学习之后,准确率提高到了80%,那么是否可以判定为一个令人满意的增长?
操作建议:设定好一个投资回报的阈值。
2 明确目前最佳解决方案(state of the art)
在处理任何软件开发项目之前,我们都会对于现有解决方案、工具包、和算法等做一个研究。
机器学习项目也是一样,但是另外有很重要的一点就是要去看科学文献。
(State of the art :学术界对于一个特定问题目前最好的解决方案。比如说,目前在 MNIST 数字分类问题上,最高水平的解决方案是 0.21% 的错误率。)
操作建议:研究相类似问题的最佳解决方案,你可能不会做得更好,但这结果是否让人满意呢?

3 收集高质量的训练数据(但别太多)
对任何机器学习解决方案来说,最大的威胁就是没有足够的清晰、有意义的数据。

无论是欠拟合还是过拟合,对机器学习模型质量都是一个很大的挑战。 图片来源:coursera
有着过多噪音的数据会导致算法给出让人不满意的结果,也就是算法会从噪音中去学习。过少的训练数据会导致不足以对整个数据进行分布估计,也就是所说的欠拟合(underfitting)。
然而,获取更多的数据是一个代价很大的过程,并且往往在刚开始的时候不会注意到。所以在收集数据上做一个权衡也是很重要的。
操作建议:弄清楚多少数据是不需要过多代价就可以得到的,以及要得到更多的数据要多少成本(金钱和时间)。
4 预处理并拓展数据
让我们来想一下市场细分这个问题,也就是把消费者分成不同的群体。我们需要什么样的信息来确定哪一位顾客分为哪一类?显然,人口特征和消费记录会是两个不错的方面。

市场细分是一个热门话题——企业都想更了解自己的客户市场 图片来源:ExpressAnalytics
但如果数据是不相关的,比如姓氏和名字,它们就会给算法带来麻烦。
可是我们能不能(应不应该)再收集更多的特征(feature)?我们可能会想要利用社交信息或者相关推断来拓展消费者数据,比如说:根据他们的其它特征来给他们的收入进行分类。如果这方面做得好,我们甚至可以赢得美国总统大选。
操作建议:当你在处理这些学习问题时确定哪些特征是和问题相关的。你已经了解了哪些额外的信息?怎么样可以拓展数据?
5 多设计一些实验
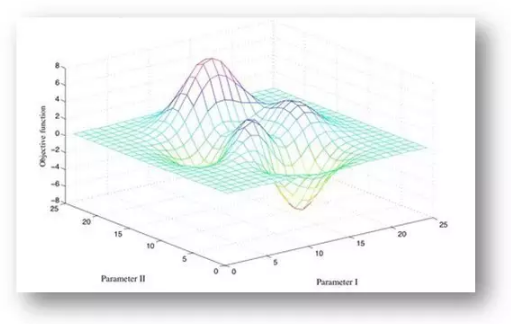
网格搜索(Grid search)是寻找机器学习模型最优参数的一个方法,这是开发机器学习模型的一个重要步骤。 图片来源:Medium
现在既然我们已经有了数据集,我们需要设计实验并且进行评估。
操作建议:
设计 10-20 组你想要的实验,尝试在限定的时间内对它们进行训练。
确定哪一对实验显著优于其他的实验,用网格搜索(或其它方法)来决定一个算法和超参数的最优组合。
6 优化你的最终算法
现在你已经获得了合适的算法和相关参数,来尝试着对它进行一些改进吧?
操作建议:
你的模型对于训练数据是否过拟合?如果是的话,获取更多数据来提升模型质量
还有没有更多的参数可以调校?
你对你的结果满意吗?尝试把你的模型部署到一个真实的生产环境中。面对真实世界的挑战,它会表现得如何?
来源:Medium
作者:Mariusz Kierski
翻译:张佳维
