早在几个月前就有朋友希望我讲讲R中caret包,其实该包蕴含了太多的数据分析和挖掘的功能,集成了上百种分类和回归算法。那会一直在安排和规划写这部分的内容,可惜身体突然出现状况,一下子就耽搁了好几个月,如今是时候写写有关caret包的介绍和应用了。
虽然该caret包含了N多种函数,但概括之,我认为其涉及如下6方面的内容:
1)数据预处理
2)数据分割
3)特征选择
4)模型搭建及评估
5)变量重要性估计
6)其他函数部分
这6个部分,我争取在3期中逐一讲解,本篇仅涉及caret包中的数据预处理和数据分割两个部分。首先来看看caret是如何实现数据的预处理,关于这部分,主我将从如下主要的6个方面介绍:
一、创建哑变量
如果你有一个因子型变量需要进行哑变量处理,你会怎么办?也许你会根据该变量的m个水平数构建m-1个哑变量,不错,这样的思路是没有问题的。但如果发现该变量确实很重要,而且水平数目非常多,那你一定会抓狂!如果你会caret包中的dummyVars()函数,那将如虎添翼,效率倍增~我们来看看该函数是如何实现哑变量构建的。
函数语法及参数介绍:
dummyVars(formula, data, sep = ".",
levelsOnly = FALSE,
fullRank = FALSE, ...)
predict(object, newdata, na.action = na.pass, ...)
formula:为一个数学公式,类似于y=x1 + x2 + x3,但R中的写法是y~x1 + x2 + x3。注意,公式右边请指定需要处理为哑变量的因子型变量
data:指定要处理的数据集
sep:设置变量与水平间的分割符,默认为实心点。如x.a,x就是变量名,a就是x的一个水平
levelsOnly:逻辑值,如果为True,则列名中剔除原变量名。如x.a变为a
object:为dummyVars()函数构成的结果
newdata:需要处理的新数据
na.action:缺失值的对待,变量水平中如果有缺失值,则结果仍为缺失值
例子:
library(caret)
dummy <- dummyVars(formula = ~ ., data = iris)
pred <- predict(dummy, newdata = iris)
head(pred)

有没有发现一个问题?因子型变量有多少个水平就会产生多少个哑变量,我觉得这也有好处,因为你可以随意的删除某个哑变量作为参照水平。
如果你的数据集中有许多因子型变量需要转换为哑变量,你总不能先找出所有因子型变量,然后再一个个写在公式的左边吧?下面提供一个小技巧:
set.seed(1234)
f1 <- sample(c('a','b','c'),100,replace = T)
f2 <- sample(c('f','m'),100,replace = T)
f3 <- sample(c('h','m','l'),100,replace = T)
x <- round(runif(100,1,10))
df <- data.frame(x = x, f1 = f1, f2 = f2, f3 = f3)
#筛选出所有因子型变量
facots <- names(df)[sapply(df, class) == 'factor']
#将因子型变量转换成公式formula的右半边形式
formula <- f <- as.formula(paste('~', paste(facots, collapse = '+')))
formula
dummy <- dummyVars(formula = formula, data = df)
pred <- predict(dummy, newdata = df)
head(pred)

大功告成,是不是很灵活,很简单的处理了哑变量的问题?不妨试试其中的逻辑和奥妙!
二、近零方差变量的删除
你曾经可能碰到这样一个问题,数据集中有某些变量的值非常稀少,而其他值可能又很多,例如性别字段,男有1000个观测,女只有10个观测。请问你如何处理这个变量?要么删除,要么保留。对于这种严重不平衡的数据,如果保留在模型内的话,模型的结果将会令你失望,且模型的稳定性也将大打折扣!是的,最好是把这样的变量删除,如果我有上千上万个变量,我总不能对每一个变量做一次table统计,然后人工判断吧?哈哈,现在拥有caret,你又能省去很多工作,我们不妨看看吧。
函数语法及参数介绍:
nearZeroVar(x, freqCut = 95/5,
uniqueCut = 10,
saveMetrics = FALSE,
names = FALSE,
foreach = FALSE,
allowParallel = TRUE)
nzv(x, freqCut = 95/5, uniqueCut = 10,
saveMetrics = FALSE, names = FALSE)
x:为一个向量或矩阵或数据框,需要注意的是,必须是数值型对象,如果是字符型的变量,建议转换为数值型的值,可通过factor函数实现
freqCut:为一个阈值,默认值为95/5,即最频繁的数值个数除以次频繁的数值个数。如上面的性别字段,990/10>95/5
uniqueCut:为一个阈值,默认值为10%,即某个变量中不同值的个数除以样本总量。如上面的性别字段,2/1000<0.1(根据近零方差的判断标准是,如果某个变量的freqCut超过了给到的默认阈值,并且uniqueCut低于给到的默认阈值,就认为改变量是近零方差的。)
saveMetrics:逻辑值,默认为False,如果为True的话会返回一个统计表,反映每个变量是否为零方差和近零方差
names:逻辑值,默认为False,如果为True的话,返回零方差和近零方差的变量名,否则返回对应的索引值
foreach:是否指定使用foreach包进行计算,如果使用,计算过程将消耗更少的内存,但会比较耗时间
allowParallel:是否指定使用foreach包进行并行运算,如果使用,将会消耗更多内存,但执行时间将更少
例子:
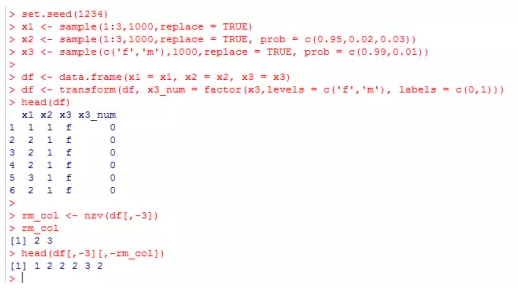
set.seed(1234)
x1 <- sample(1:3,1000,replace = TRUE)
x2 <- sample(1:3,1000,replace = TRUE, prob = c(0.95,0.02,0.03))
x3 <- sample(c('f','m'),1000,replace = TRUE, prob = c(0.99,0.01))
df <- data.frame(x1 = x1, x2 = x2, x3 = x3)
df <- transform(df, x3_num = factor(x3,levels = c('f','m'), labels = c(0,1)))
head(df)
rm_col <- nzv(df[,-3])
rm_col
head(df[,-3][,-rm_col])
三、删除高相关的预测变量和完全线性关系的变量
在某些模型算法中就明确要求变量间不能有高度线性相关的变量,因为这会导致模型非常敏感与不稳定,例如线性回归模型或基于最小二乘方法的其他模型一般度要求变量间尽量不存在线性相关性。那问题来了,我该如何检验并剔除高相关的变量呢?比较笨一点的办法就是对所有数值型变量计算一次相关系数矩阵,然后观测每一个相关系数,找出高相关的变量对,然后选择一个删除。哦,MGD,眼睛要累死了,如果你的变量有几十个甚至上百个,你还敢看吗?下面我们就来介绍caret包是如何简单的处理的。
函数语法及参数介绍:
findCorrelation(x, cutoff = .90,
verbose = FALSE,
names = FALSE,
exact = ncol(x) < 100)
x:为一个相关系数矩阵
cutoff:指定高度线性相关的临界值,默认为0.9
verbose:逻辑值,指定是否打印出函数运算的详细结果
names:逻辑值,是否返回变量名,默认返回需要删除变量的对应索引值
exact:逻辑值,是否重新计算每一步的平均相关系数
例子:
#返回相关系数矩阵中的上三角值
corr <- cor(iris[,1:4])
corr[upper.tri(corr)]

虽然能够一幕了然的看到那些相关系数是高相关的,但不能明确那组变量间是高相关的。
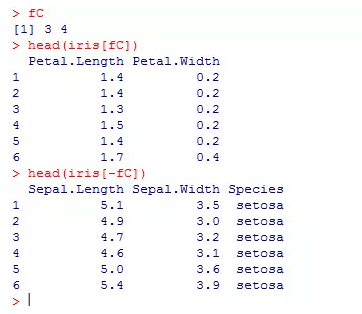
fC = findCorrelation(corr, cutoff = .8)
fC
head(iris[fC])
head(iris[-fC])
四、数据标准化处理
数据标准化处理的目的主要是消除数据由于量纲的原因导致数据差异过大,在建模过程中,有些模型就必须基于标准化后的数据才可使用,如层次聚类、主成分分析、K均值,一般基于距离的算法或模型都需要对原始数据进行标准化处理。caret包中的preProcess()函数就非常灵活的实现数据的标准化,我们来看看有关该函数的语法与应用。
函数语法及参数介绍:
preProcess(x,
method = c("center", "scale"),
thresh = 0.95,
pcaComp = NULL,
na.remove = TRUE,
k = 5,
knnSummary = mean,
outcome = NULL,
fudge = .2,
numUnique = 3,
verbose = FALSE,
...)
predict(object, newdata, ...)
x:为一个矩阵或数据框,对于非数值型变量将被忽略
method:指定数据标准化的方法,默认为"center"和 "scale"。其中center表示预测变量值减去均值;scale表示预测变量值除以标准差,故默认标准化方法就是(x-mu)/std。如果使用range方法,则数据标准为[0,1]的范围,即(x-min)/(max-min)。
thresh:如果使用主成分分析(PCA)方法,该参数指定累计方差至少达到0.95
pcaComp:如果使用主成分分析(PCA)方法,该参数可指定保留的主成分个数,该参数的优先级高于thresh
na.remove:默认剔除缺失值数据
k:如果使用k-近邻方法填补缺失值的话,可以指定具体的k值,默认为5
knnSummary:使用k个近邻的均值替代缺失值
outcome:指定数据集的输出变量,当使用BOX-COX变换数据时,该参数需要指定输出变量
fudge:指定BOX-COX变换的lambda值波动范围
numUnique:指定多少个唯一值需要因变量y估计BOX-COX转换
verbose:指定是否需要输出详细的结果
object:为preProcess对象
newdata:指定需要处理的新数据集
例子:
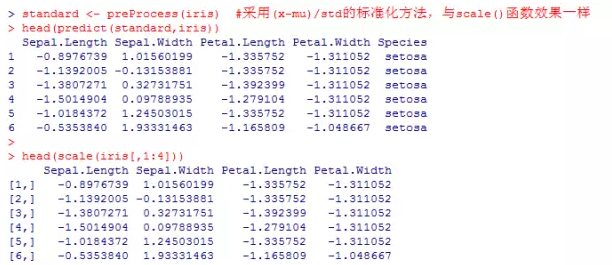
standard <- preProcess(iris) #采用(x-mu)/std的标准化方法,与scale()函数效果一样
head(predict(standard,iris))
head(scale(iris[,1:4]))
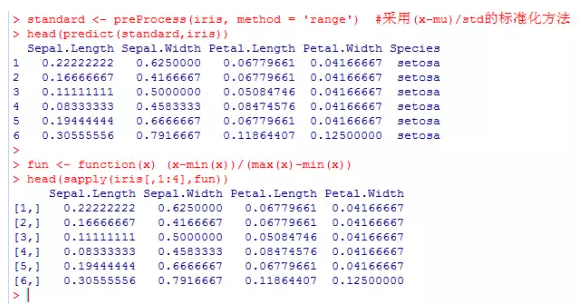
standard <- preProcess(iris, method = 'range') #采用(x-mu)/std的标准化方法
head(predict(standard,iris))
fun <- function(x) (x-min(x))/(max(x)-min(x))
head(sapply(iris[,1:4],fun))
五、缺失数据的处理
有关缺失值的处理,可以用上方介绍的preProcess()函数,该函数提供了三种缺失值填补的方法,即K近邻方法、Bagging树集成方法和中位数法。需要注意的是,采用K近邻方法时,会对原始数据进行标准化,如果需要返回原始值,还需将标准化公式倒推回来;使用Bagging树集成方法,理论上对缺失值的填补更权威,但其效率比较低;使用中位数方法,速度非常快,但填补的准确率有待验证。如果你想使用多重插补法,不妨也可以试试mice包,其操作原理是基于MC(蒙特卡洛模拟法)。
例子:
set.seed(1234)
y <- runif(1000,1,10)
x1 <- 2 - 1.32*y + rnorm(1000)
x2 <- 1.3 + 0.8 * y + rnorm(1000)
df <- data.frame(y = y, x1 = x1, x2 = x2)
#对y变量随机构造一些缺失值
df$y[sample(1000,26)] <- NA
summary(df$y)

#k临近替补法
imputation_k <- preProcess(df,method = 'knnImpute')
pred_k <- predict(imputation_k, df)
summary(pred_k$y)
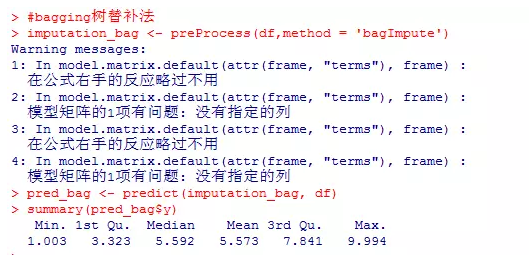
#bagging树替补法
imputation_bag <- preProcess(df,method = 'bagImpute')
pred_bag <- predict(imputation_bag, df)
summary(pred_bag$y)
#中位数替补法
imputation_m <- preProcess(df,method = 'medianImpute')
pred_m <- predict(imputation_m, df)
summary(pred_m$y)

六、变量转换
preProcess()函数也可以帮助我们实现变量的转换,例如降维操作,降维的目的是考虑到变量太多,通过降维能使主成分之间不相关或独立,而且还保留了数据绝大部分信息。我们常见的PCA和ICA就是用于降维,通过设置preProcess()函数的method参数就可方便的实现变量的降维操作。
当method='pca'时,就是指定主成分分析法实现数据的降维,原数据集的变量会改为P1,P2...,而且该方法也会强制原始数据进行标准化处理;当method='ica'时,就是指定独立成分分析法实现数据的降维,原数据集的变量会改为IC1,IC2,...。
例子:
#搜集数据,数据来源于吴喜之老师的PPT
x1 <- c(5700,1000,3400,3800,4000,8200,1200,9100,9900,9600,9600,9400)
x2 <- c(12.8,10.9,8.8,13.6,12.8,8.3,11.4,11.5,12.5,13.7,9.6,11.4)
x3 <- c(2500,600,1000,1700,1600,2600,400,3300,3400,3600,3300,4000)
x4 <- c(270,10,10,140,140,60,10,60,180,390,80,100)
x5 <- c(25000,10000,9000,25000,25000,12000,16000,14000,18000,25000,12000,13000)
my_data <- data.frame(x1 = x1, x2 = x2, x3 = x3, x4 = x4, x5 = x5)
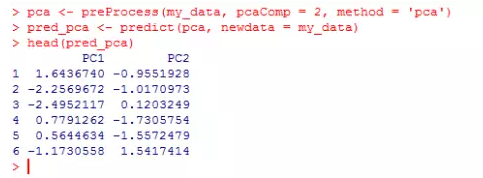
pca <- preProcess(my_data, pcaComp = 2, method = 'pca')
pred_pca <- predict(pca, newdata = my_data)
head(pred_pca)
介绍完有关数据预处理部分,我们再来看看数据分割的应用,而这部分又包含三方面的内容:
一、基于输出变量的分割
在使用某个挖掘算法对业务数据进行分析时,往往需要将样本数据分成训练集和测试集,分别用于模型的构建和模型稳定性、准确性的检验。如果你使用caret包中的createDataPartition()函数,就能便捷快速的实现数据的分割。
函数语法及参数介绍:
createDataPartition(y,
times = 1,
p = 0.5,
list = TRUE,
groups = min(5, length(y)))
y:指定数据集中的输出变量
times:指定创建的样本个数,默认简单随机抽取一组样本
p:指定数据集中用于训练集的比例
list:是否已列表或矩阵的形式存储随机抽取的索引号,默认为TRUE
groups:如果输出变量为数值型数据,则默认按分位数分组进行取样
以往我使用的数据分割方法
set.seed(1234)
idx <- sample(2,nrow(iris),replace = TRUE, prob = c(0.8,0.2))
train <- iris[idx == 1,]
test <- iris[idx == 2,]
nrow(train);prop.table(table(train$Species))

nrow(test);prop.table(table(test$Species))
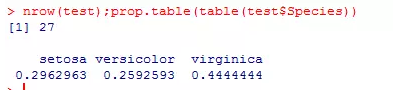
通过这种方法有几点不足:
1、训练集和测试集的样本量并没有完全按照80/20的比例划分
2、训练集和测试集的分类变量各水平数量比例不一致,即训练集和测试集的数据分布不一致
createDataPartition()函数的数据分割方法
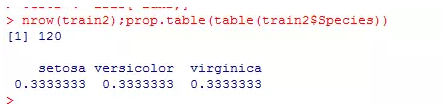
idx2 <- createDataPartition(iris$Species, p = 0.8, list = FALSE)
train2 <- iris[idx2,]
test2 <- iris[-idx2,]
nrow(train2);prop.table(table(train2$Species))
nrow(test2);prop.table(table(test2$Species))
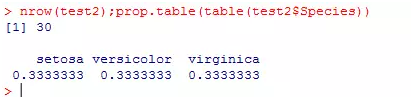
通过createDataPartition()函数实现的数据分割就能很好的解决上面提到的几点不足,因为在你设置p=0.8时,就隐含了两层含义,即从总体中抽取80%的样本,同时在各个因子水平下也取80%的样本。
二、使用有放回的方法进行抽样(BootStrap)
createResample(y, times = 10, list = TRUE)
y:指定数据集中的输出变量
times:指定抽样组数,默认为10组
list:是否已列表或矩阵的形式存储随机抽取的索引号,默认为TRUE
例子:
createResample(iris[,5], times = 2, list = TRUE)
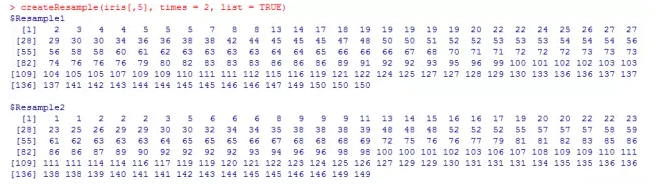
上图显示,生成2组有放回的样本。
三、用于交叉验证的样本抽样
createFolds(y, k = 10,
list = TRUE,
returnTrain = FALSE)
createMultiFolds(y, k = 10, times = 5)
y:指定数据集中的输出变量
k:指定k重交叉验证的样本,默认为10重。每重的样本量为总量/k。
list:是否已列表或矩阵的形式存储随机抽取的索引号,默认为TRUE
returnTrain:是否返回抽样的真实值,默认返回样本的索引值
times:指定抽样组数,默认为5组(每组中都有10重抽样)
例子:
createFolds(iris[,5], k = 2, list = TRUE, returnTrain = FALSE)

每重样本量为75。
createMultiFolds(iris[,5], k = 2, times = 2)

随机生成2组样本,每周又有2重样本,且样本量为75。
本篇内容就介绍到这,如果你对这块内容感兴趣的话,不妨下载这个强大的数据挖掘算法包,仔细研究并多动手敲敲键盘,我相信她一定能使你事半功倍!下一期将介绍使用caret包实现特征选取和构建训练模型。期待大家的关注!
每天进步一点点2015
学习与分享,取长补短,关注小号!

长按识别二维码 马上关注
