做Cognos时间越长,越觉得会的少,每天都要学习。从2015.12.01开始写 ###每天学点### 并发到微信群,也算是把自己的一点点经验分享出来。虽然经常也会没什么写,但是逐渐习惯之后也会觉得每天第一件事就是总结一下昨天学到了些什么。
我想把东西放在外面一份,这样方便搜索,如果想加入这个微信讨论群请联系随便一个小伙伴。或者加我微信!

### 01.20 ###
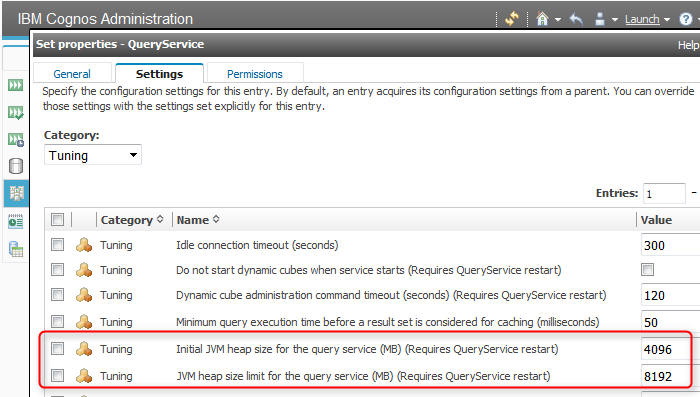
调优虽然有很多种方式和手段,但是针对Cognos来说,如果运行在DQM模式下,首先应该考虑调整Query Service内存使用。
在默认情况下Query Service的heapsize设置是很小的(1GB)。那么我们首先应该提高这个值。
在没有使用Dynamic Cubes的环境中--->初始值设置4G,最大值8G。然后继续测试性能,甚至继续增加
### 01.15 ###
CM不能启动报错:
'ContentManagerService', 'StartService', 'Failure'.
'ContentManager', 'getActiveContentManager', 'Failure'.
DPR-CMI-4006 Unable to determine the active Content Manager.
CM-CFG-5063 A Content Manager configuration error was detected while connecting to the content store.
临时恢复CM与CS:到cognos\configuration\schemas\content\你的db下找 dbClean_ .sql运行。可挽救系统(但是所有的报表就没了,相当于一个新的CS)。然后到Administration -- content configuration 那里重新import一下package,报表就回来了。但是job什么的就没了。所以只是算是一个临时的速效救心丸。
### 01.14 ###
碰见过一些job一直跑不完,要么pending,要么waiting。稍微总结了一些方法,希望对大家有用:
1. 在administration——Configuration——Content Administration中建立一个“consistency check”,在 "Internal references" 和 "external namespaces" 都进行检查并修复
2. 检查修复完毕,重启服务,重新登陆,手动cancel
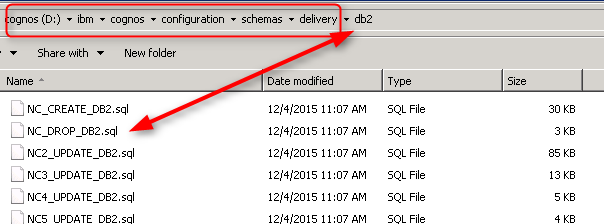
3. 如果还是不行的话进入cognos安装目录/configuration/schemas/delivery/自己的数据库/下面执行NC_DROP_db.sql
### 01.13 ###
Cognos中文排序的条件:
1. Cognos Connection里面的产品语言应该设置为中文
2. 在数据库客户端显示的中文字符排序应该也是拼音
3.如果Cognos里面设置的产品语言和数据库的排序语言不一致,按照拼音排序就会有问题。比如,Cognos的产品语言设置为英文,而数据库是中文。
### 01.11 ###
我最近正在看两本 《共享经济 重构未来商业新模式》,另一本是个英文版的《cognitive computing and big data analytics》挺不错的 比如说你们的天善平台就是利用了大家的盈余时间互相帮助 维护了社区热闹健康发展
### 01.07 ###
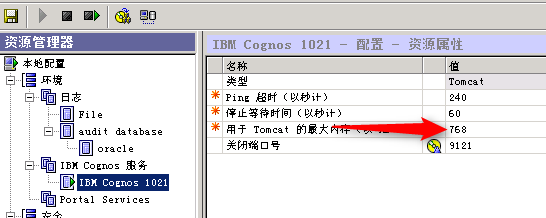
碰见一个案例,报错out of memory,客户觉得他们内存够大就把如图所示的地方调大到8GB。
这是一种错误的调优方式,分享一下里面的知识:因为在图中的内存是指tomcat的最大占用内存,也就是APP Server的使用内存。这个数值没必要设置太大(其实很少见超过4GB的设置),基本上大家放到2GB已经够用。因为这是一个跑dispatcher的容器,并不实际参与报表的运算,所以大了没用。
那么内存不足来自哪里?
- 如果是CQM方式的报表要看BIBusTKServerMain使用量,单个进程最大值是2GB(c++)。如果运算在2GB不能完成,那么报错OOO
- 如果是DQM方式要看cognos administration-configuration中queryservice的jvm heap size大小。将这个值设置更大达到避免OOO
### 01.06 ###
碰见一个案例,报错out of memory,客户觉得他们内存够大就把如图所示的地方调大到8GB。
这是一种错误的调优方式,分享一下里面的知识:因为在图中的内存是指tomcat的最大占用内存,也就是APP Server的使用内存。这个数值没必要设置太大(其实很少见超过4GB的设置),基本上大家放到2GB已经够用。因为这是一个跑dispatcher的容器,并不实际参与报表的运算,所以大了没用。
那么内存不足来自哪里?
- 如果是CQM方式的报表要看BIBusTKServerMain使用量,单个进程最大值是2GB(c++)。如果运算在2GB不能完成,那么报错OOO
- 如果是DQM方式要看cognos administration-configuration中queryservice的jvm heap size大小。将这个值设置更大达到避免OOO
### 01.05 ###
关于cognos analytics(cognos 11)的搜索功能的一点说明:新的搜索功能是一个针对全局的搜索,并且不需要配置(与之前版本的大改善)。搜索的索引不仅是针对某一个属性。而是针对:报表名称、描述、spec中的引用。说明文档在这里:http://www-01.ibm.com/support/docview.wss?uid=swg21973197
### 01.04 ###
今天分享华青莲的一篇文章 http://www.flybi.net/blog/hql15/2707
这里说的query service是指Cognos在10.1.1之后引入的一个新的引擎。之前的引擎使用BIBusTKServerMain处理查询请求,但由于这个组件是c++时代的产物,仅仅支持32位(最大寻址默认2GB),那么性能上就有个瓶颈。所以query service的引入就是把DQM(动态查询模式)带入,使用这种模式BIBusTKServerMain的查询功能将使用java进程处理,支持64位,并且这个java进程是处理全局请求,所以才使得缓存可以重复利用。
### 12.31 ###
数据库有一个colation sequence的概念,用来做排序用的。那么cognos如何了解?
- 在cognos/configuration/xqe文件夹下有一个配置文件 oracle.properties或者teradata.properties。中定义了这个顺序。例如:在这个文件中能找到SELECT '', CASE WHEN 'A' = 'a' and 'é' = 'e' THEN 'CI_AI' WHEN 'A' ='a' and 'é' <> 'e' THEN 'CI_AS' WHEN 'A' <> 'a' and 'é' <> 'e' THEN 'CS_AS' ELSE 'CS_AI' END as COLLATOR_STRENGTH
### 12.30 ###
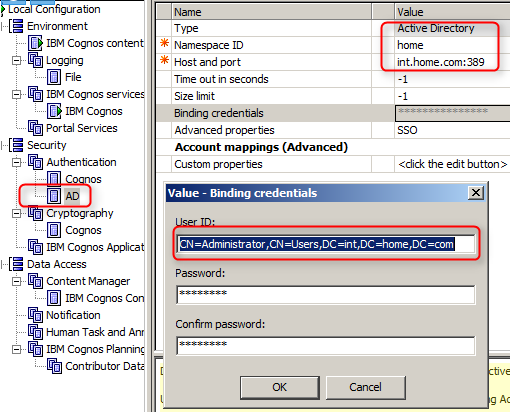
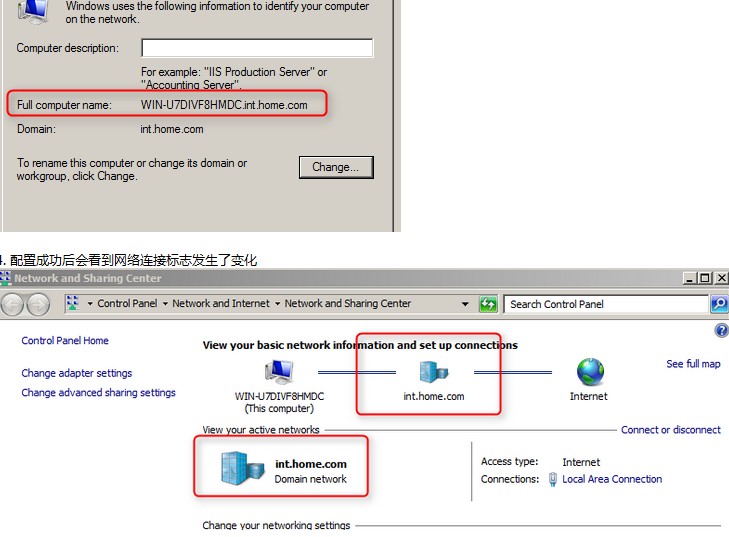
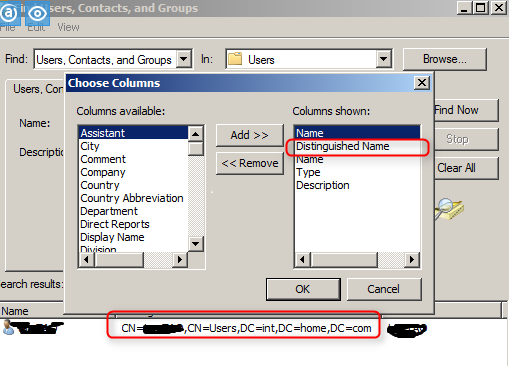
配置AD截图
### 12.29 ###
需求是想通过一个选择(类似于prompt page),然后反复选择并叫用户看到其针对的结果。类似于:选择A项在查看页面中看A的内容,然后再去选择B项,页面变成B的内容。
实现方式:
1. 直接在本report上加prompt(最简单)
2. 直接使用Workspace并且创建全局filter去控制多个tab(美观)
3. 使用drill through,并且带上参数
### 12.28 ###
不知道大家有没有注意过NULL值的排序问题(只针对relational的数据类型)。同样的数据,用List展现(根据有NULL的列排序),NULL值有可能在最后,而crosstab终NULL值可能在最前。
这是由于list生成native SQL,而crosstab会生成MDX。那么问题就出在MDX的引擎设置上——>在cognos/configuration/xqe中有配置文件dmr.properties中间有一条:null.position.order.function=LAST,那么就在这里做了设定。如果项目需要将NULL放在最开始或者最终,都可以通过这里进行配置
### 12.24 ###
Cognos Analytics 发布。云端访问地址:https://cognosnext.bi.ibmcloud.com/bi/index.html。全部中文文档:http://www-01.ibm.com/support/docview.wss?uid=swg27047187#cbiv11r0m0zh-cn
### 12.21 ###
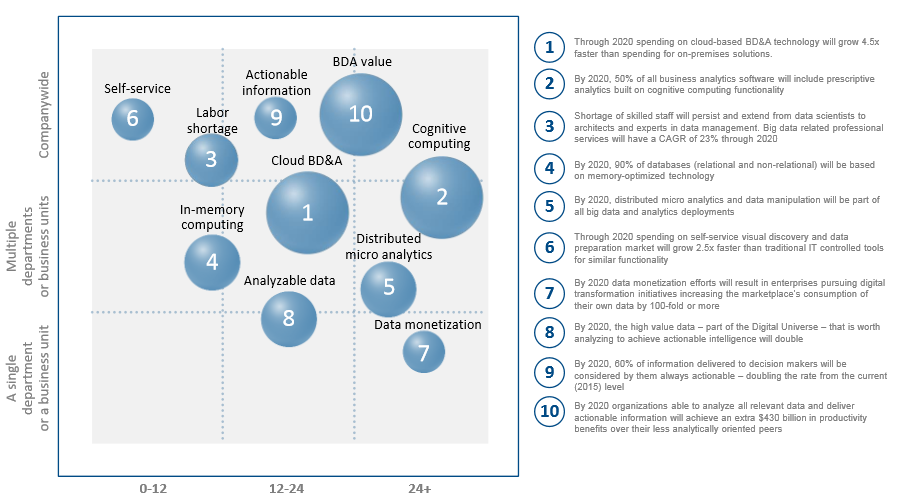
今早看了个IDC对大数据及分析技术市场做得报告,跟大家分享一下。
图中根据重要性排名第一的是云上的大数据分析将比现今的onpremise安装要有4.5倍的增长。
第二是将有一半的预测性分析会使用到认知计算。
三是大数据分析人才缺口依旧存在
### 12.15 ###
见过有些朋友使用 congos/bin64/shutdown.sh命令去关闭cognos服务,由于缺少文档也不知道这个shutdown.sh跟cogconfig.sh -stop的区别。
请记住cognos官方文档上只说明了一种关闭cognos服务的方式,就是./cogconfig.sh -stop,而shutdown.sh会停止dispatcher,而可能不会停止所有其他的服务,然而导致下次重启后也许会看到BIBusTKServerMain孤儿进程
### 12.14 ###
在Cognos10.2.2版本中,将UAT中的动态立方体(dynamic cube)部署到PROD中可以用一个新的REST接口,同时新增了一些API例子代码,放在cognos\sdk\fmdsdk\java目录下
除此之外,只能老老实实的用Cube Designer进行重新部署了
### 12.12 ###
监控日志文件,在启动cognos之后 (cogconfig.sh -s)会产生一个 wlp_cogbootstrap_service.pid,这里面的PID是全部cognos服务的父进程,如果在cognos服务运行时清理掉这个文件就会造成例如BIBusTKServerMain找不到父进程从而不能正常停止。再次启动时有可能碰见错误。这里需要注意一下。因为见过有些朋友喜欢在运行时把logs文件夹全部删掉。
正确的清理日志/缓存文件的方式是先停cognos,再删。
我的测试版本是10.2.2
### 12.11 ###
多页的报表在导出为Excel 2002格式是自动给sheet名字加后缀,如 页面1 -1, 页面1 -2,如何去掉后缀“-1”,"-2"
解决问题具体步骤如下:
1. 登录IBM Cognos Connection,进入管理界面
2. 选择“配置”页面
3. 选择 “调度程序和服务”
4. 选中调度程序服务器 如: 配置>http://servername:port/p2pd,
5. 选择 BatcheReportService, 设置属性,点击“设置”
6. 点击“编辑...” 在“高级属性”项上。
7. 选中 “改写从父条目获取的设置”框。
8. 添加参数和值:RSVP.EXCEL.NUMBEREDSHEETNAMES=FALSE
9.“确定 ” 保存。
10. 回到步骤 4“调度程序服务器”,选择ReportService,设置属性, 重复步骤6~9.
11. 如果在分布式环境中,有多台“调度程序服务器”,需要对每台都进行设置。
### 12.08 ###
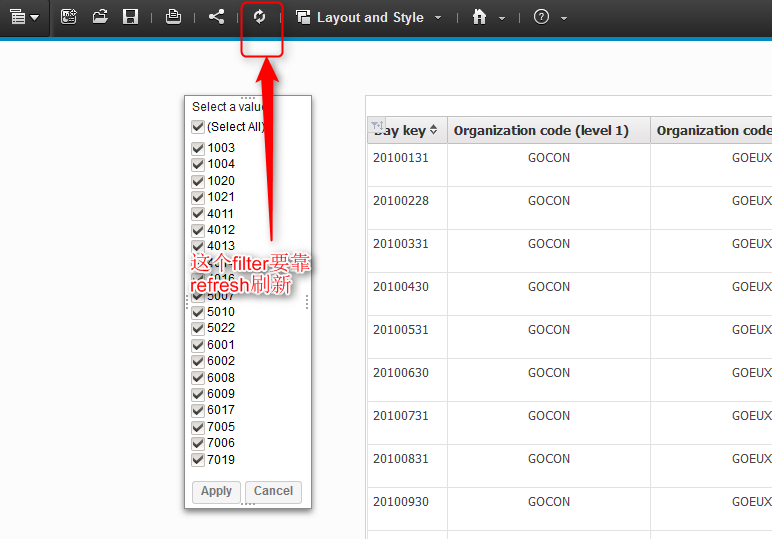
放在workspace里的filter其实是一个缓存形式,所以当数据发生变化的时候并不会有改变。为了能够反映数据的变化,需要做一次刷新
### 12.07 ###
使用Cube Designer监控运行在Teradata DBC数据库中的Application Query性能
(SQL实行时间,CPU使用率,表大小等信息)
第一:在Cognos 10.2.2种有一个组件叫PMA(Performance Monitoring Analysis),这个组件会安装已有的报表做专门的观察性能的使用。
第二:可以通过在Teradata中建立"system objects"视图(views),然后再使用Cube Designer导入。
### 12.04 ###
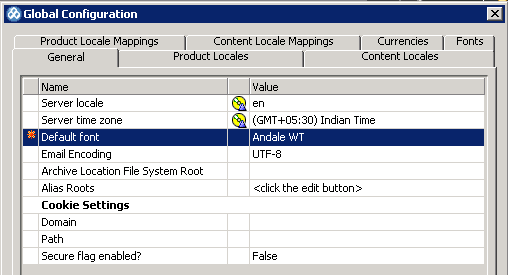
有时候看到图表上的中文显示为方块,首先确定一下操作系统上有这个字库,特别是linux上,将Andale WT拷贝入jre/lib/fonts,然后重新测试。Andale WT是一个cognos会首先引入的字库
### 12.03 ###
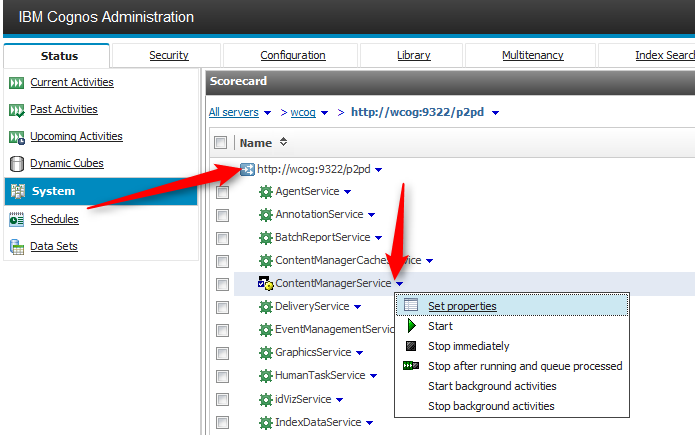
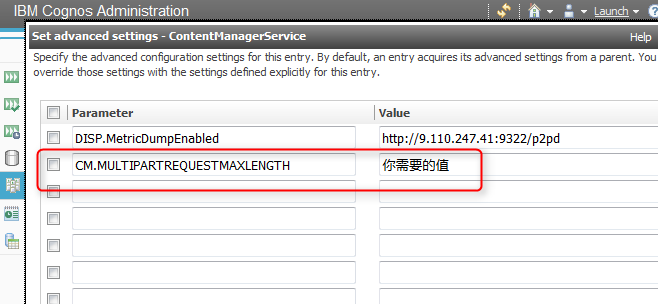
报错:CM-REQ-4268 The multipart request is invalid. The posted content length of 2063613900 exceeds the limit of 500000000.
设置:CM.MULTIPARTREQUESTMAXLENGTH

### 12.02 ###
./cogconfig.sh 或者 cogconfig.bat后面可以加一些参数,例如常见的 -s静默启动 -stop停止 -log写入一个日志 -java:local用自身jre -java:env用系统java_home -notest不测试直接启动
### 12.01 ###
举个例子,在这个支持环境中http://www-969.ibm.com/software/reports/compatibility/clarity-reports/repo
rt/html/prereqsForProduct?deliverableId=1283262749193#sw-6,这个版本cognos"只支持Netezza7.0以及其后的fix pack"。那么意思是支持Netezza7.0.1/Netezza7.0.2等等,而不支持Netezza7.1.0

