1.第三方库
python拥有很强大的第三方库,在使用中我们可以快速调用这些库的程序,使得程序灵活高效。
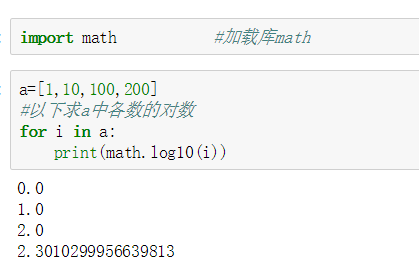
加载第三方库用关键字import,要命名别名用关键字as,比如我们要输入库math的语法为:import math。
2.numpy
数据分析常用的第三方库是numpy和pandas。
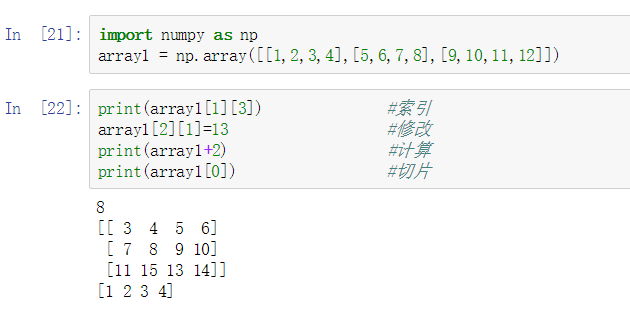
numpy的对象是同种元素的多维数组,即ndarray。这是一个所有的元素都是一种类型、通过一个正整数元组索引的元素表格(通常是元素是数字)。其最基础操作为array,创建数组,和列表类似,也可以进行索引、修改、计算、切片等操作。
3.pandas之Series
pandas是基于numpy构建的,为时间序列分析提供了很好的支持。pandas中有两个主要的数据结构,一个是Series,另一个是DataFrame。
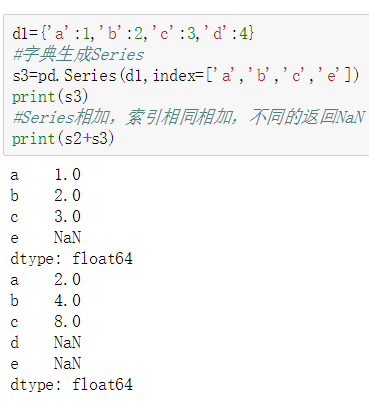
数据结构Series是一维的,由一组数据和其对应的数据标签(索引index)组成。索引默认为空,即是数字0,1,2,3……但也可以指定,表现形式为:索引在左,数据在右。另外的,使用字典也可以生成Series,字典的键是索引,如果额外指定索引,不匹配的的索引的数据值为NaN。

4.pandas之DataFrame
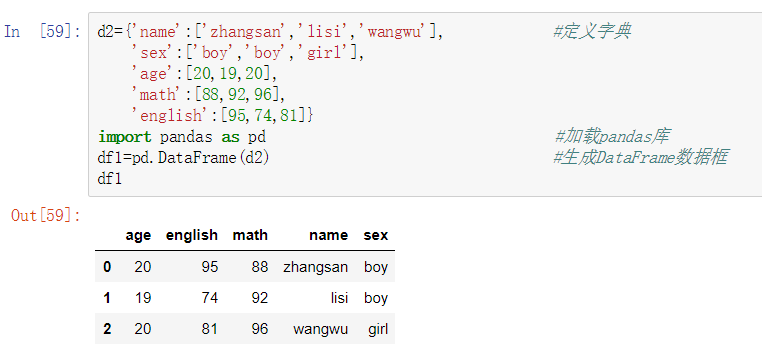
数据结构DataFrame是二维的,和Series相比多了columns(可以看做成是excel中的列)。同样的也可以用字典来生成DataFrame,字典的键就是DataFrame的列索引,值就是相对应列的具体数据,行索引则和Series一样。
同样的,DataFrame的行列索引都可以自定义,不能匹配的用NaN代替。
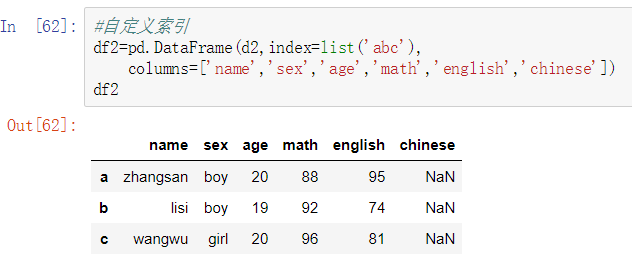
DataFrame基于列切片可以用中括号或者点,多列切片中括号里用列表。

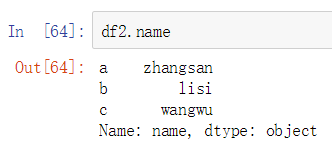
对行切片则用ix、loc、iloc,ix是可以混合使用行号和索引取值,iloc是根据行号取值,loc是根据索引取值,这三个同时也可以选取列标签取值。
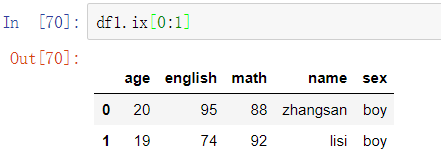
Pandas的数据查找是通过逻辑判断法,也就是布尔索引来查找所需要的数据,只返回ture的数据。如果多个条件的话,需要用逻辑符号且(&)、或(|)、非(~),每个条件两端需要用小括号括起来。
修改数据要先根据索引查找到所要改的数据,然后在进行赋值,使用loc。

5.pandas之加载数据
Pandas加载数据用read的相关函数,如read_csv、read_excel等。注意:读取路径不能有中文字符,默认编码为utf8要使用其他编码的话则需使用参数encoding来确定编码类型。查询数据的前5行或末尾5行分别用head和tail,也可以指定行数查询。
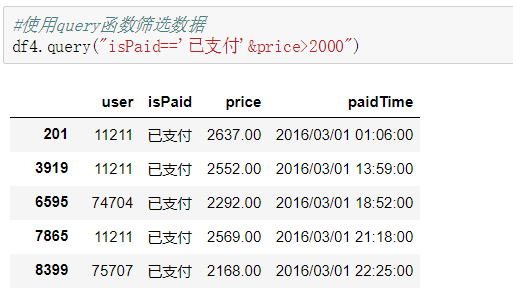
筛选数据除了之前的索引方法之外,还可以用函数query。
6.pandas之常用函数
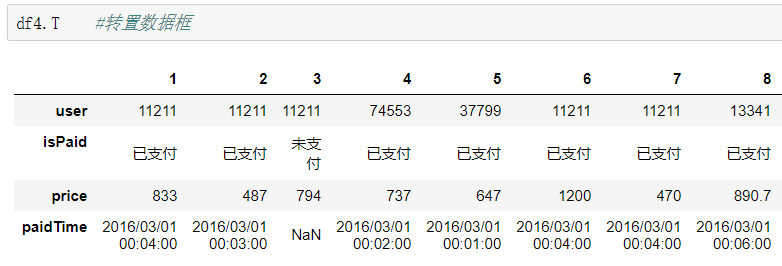
转置:用函数T,即是把数据框的行列位置对调
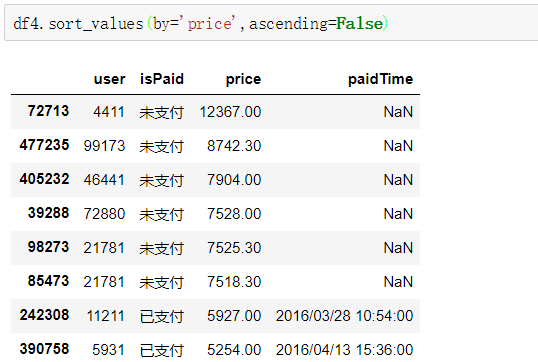
排序:sort_values,按列排序可以是多列。默认升序(ascending)
sort_index,按行索引排序。默认升序
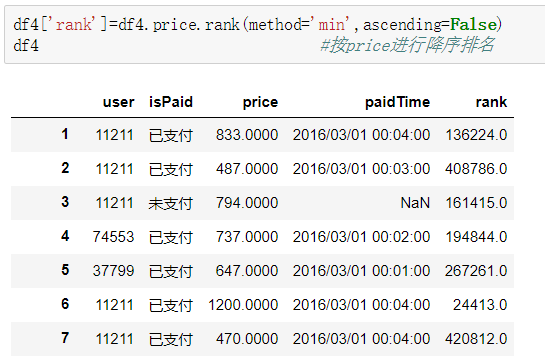
排名:rank,默认method='average',升序排名(ascending=True),按行(axis=0)
#average 值相等时,取排名的平均值
#min 值相等时,取排名最小值
#max 值相等时,取排名最大值
#first值相等时,按原始数据出现顺序排名
重复值:unique(),返回唯一值的数组

描述统计:describe(),只能对数字列进行描述统计。描述统计里的每个指标都可以单独计算,如max,min等。

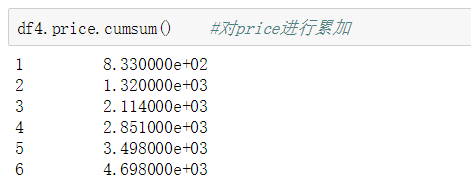
累加:cumsum,按列进行逐行累加。一般用于计算总次数或者总销售等。
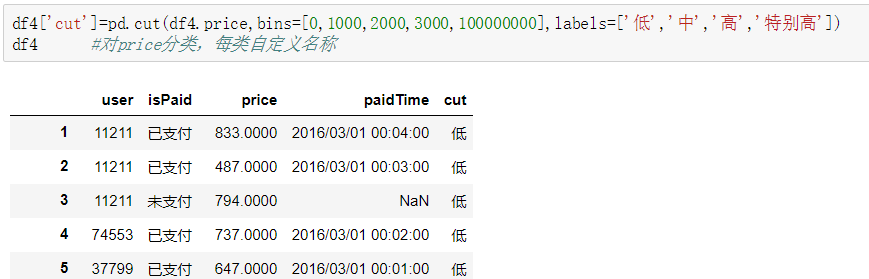
分类统计:cut,参数x是需要分类的列,bins表示需要分的组数也可以自定义分割,labels表示每组的标签即是名称,注意cut是在pandas下的函数而不是DataFrame。另外的还有个qcat函数是对排名进行分类的。
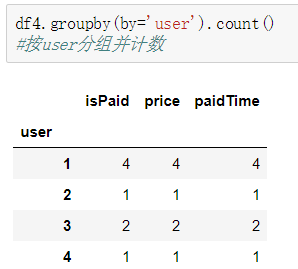
数据分组:groupby,按某列或多列进行分组,分组之后可以进行计数、求最值等操作。
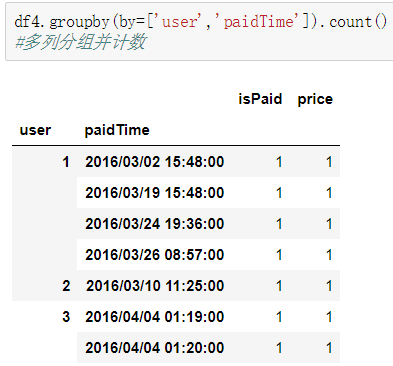
7.多表关联
merge:根据一列或多列把两表的行合并。

join:默认是行索引关联,也可以是左表索引关联右表字段。
concat:默认将两个表上下堆叠在一起,
8.数据预处理
(1)文本清洗:要利用字符串函数str,例如要去除字符串的两端字符也就是提取中间字符,直接利用字符串的索引。每次使用操作之前都要调用一次str函数。

(2)空值处理:可以分为删除(dropna)和填充(fillna)。
fillna(value=None,method=None,axis=0)中的value除了基本类型外,还可以使用字典,这样可以实现对不同列填充不同的值。
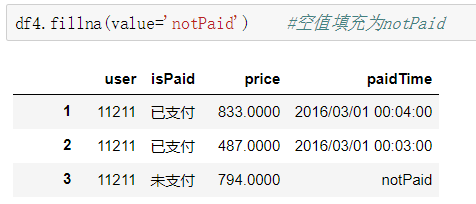
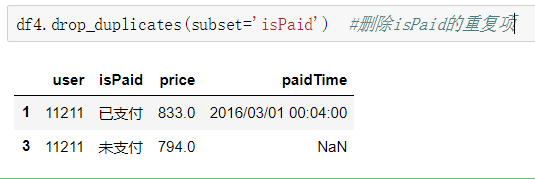
(3)重复值处理:查找重复值(duplicated)和删除重复值(drop_duplicates)。
duplicated:数据表中两个条目间所有列的内容都相等时,函数才会判断为重复值,也可以单独对某一列进行重复值判断。
drop_duplicates:判断标准与duplicated一样,只是把后出现的重复值删除即是默认保留‘first’。
(4)更改数据格式:通常是用函数astype更改即可。这里要注意的是日期格式要用to_datetime函数来更改。
9.函数apply
函数格式为:apply(func,*args,**kwargs),当一个函数的参数存在于一个元组或者一个字典中时,用来间接的调用这个函数,并将元组或者字典中的参数按照顺序传递给参数
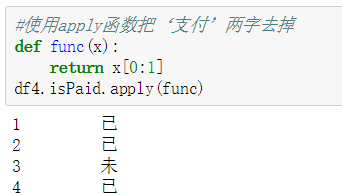
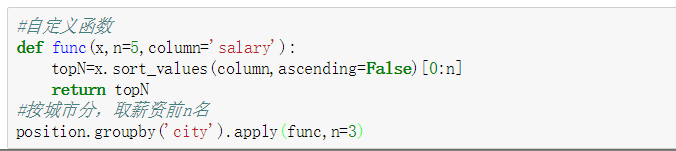
apply 是 pandas 库的一个很重要的函数,多和 groupby 函数一起用,也可以直接用于 DataFrame和 Series 对象。主要用于数据聚合运算,可以很方便的对分组进行现有的运算和自定义的运算。例如要对position表求每个城市前三的薪资情况:
10.数据透视
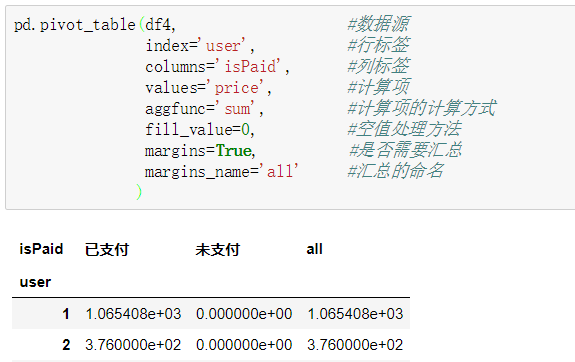
在pandas使用函数pivot_table函数进行数据透视,功能和excel类似,根据一个或多个制定的维度对数据进行聚合。
pandas.pivot_table函数中包含四个主要的变量,以及一些可选择使用的参数。四个主要的变量分别是数据源data,数值values,行索引index,列columns。可选择使用的参数包括数值的汇总方式,NaN值的处理方式,以及是否显示汇总行数据等。
11.操作数据库
(1)用python连接数据库
首先应该要先按装pymysql这个包,使用命令行命令pip install pymysql来安装。然后使用这个包下面的函数connet创建连接,再用函数cursor创建游标,最后再用函数execute执行sql语句即成功连接。

连接成功后,要把结果执行出来,则需要使用游标中的函数ftechall。
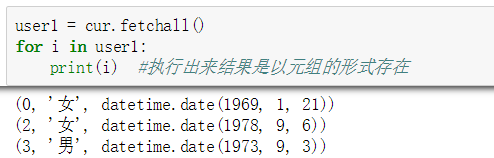
如果对数据有新建或者修改的操作,则需要使用函数commit来提交数据。

若所有操作已经完成,在最后则需要关闭游标和连接。

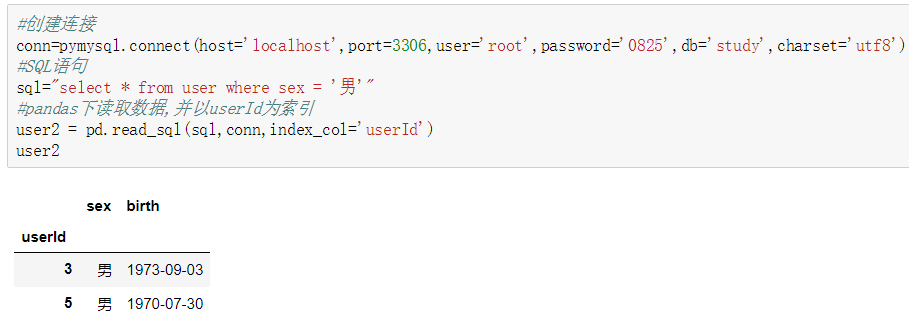
(2)在pandas下连接数据库
建议使用此方法,同样的需要创建连接和SQL语句,然后直接用函数read_sql读取数据库即可。注意这里的连接语句也可以用下面11.3图中的连接方法。
(3)把数据写入到数据库
在写入数据库之前一般要在数据库中创建一个我们所需要的新表,然后再用函数to_sql写入即可。这里需要注意的是,连接需要使用另外的一种方法:库sqlalchemy下的函数create_engine。


