这章对于我这个应用数学专业的人来说会相对容易一些,不过毕业也有好几年了,差不多都给忘了,刚好可以好好复习一下。
一、分类数据描述
分类数据是描述事物类别的,这些类别的个数是有限个并且没有顺序先后之分,一般用来计数而不能进行数值计算。例如性别分为男、女;商品类别可以分为家电、食品、衣服等类别。在统计这类数据时用count()函数即可。
二、数值数据描述
1.平均数
平均数是指在一组数据中所有数据之和再除以这组数据的个数,可以反映数据集中趋势。在excel中用函数average()。
2.中位数
中位数是指一组数据最中间的值,它可以将数据划分为个数相等的上下两部分。
求中位数时需要把数据按顺序排列,如果一组数据的个数为n:
当n是奇数时,中位数就是第(n+1)/2个数。
当n是偶数时,中位数就是第n/2和n/2+1个数的平均数。
在excel中用函数median()。
3.众数
众数是指这组数出现次数最多的数,当次数最多的时候数有多个时这几个都是众数。另外的,如果所有数据出现次数一样多则没有众数。
在excel中用函数mode()。
4.分位数
常用的分位数是四分位数和十分位数,这里主要介绍四分位数。
四分位数是指把所有数值由小到大排列并分成四等份,处于三个分割点位置的数值。
第一分位数 (Q1),又称“较小四分位数”,等于所有数值由小到大排列后第25%的数字。
第二分位数 (Q2),又称“中位数”,等于所有数值由小到大排列后第50%的数字。
第三分位数 (Q3),又称“较大四分位数”,等于所有数值由小到大排列后第75%的数字。
在excel中用函数quartile(),一般用来做箱线图。
5.方差与标准差
方差是每个数与全部数据平均数之差的平方值的平均数,标准差是方差的平方根。这两个都是反应数据的离散程度,一般情况下用标准差表示即可。
方差在excel中用函数VAR.P(),标准差在excel中用函数STDEV.P()。
用公式表示如下:其中σ²表示方差,σ表示标准差,μ表示平均值,n表示数据总个数,Xi表示某个数据。
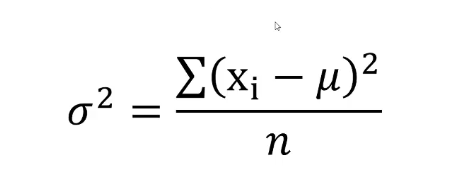
三、数据标准化——Z-score法(正规化方法)
在数据分析过程中常常遇到多组数据对比分析,然而这些数据的量纲和数量级会不同,无法直接进行分析,所以就有必要对数据进行标准化处理。这里介绍了一种常用的标准化方法:Z-score法,也叫正规化方法。公式为:新数据=(原数据-均值)÷标准差。若用σ表示标准差,μ表示平均值,可以写成:
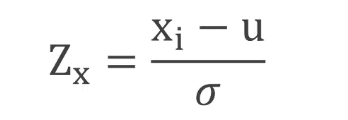
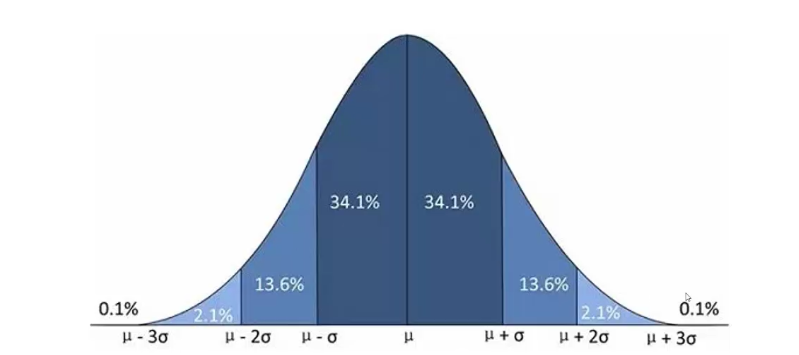
四、切比雪夫定理
任意一个数据集中,位于其平均数m个标准差范围内的部分至少为1-1/m²,其中m为大于1的任意正数。
对于m=2,m=3和m=5有如下结果:
所有数据中,至少有3/4(或75%)的数据位于平均数2个标准差范围内。
所有数据中,至少有8/9(或89%)的数据位于平均数3个标准差范围内。
所有数据中,至少有24/25(或96%)的数据位于平均数5个标准差范围内。
五、统计图形
1.箱线图
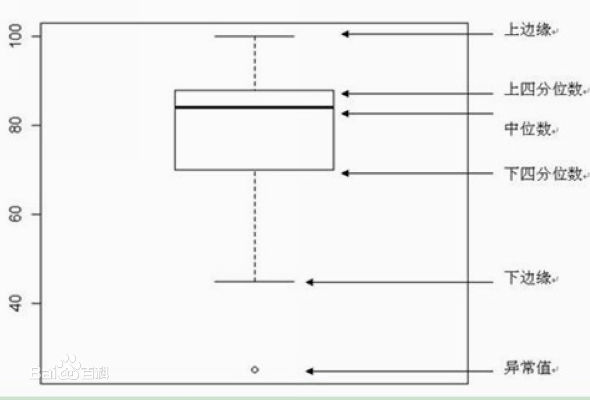
箱线图是用来显示一组数据分散情况的统计图,是根据四分位数作出此图。箱线图包含一个矩形箱体和上下两条竖线,箱体表示数据集中范围,竖线表示数据延伸范围。箱体上边界是上四分位数,一般用Q3表示;下边界是下四分位数,一般用Q1表示;箱体内部横线是中位数,一般用Q2表示。箱体上下之间的高度距离叫做四分位间距框,在数值上等于Q3-Q1,一般用IQR表示。上边缘=Q3+1.5IQR,下边缘=Q1-1.5IQR,实际情况中在上下边缘内取最靠近边缘的值画横线来作为实际的上下边缘。而在上下边缘横线之外的数据则是异常值。
2.直方图
直方图与条形图类似,不过直方图的分类数据(横轴)是数值数据,并且数据分类无间隔不重复,是数值数据分布的精确图形表示。
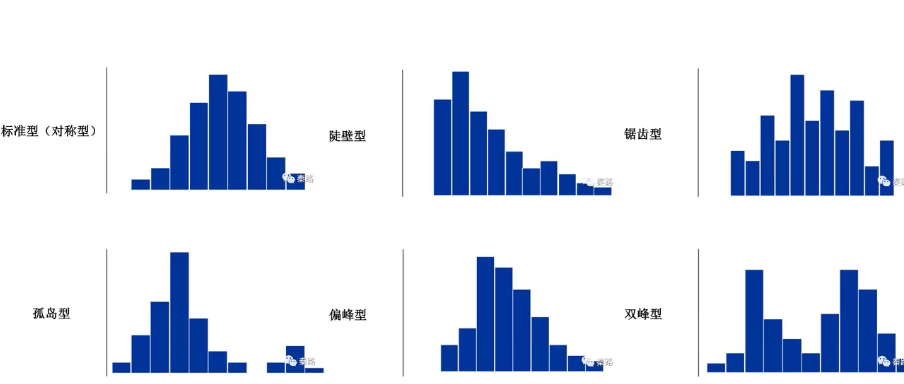
直方图按形状大致可以分为六类:
标准型:是中间高、两边低,左右近似对称,符合正态分布
陡壁型:像高山的陡壁向一边倾斜时
锯齿型:凹凸不平的形状,此类型一般表示为分组过多或者数据不全
孤岛型:直方图旁边有孤立的小岛出现,此时应该着重分析出现孤岛的原因
偏峰型:顶峰向一侧偏移
双峰型:出现两个顶峰,一般是数据来源于两个样本
正态分布:一般标准型的直方图都可以看成符合正态分布。
切比雪夫定理2.0

六、概率
1.概率是指随机事件发生的可能性,大小是在0到1之间。
事件A发生的概率表示为P(A)
对任意两个事件A、B满足公式:P(A∪B)=P(A)+P(B)-P(A∩B)
当事件A是在事件B发生的前提下的概率公式为P(A|B)=P(A∩B)/P(B)
2.贝叶斯定理
贝叶斯定理写成如下图公式,其中P(A|B)是在B发生的情况下A发生的可能性。  为完备事件组,即之间无交集,并集即为全集。
为完备事件组,即之间无交集,并集即为全集。
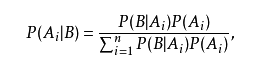
特殊的,只有两个可能事件的公式可以写成:

