介绍一些可以用来爬取微信公众号的轮子
1、基于搜狗微信搜索的微信公众号爬虫接口
地址:Chyroc/WechatSogou
安装
pip install wechatsogou
引用
from wechatsogou import *
wechats = WechatSogouApi()
搜索公众号 - search_gzh_info
from wechatsogou import *
wechats = WechatSogouApi()
name = 'Python'
wechat = wechats.search_gzh_info(name)
print(wechat)

搜索微信文章
from wechatsogou import *
wechats = WechatSogouApi()
keywords = 'Python'
wechat = wechats.search_article_info(keywords)
print(wechat)

获取最近文章
from wechatsogou import *
wechats = WechatSogouApi()
wechatid = 'python_shequ'
data = wechats.get_gzh_message(wechatid=wechatid)
print(data)

更多用法
# -*- coding: utf-8 -*-
# 导入包
from wechatsogou.tools import *
from wechatsogou import *
import logging
import logging.config
# 日志
logging.config.fileConfig('logging.conf')
logger = logging.getLogger()
# 实例
wechats = WechatSogouApi()
exit()
# 搜索一个微信公众号
name = '南京航空航天大学'
wechat_infos = wechats.search_gzh_info(name)
# 对于数据库中的某一个微信号进行搜索
wechat_id = 'nanhangqinggong'
wechat_info = wechats.get_gzh_info(wechat_id)
# 或许可以对用户开放搜索文章的功能~
keywords = '傅里叶变换'
wechat_articles = wechats.search_article_info(keywords)
# 在上面,我们得到过微信号的最近文章页的地址,现在,就去获取该页的数据
data = wechats.get_gzh_message(wechatid='nanhangqinggong')
data_all = wechats.get_gzh_message_and_info(wechatid='nanhangqinggong')
# 对于上面获取的文章链接,需要处理,注意此方法获取的`yuan`字段是文章固定地址,应该存储这个
messages = wechats.get_gzh_message(wechatid='nanhangqinggong')
for m in messages:
if m['type'] == '49':
article_info = wechats.deal_article(m['content_url'])
# 或 article_info = wechats.deal_article(m['content_url'], m['title'])
# 直接获取热门文章
articles_single = wechats.get_recent_article_url_by_index_single()
articles_all = wechats.get_recent_article_url_by_index_all()
# 微信搜索联想词
sugg_keyword = wechats.get_sugg('中国梦')
2、微信公众号爬虫
具体用法参考bowenpay/wechat-spider
3、基于搜狗微信入口的微信爬虫程序
由基于phantomjs的python实现。 使用了收费的动态代理。 采集包括文章文本、阅读数、点赞数、评论以及评论赞数。 效率:500公众号/小时。 根据采集的公众号划分为多线程,可以实现并行采集。
地址:CoolWell/wechat_spider
4、依赖Scrapy和搜狗搜索微信公众号文章
地址:LKI/wescraper
使用Python2.7和scrapy来搜索微信公众号文章。
5、用于批量爬取微信公众号所有文章
地址:songluyi/crawl_wechat
6、基于搜狗微信的公众号文章爬虫
地址:jaryee/wechat_sogou_crawl

好了,这样的爬虫还有很多,自己花时间也可以写出来,这里有代理IP拿去用吧国内高匿免费HTTP代理IP
但是我也发现了一个不用写代码的神器,造数造数 - 新一代智能云爬虫,用造数来爬虫实在是太简单了,而且不需要写代码
可以在下面编辑爬取多页,还可以二次爬取
在速度上,自己写代码确实需要一些时间,使用工具1~2分钟就可以完成目标,另外还有一个数据可视化的工具BDP个人版-免费在线数据分析软件,数据可视化软件
爬取一页信息几秒就够了,而且是免费的
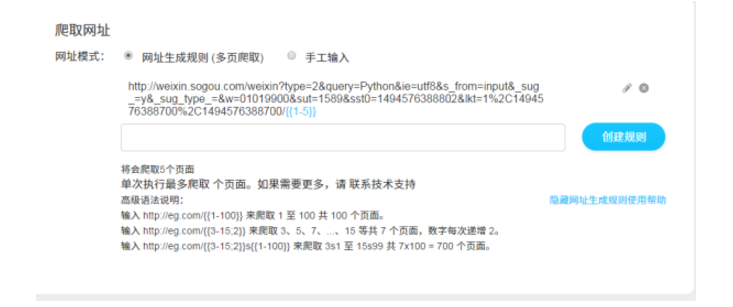
下面是用造数爬取的微信中关于“Python”的数据,超级简单啊!
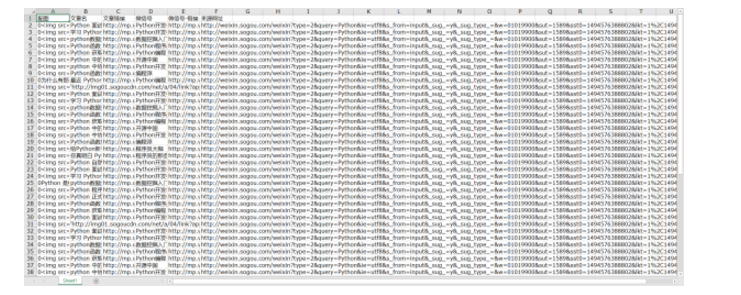
总结
造数是一个可以用来简单爬虫的工具,速度快,也免费。但是也有缺点,想要获取首页知乎的内容,发现是未登录状态,这个时候就是Python出场了,模拟登陆什么的不要太简单
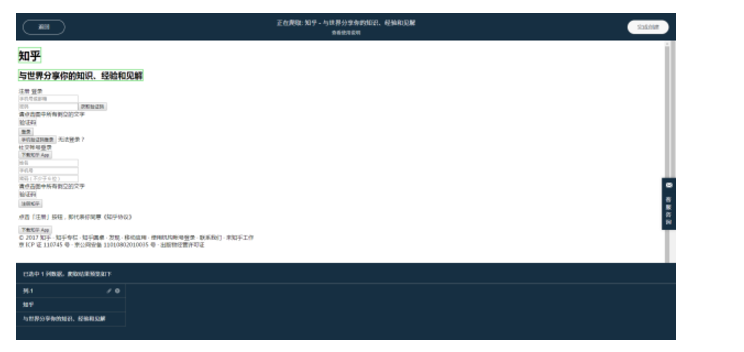
还有一点,Python是自己来写的,有成就感。

当然了,如果不会写爬虫或赶时间,造数挺好的,没用过八爪鱼,不知道怎样。。
欢迎加入爬虫爱好者群,每周一个爬虫案例。(私戳我哦)
