

对数据集进行分组并对各组应用一个函数(聚合或者转换),是数据分析工作重要环节。数据集准备好之后,就是计算分组统计或生成透视表。
pandas提供了一个灵活高效的groupby功能,可以对数据集进行切片、切块、摘要等操作。
本章内容:
- 根据一个或多个键(可以是函数,数组或DataFrame列名)拆分pandas对象。
- 计算分组统计摘要,如计数、平均值、标准差、或用户自定义函数。
- 对DataFrame的列应用各种各样的函数
- 应用组内转换或其他运算,如规格化、线性回归、排名、选取子集等
- 计算透视表或交叉表
- 执行分位数分析以及其他分组分析
分组运算的术语(split-apply-combine)拆分-应用-合并。
第一阶段,我们提供的键会把pandas对象(无论是Series,DataFrame)中的数据拆分为多组。拆分操作是在对象的特定轴上执行。
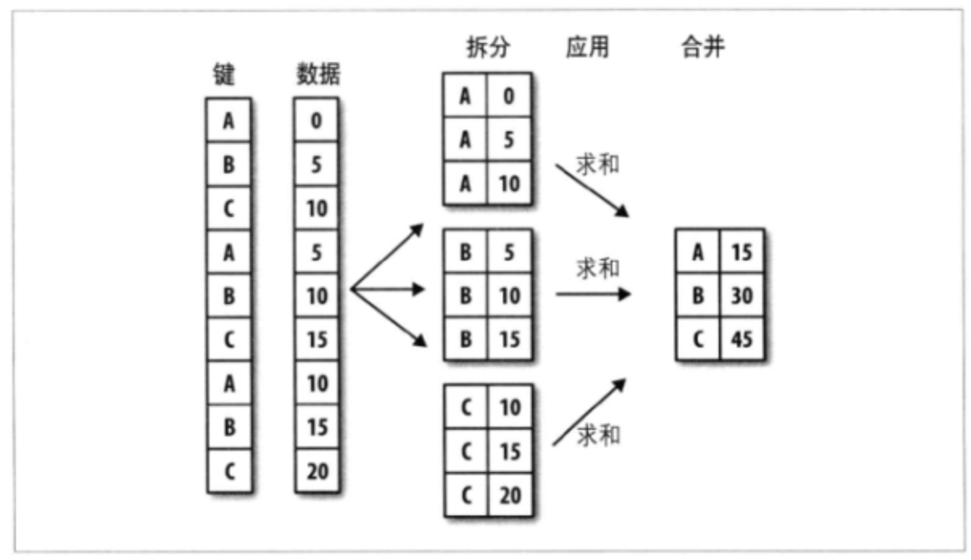
- 列表或数组,其长度与待分组的轴一样;
- 表示DataFrame某个列名的值;
- 字典或Series给出待分组轴上的值与分组之间的对应关系;
- 函数,用于处理索引或索引中的各个标签;
#访问data1,根据key1调用groupby
In [3]: import numpy as np
...: import pandas as pd
...: import matplotlib.pyplot as plt
...: from pandas import Series,DataFrame
...:
In [4]: df =DataFrame({'key1':list('aabba'),'key2':['one','two','one','two','one'],
...: 'data1':np.random.randn(5),'data2':np.random.randn(5)})
In [5]: df
Out[5]:
data1 data2 key1 key2
0 -0.713865 -0.508708 a one
1 -0.001112 -0.431989 a two
2 -1.845435 1.631306 b one
3 1.158896 -1.145442 b two
4 -0.555897 -2.520632 a one
#访问data1,并根据key1调用groupby
In [6]: grouped=df['data1'].groupby(df['key1'])
In [7]: grouped
Out[7]: <pandas.core.groupby.SeriesGroupBy object at 0x000000000A1ADA90>
#调用GroupBy的mean方法来计算分组平均值
In [8]: grouped.mean()
Out[8]:
key1
a 0.03546
b -1.77451
Name: data1, dtype: float64
In [10]: means=df['data1'].groupby([df['key1'],df['key2']]).mean()
In [11]: means
Out[11]:
key1 key2
a one 0.771713
two -1.201122
b one -0.495424
two 0.955653
Name: data1, dtype: float64
In [12]: means.unstack()
Out[12]:
key2 one two
key1
a 0.771713 -1.201122
b -0.495424 0.955653
In [14]: states=np.array(['Ohio','California','California','Ohio','Ohio'])
In [15]: yaers=np.array([2005,2005,2006,2005,2006])
In [16]: years=np.array([2005,2005,2006,2005,2006])
In [18]: df['data1'].groupby([states,years]).mean()
Out[18]:
California 2005 -1.201122
2006 -0.495424
Ohio 2005 0.606807
2006 1.285464
Name: data1, dtype: float64
#将列名用作分组键
In [21]: df.groupby('key1').mean()
Out[21]:
data1 data2
key1
a 0.114101 -0.572603
b 0.230114 -0.583885
In [22]: df.groupby(['key1','key2']).mean()
Out[22]:
data1 data2
key1 key2
a one 0.771713 -0.444467
two -1.201122 -0.828875
b one -0.495424 1.384597
two 0.955653 -2.552366
#返回一个含有分组大小的Series
In [23]: df.groupby(['key1','key2']).size()
Out[23]:
key1 key2
a one 2
two 1
b one 1
two 1
dtype: int64
9.1.2 对分组进行迭代
#产生一组二元元组
In [9]: for name,group in df.groupby('key1'):
...: print name
...: print group
...:
a
data1 data2 key1 key2
0 -0.713865 -0.508708 a one
1 -0.001112 -0.431989 a two
4 -0.555897 -2.520632 a one
b
data1 data2 key1 key2
2 -1.845435 1.631306 b one
3 1.158896 -1.145442 b two
#元组的第一个元素将会由键值组成的元组
In [10]: for (k1,k2), group in df.groupby(['key1','key2']):
...: print k1,k2
...: print group
...:
a one
data1 data2 key1 key2
0 -0.713865 -0.508708 a one
4 -0.555897 -2.520632 a one
a two
data1 data2 key1 key2
1 -0.001112 -0.431989 a two
b one
data1 data2 key1 key2
2 -1.845435 1.631306 b one
b two
data1 data2 key1 key2
3 1.158896 -1.145442 b two
#将这些数据片段做成一个字典
In [12]: pieces=dict(list(df.groupby('key1')))
In [13]: pieces['b']
Out[13]:
data1 data2 key1 key2
2 -1.845435 1.631306 b one
3 1.158896 -1.145442 b two
groupby默认是在axis=0上进行分组,通设置也可以在其他任何轴上进行分组
In [14]: df.dtypes
Out[14]:
data1 float64
data2 float64
key1 object
key2 object
dtype: object
In [15]: groupbyed=df.groupby(df.dtypes,axis=1)
In [17]: grouped=df.groupby(df.dtypes,axis=1)
In [18]: dict(list(grouped))
Out[18]:
{dtype('float64'): data1 data2
0 -0.713865 -0.508708
1 -0.001112 -0.431989
2 -1.845435 1.631306
3 1.158896 -1.145442
4 -0.555897 -2.520632, dtype('O'): key1 key2
0 a one
1 a two
2 b one
3 b two
4 a one}
9.1.3 选取一个或一组列
对于由DataFrame产生的GroupBy对象,如果用一个(单个字符串)或一组(字符串数组)列名对其进行索引,就能实现选取部分列进行聚合。
df.groupby('key1')['data1']
df.groupby('key1')['data2']
是以下代码的语法糖:
df['data1'].groupby(df['key1'])
df['data2'].groupby(df['key1'])
尤其对于大数据集,可能只需要对部分列进行聚合。
对于前面的出现的那个数据集,如果只需要计算data2列的平均值并以DataFrame的形式得到结果,我们可以写出:
In [2]: df =DataFrame({'key1':list('aabba'),'key2':['one','two','one','two','one'],'data1':np.random.randn(5),'data2':np.random.randn(5)})
In [4]: df
Out[4]:
data1 data2 key1 key2
0 -0.119115 -1.660365 a one
1 -1.677104 1.664901 a two
2 -0.124288 0.991688 b one
3 -0.357859 -0.645814 b two
4 -0.627007 -0.340816 a one
In [5]: df.groupby(['key1','key2'])[['data2']].mean()
Out[5]:
data2
key1 key2
a one -1.000590
two 1.664901
b one 0.991688
two -0.645814
这种索引操作所返回的对象是一个已分组的DataFrame(如果传入的是列表或数组)或已分组的Series(如果传入的是标量形式的单个列名):
In [6]: s_grouped=df.groupby(['key1','key2'])['data2']
In [7]: s_grouped
Out[7]: <pandas.core.groupby.SeriesGroupBy object at 0x000000000B6345F8>
In [8]: s_grouped.mean()
Out[8]:
key1 key2
a one -1.000590
two 1.664901
b one 0.991688
two -0.645814
Name: data2, dtype: float64
9.1.4 通过字典或Series进行分组
除数组外,分组信息还可以以其他形式存在。
In [9]: people =DataFrame(np.random.randn(5,5),columns=['a','b','c','d','e'],index=['Joe','Steve','Wes','Jim','Travis'])
In [10]: people
Out[10]:
a b c d e
Joe 0.153422 -1.740001 -1.814139 0.358241 -0.130256
Steve -0.870311 1.199198 0.275245 0.160661 0.144324
Wes -0.298472 0.472300 1.070169 0.899584 2.011791
Jim -0.638032 -0.011376 0.685198 0.625192 1.335396
Travis -2.482942 1.661548 1.284279 -1.061266 -0.632708
#添加几个NA值
In [11]: people.ix[2:3,['b','c']]=np.nan
In [12]: people
Out[12]:
a b c d e
Joe 0.153422 -1.740001 -1.814139 0.358241 -0.130256
Steve -0.870311 1.199198 0.275245 0.160661 0.144324
Wes -0.298472 NaN NaN 0.899584 2.011791
Jim -0.638032 -0.011376 0.685198 0.625192 1.335396
Travis -2.482942 1.661548 1.284279 -1.061266 -0.632708
假设已知列的关系,并希望根据分组计算列的总和。
In [13]: mappings={'a':'red','b':'red','c':'blue','d':'blue','e':'red','f':'orange'}
In [15]: by_column=people.groupby(mappings,axis=1)
In [16]: by_column
Out[16]: <pandas.core.groupby.DataFrameGroupBy object at 0x000000000B634D68>
In [17]: by_column.sum()
Out[17]:
blue red
Joe -1.455897 -1.716835
Steve 0.435906 0.473211
Wes 0.899584 1.713320
Jim 1.310389 0.685988
Travis 0.223013 -1.454102
Series也有着同样的功能,可以被看做是一个大的映射。
In [19]: map_series=Series(mappings)
In [20]: map_series
Out[20]:
a red
b red
c blue
d blue
e red
f orange
dtype: object
In [22]: people.groupby(map_series,axis=1).count()
Out[22]:
blue red
Joe 2 3
Steve 2 3
Wes 1 2
Jim 2 3
Travis 2 3
9.1.5 通过函数进行分组
相较于字典或Series,python函数在定义分组映射问题上更有创意更为抽象。
任何被当做分组键的函数都会在各个索引值上被调用一次,其返回值就会被用作分组名称。
下面的例子是假设我们想根据人名的长度进行分组,虽然可以求取一个字符串的长度数组,但是其实仅仅传入len函数就可以了:
In [28]: people.groupby(len).sum()
Out[28]:
a b c d e
3 -0.783082 -1.751376 -1.128941 1.883017 3.216931
5 -0.870311 1.199198 0.275245 0.160661 0.144324
6 -2.482942 1.661548 1.284279 -1.061266 -0.632708
In [31]: key_list=['one','one','one','two','two']
In [32]: people.groupby([len,key_list]).min()
Out[32]:
a b c d e
3 one -0.298472 -1.740001 -1.814139 0.358241 -0.130256
two -0.638032 -0.011376 0.685198 0.625192 1.335396
5 one -0.870311 1.199198 0.275245 0.160661 0.144324
6 two -2.482942 1.661548 1.284279 -1.061266 -0.632708
9.1.6 根据索引级别分组
层次化索引数据集最方便的地方就是在于能够根据索引级别禁止聚合。
如果实现该目的,通过level关键字传入级别编号或名称即可:
In [33]: columns=pd.MultiIndex.from_arrays([['US','US','US','JP','JP'],[1,3,5,1,3]],names=['city','tenor'])
In [34]: hier_df=DataFrame(np.random.randn(4,5),columns=columns)
In [35]: columns
Out[35]:
MultiIndex(levels=[[u'JP', u'US'], [1, 3, 5]],
labels=[[1, 1, 1, 0, 0], [0, 1, 2, 0, 1]],
names=[u'city', u'tenor'])
In [36]: hier_df=DataFrame(np.random.randn(4,5),columns=columns)
In [37]: hier_df
Out[37]:
city US JP
tenor 1 3 5 1 3
0 1.416009 -0.016826 1.498950 1.010254 1.757742
1 -0.528243 -1.113364 0.120569 0.209329 0.260765
2 0.540845 2.198479 -1.307002 -0.545171 -0.378676
3 -0.625421 -0.960389 -1.435062 1.851948 0.210522
In [38]: hier_df.groupby(level='city',axis=1).count()
Out[38]:
city JP US
0 2 3
1 2 3
2 2 3
3 2 3
9.2 数据聚合
数据聚合指的是任何能够从发数组产生标量的值得数据转换过程。
In [1]: import numpy as np
...: import pandas as pd
...: import matplotlib.pyplot as plt
...: from pandas import Series,DataFrame
...:
In [2]: df =DataFrame({'key1':list('aabba'),'key2':['one','two','one','two','one'],
...: ...: 'data1':np.random.randn(5),'data2':np.random.randn(5)})
In [3]: df
Out[3]:
data1 data2 key1 key2
0 -1.828647 0.329238 a one
1 -0.639952 1.532362 a two
2 0.617105 0.906281 b one
3 1.443470 1.419738 b two
4 -2.031339 -0.649743 a one
In [4]: grouped = df.groupby('key1')
#quantile用于计算Series或DataFrame列的样本分位数
In [5]: grouped['data1'].quantile(0.9)
Out[5]:
key1
a -0.877691
b 1.360834
Name: data1, dtype: float64
#定义了一个函数,传入agg方法
In [6]: def peak_to_peak(arr):
...: return arr.max() -arr.min()
In [8]: grouped.agg(peak_to_peak)
Out[8]:
data1 data2
key1
a 1.391387 2.182105
b 0.826366 0.513457
In [9]: grouped.describe()
Out[9]:
data1 data2
key1
a count 3.000000 3.000000
mean -1.499979 0.403952
std 0.751669 1.092969
min -2.031339 -0.649743
25% -1.929993 -0.160253
50% -1.828647 0.329238
75% -1.234300 0.930800
max -0.639952 1.532362
b count 2.000000 2.000000
mean 1.030287 1.163010
std 0.584329 0.363069
min 0.617105 0.906281
25% 0.823696 1.034645
50% 1.030287 1.163010
75% 1.236879 1.291374
max 1.443470 1.419738
In [10]: tips = pd.read_csv(r"E:\python\pydata-book-master\ch08\tips.csv")
In [11]: tips[:4]
Out[11]:
total_bill tip sex smoker day time size
0 16.99 1.01 Female No Sun Dinner 2
1 10.34 1.66 Male No Sun Dinner 3
2 21.01 3.50 Male No Sun Dinner 3
3 23.68 3.31 Male No Sun Dinner 2
#添加“小费占总额的百分比”的列
In [12]: tips['tip_pct'] = tips['tip']/tips['total_bill']
In [13]: tips[:4]
Out[13]:
total_bill tip sex smoker day time size tip_pct
0 16.99 1.01 Female No Sun Dinner 2 0.059447
1 10.34 1.66 Male No Sun Dinner 3 0.160542
2 21.01 3.50 Male No Sun Dinner 3 0.166587
3 23.68 3.31 Male No Sun Dinner 2 0.139780
9.2.1面向列的多函数应用
对Series和DataFrame列的聚合运算就是使用aggregate(使用自定义函数)或者调研如mean,std之类的方法。
我们将继续上述数据集的例子,对不同的列使用不同的聚合函数。
In [14]: grouped = tips.groupby(['sex','smoker'])
In [19]: grouped_pct = grouped['tip_pct']
In [20]: grouped_pct.agg('mean')
Out[20]:
sex smoker
Female No 0.156921
Yes 0.182150
Male No 0.160669
Yes 0.152771
Name: tip_pct, dtype: float64
#如果传入一组函数名,数据集的列就会以相应的函数命名
In [24]: grouped_pct.agg(['mean','std',peak_to_peak])
Out[24]:
mean std peak_to_peak
sex smoker
Female No 0.156921 0.036421 0.195876
Yes 0.182150 0.071595 0.360233
Male No 0.160669 0.041849 0.220186
Yes 0.152771 0.090588 0.674707
#如果传入的是一个由(name,function)元组组成的列表,则各元组的第一个元素就会被用作数据#集的列名
In [27]: grouped_pct.agg([('foo','mean'),('bar',np.std)])
Out[27]:
foo bar
sex smoker
Female No 0.156921 0.036421
Yes 0.182150 0.071595
Male No 0.160669 0.041849
Yes 0.152771 0.090588
#对tip_pct 和 total_bill 列计算三个统计信息
In [27]: grouped_pct.agg([('foo','mean'),('bar',np.std)])
Out[27]:
foo bar
sex smoker
Female No 0.156921 0.036421
Yes 0.182150 0.071595
Male No 0.160669 0.041849
Yes 0.152771 0.090588
In [28]: function = ['count','mean','max']
In [29]: result = grouped['tip_pct','total_bill'].agg(function)
In [30]: result
Out[30]:
tip_pct total_bill
count mean max count mean max
sex smoker
Female No 54 0.156921 0.252672 54 18.105185 35.83
Yes 33 0.182150 0.416667 33 17.977879 44.30
Male No 97 0.160669 0.291990 97 19.791237 48.33
Yes 60 0.152771 0.710345 60 22.284500
In [31]: result['tip_pct']
Out[31]:
count mean max
sex smoker
Female No 54 0.156921 0.252672
Yes 33 0.182150 0.416667
Male No 97 0.160669 0.291990
Yes 60 0.152771 0.710345
9.2.2 以“无索引”的方式返回聚合数据
#传入as_index = False禁用聚合数据有唯一的分组键组成的索引
In [32]: tips.groupby(['sex','smoker'],as_index=False).mean()
Out[32]:
sex smoker total_bill tip size tip_pct
0 Female No 18.105185 2.773519 2.592593 0.156921
1 Female Yes 17.977879 2.931515 2.242424 0.182150
2 Male No 19.791237 3.113402 2.711340 0.160669
3 Male Yes 22.284500 3.051167 2.500000 0.152771
9.3 分组级运算和转换
聚合是分组运算的一个特例。它接受能够将一维数组简化的为标量值的函数。
下列是为数据集添加一个用于存放各索引分组平均值的列,先聚合再合并
In [33]: df
Out[33]:
data1 data2 key1 key2
0 -1.828647 0.329238 a one
1 -0.639952 1.532362 a two
2 0.617105 0.906281 b one
3 1.443470 1.419738 b two
4 -2.031339 -0.649743 a one
In [34]: k1_means = df.groupby('key1').mean().add_prefix('mean_')
In [35]: k1_means
Out[35]:
mean_data1 mean_data2
key1
a -1.499979 0.403952
b 1.030287 1.163010
In [36]: pd.merge(df,k1_means,left_on = 'key1',right_index = True)
Out[36]:
data1 data2 key1 key2 mean_data1 mean_data2
0 -1.828647 0.329238 a one -1.499979 0.403952
1 -0.639952 1.532362 a two -1.499979 0.403952
4 -2.031339 -0.649743 a one -1.499979 0.403952
2 0.617105 0.906281 b one 1.030287 1.163010
3 1.443470 1.419738 b two 1.030287 1.163010
我们使用一下其他方法:
In [37]: key = ['one','two','one','two','one']
In [41]: people =DataFrame(np.random.randn(5,5),columns=['a','b','c','d','e'],index=['Joe','Steve','Wes','Jim','Travis'])
In [42]: people
Out[42]:
a b c d e
Joe -1.264617 -1.385894 0.146627 -1.225148 0.627616
Steve 0.880528 0.530060 0.453235 1.160768 -0.053416
Wes 1.033023 -0.859791 -0.629231 -1.094454 -2.073512
Jim 1.777919 -0.864824 -1.940994 -0.806969 0.504503
Travis -1.260144 -0.486910 1.180371 -0.214743 0.629261
In [43]: people.groupby(key).mean()
Out[43]:
a b c d e
one -0.497246 -0.910865 0.232589 -0.844782 -0.272212
two 1.329224 -0.167382 -0.743879 0.176899 0.225544
In [44]: people.groupby(key).transform(np.mean)
Out[44]:
a b c d e
Joe -0.497246 -0.910865 0.232589 -0.844782 -0.272212
Steve 1.329224 -0.167382 -0.743879 0.176899 0.225544
Wes -0.497246 -0.910865 0.232589 -0.844782 -0.272212
Jim 1.329224 -0.167382 -0.743879 0.176899 0.225544
Travis -0.497246 -0.910865 0.232589 -0.844782 -0.272212
In [45]: def demean(arr):
...: return arr-arr.mean()
In [46]: demeaned = people.groupby(key).transform(demean)
In [47]: demeaned
Out[47]:
a b c d e
Joe -0.767371 -0.475029 -0.085962 -0.380366 0.899828
Steve -0.448695 0.697442 1.197114 0.983868 -0.278960
Wes 1.530269 0.051074 -0.861820 -0.249672 -1.801300
Jim 0.448695 -0.697442 -1.197114 -0.983868 0.278960
Travis -0.762898 0.423955 0.947782 0.630038 0.901473
#检查一下demeaned现在的分组的平均值是否为0
In [48]: demeaned.groupby(key).mean()
Out[48]:
a b c d e
one 0.0 5.551115e-17 0.0 -1.480297e-16 0.0
two 0.0 0.000000e+00 0.0 0.000000e+00 0.0
9.3.1 apply:一般性的“拆分-应用-合并”
transform是一个严格的条件的特殊函数:传入的函数只能产生两种结果,要么产生一个可以广播的标量值,要么产生一个相同大小的结果数组。
apply会将待处理的对象拆分为多个片段,然后对各片段调用传入的函数,最后尝试将各个片段组合在一起。
假设我们想从小费那个数据集里面选出5个最高的tip_pct值。
#先排序,然后取其中最前面的5个
In [52]: def top(df,n=5,column = 'tip_pct'):
...: return df.sort_index(by=column)[-n:]
In [53]: top(tips,n=6)
__main__:2: FutureWarning: by argument to sort_index is deprecated, pls use .sort_values(by=...)
Out[53]:
total_bill tip sex smoker day time size tip_pct
109 14.31 4.00 Female Yes Sat Dinner 2 0.279525
183 23.17 6.50 Male Yes Sun Dinner 4 0.280535
232 11.61 3.39 Male No Sat Dinner 2 0.291990
67 3.07 1.00 Female Yes Sat Dinner 1 0.325733
178 9.60 4.00 Female Yes Sun Dinner 2 0.416667
172 7.25 5.15 Male Yes Sun Dinner 2 0.710345
In [54]: tips.groupby('smoker').apply(top)
__main__:2: FutureWarning: by argument to sort_index is deprecated, pls use .sort_values(by=...)
Out[54]:
total_bill tip sex smoker day time size tip_pct
smoker
No 88 24.71 5.85 Male No Thur Lunch 2 0.236746
185 20.69 5.00 Male No Sun Dinner 5 0.241663
51 10.29 2.60 Female No Sun Dinner 2 0.252672
149 7.51 2.00 Male No Thur Lunch 2 0.266312
232 11.61 3.39 Male No Sat Dinner 2 0.291990
Yes 109 14.31 4.00 Female Yes Sat Dinner 2 0.279525
183 23.17 6.50 Male Yes Sun Dinner 4 0.280535
67 3.07 1.00 Female Yes Sat Dinner 1 0.325733
178 9.60 4.00 Female Yes Sun Dinner 2 0.416667
172 7.25 5.15 Male Yes Sun Dinner 2 0.710345
#加一点特殊条件
In [55]: tips.groupby(['smoker','day']).apply(top,n=1,column = 'total_bill')
__main__:2: FutureWarning: by argument to sort_index is deprecated, pls use .sort_values(by=...)
Out[55]:
total_bill tip sex smoker day time size \
smoker day
No Fri 94 22.75 3.25 Female No Fri Dinner 2
Sat 212 48.33 9.00 Male No Sat Dinner 4
Sun 156 48.17 5.00 Male No Sun Dinner 6
Thur 142 41.19 5.00 Male No Thur Lunch 5
Yes Fri 95 40.17 4.73 Male Yes Fri Dinner 4
Sat 170 50.81 10.00 Male Yes Sat Dinner 3
Sun 182 45.35 3.50 Male Yes Sun Dinner 3
Thur 197 43.11 5.00 Female Yes Thur Lunch 4
tip_pct
smoker day
No Fri 94 0.142857
Sat 212 0.186220
Sun 156 0.103799
Thur 142 0.121389
Yes Fri 95 0.117750
Sat 170 0.196812
Sun 182 0.077178
Thur 197 0.115982
In [56]: result = tips.groupby('smoker')['tip_pct'].describe()
In [57]: result
Out[57]:
smoker
No count 151.000000
mean 0.159328
std 0.039910
min 0.056797
25% 0.136906
50% 0.155625
75% 0.185014
max 0.291990
Yes count 93.000000
mean 0.163196
std 0.085119
min 0.035638
25% 0.106771
50% 0.153846
75% 0.195059
max 0.710345
Name: tip_pct, dtype: float64
In [58]: result.unstack('smoker')
Out[58]:
smoker No Yes
count 151.000000 93.000000
mean 0.159328 0.163196
std 0.039910 0.085119
min 0.056797 0.035638
25% 0.136906 0.106771
50% 0.155625 0.153846
75% 0.185014 0.195059
max 0.291990 0.710345
其实上述的describe方法,就相当于下面的代码:
f =lambda x: x.describe()
grouped.apply(f)
9.3.2 示例:用特定于分组的值来填充缺失值
有时候我们希望使用数据本身衍生出的值去填充NA值。
n [63]: from pandas import DataFrame,Series
In [64]: s = Series(np.random.randn(6))
#将其中几个值填充为NAN
In [65]: s[::2]=np.nan
In [66]: s
Out[66]:
0 NaN
1 -1.884394
2 NaN
3 0.379894
4 NaN
5 0.588869
dtype: float64
#使用fillna把S的平均值填充进去
In [67]: s.fillna(s.mean())
Out[67]:
0 -0.305210
1 -1.884394
2 -0.305210
3 0.379894
4 -0.305210
5 0.588869
dtype: float64
#根据不同的分组来填充不同的值
In [6]: states = ['Ohio','New York','Vermont','Florida','Oregon','Nevada','California','Idaho']
In [7]: group_key
Out[7]: ['East', 'East', 'East', 'East', 'West', 'West', 'West', 'West']
In [8]: data = Series(np.random.randn(8),index=states)
In [9]: data
Out[9]:
Ohio -1.537801
New York 0.263208
Vermont 0.500445
Florida -0.255887
Oregon 0.867263
Nevada -0.620590
California 0.593747
Idaho 2.501651
dtype: float64
In [11]: data.groupby(group_key).mean()
Out[11]:
East -0.257509
West 0.835518
dtype: float64
#用分组平均值去填充NA值
In [12]: fill_mean = lambda g:g.fillna(g.mean())
In [13]: data.groupby(group_key).apply(fill_mean)
Out[13]:
Ohio -1.537801
New York 0.263208
Vermont 0.500445
Florida -0.255887
Oregon 0.867263
Nevada -0.620590
California 0.593747
Idaho 2.501651
dtype: float64
In [14]: fill_values = {'East':0.5,'West':-1}
In [15]: fill_func = lambda g:g.fillna(fill_values[g.name])
In [16]: fill_func
Out[16]: <function __main__.<lambda>>
In [19]: data.groupby(group_key).apply(fill_func)
Out[19]:
Ohio -1.537801
New York 0.263208
Vermont 0.500445
Florida -0.255887
Oregon 0.867263
Nevada -0.620590
California 0.593747
Idaho 2.501651
dtype: float64
9.3.3 示例:分组加权平均数和相关系数
根据groupby的“拆分-应用-合并”范式,DataFrame的列雨列之间的或两个Series之间的运算成为一种标准作业。
In [29]: df = DataFrame({'category':['a','a','a','a','b','b','b','b'],'data':np.random.randn(8),'weights':np.random.rand(8)})
In [30]: df
Out[30]:
category data weights
0 a 0.352124 0.131472
1 a -1.340416 0.605210
2 a -0.486105 0.835266
3 a 0.172995 0.013656
4 b 0.897209 0.879197
5 b 0.955620 0.414658
6 b -0.779258 0.850658
7 b -0.193639 0.738796
In [31]: grouped = df.groupby('category')
In [34]: get_wavg = lambda g: np.average(g['data'],weights = g['weights'])
In [35]: grouped.apply(get_wavg)
Out[35]:
category
a -0.737008
b 0.131494
dtype: float64
#读取一个雅虎的数据集
In [55]: close_px = pd.read_csv(r'E:\python\pydata-book-master\ch09\stock_px.csv',parse_dates = True,index_col = 0)
In [56]: close_px[-4:]
Out[56]:
AAPL MSFT XOM SPX
2011-10-11 400.29 27.00 76.27 1195.54
2011-10-12 402.19 26.96 77.16 1207.25
2011-10-13 408.43 27.18 76.37 1203.66
2011-10-14 422.00 27.27 78.11 1224.58
In [57]: close_px[:4]
Out[57]:
AAPL MSFT XOM SPX
2003-01-02 7.40 21.11 29.22 909.03
2003-01-03 7.45 21.14 29.24 908.59
2003-01-06 7.45 21.52 29.96 929.01
2003-01-07 7.43 21.93 28.95 922.93
#计算一个由日收益率与SPX之间的年度相关系数组成的DataFrame
In [58]: rets = close_px.pct_change().dropna()
In [59]: spx_corr = lambda x: x.corrwith(x['SPX'])
In [60]: by_year = rets.groupby(lambda x: x.year)
In [61]: by_year.apply(spx_corr)
Out[61]:
AAPL MSFT XOM SPX
2003 0.541124 0.745174 0.661265 1.0
2004 0.374283 0.588531 0.557742 1.0
2005 0.467540 0.562374 0.631010 1.0
2006 0.428267 0.406126 0.518514 1.0
2007 0.508118 0.658770 0.786264 1.0
2008 0.681434 0.804626 0.828303 1.0
2009 0.707103 0.654902 0.797921 1.0
2010 0.710105 0.730118 0.839057 1.0
2011 0.691931 0.800996 0.859975 1.0
In [65]: by_year.apply(lambda g:g['AAPL'].corr(g['MSFT']))
Out[65]:
2003 0.480868
2004 0.259024
2005 0.300093
2006 0.161735
2007 0.417738
2008 0.611901
2009 0.432738
2010 0.571946
2011 0.581987
dtype: float64
9.3.4 示例:面向分组的线性回归
定义一个regress函数,对各数据块执行一个普通的最小二乘法(OLS)回归。
In [66]: import statsmodels.api as sm
In [67]: def regress(data,yvar,xvar):
...: Y = data[yvar]
...: X = data[xvar]
...: X['intercept'] = 1
...: result = sm.OLS(Y,X).fit()
...: return result.params
...:
#计算AAPL对SPX收益率的线性回归
In [68]: by_year.apply(regress,'AAPL',['SPX'])
Out[68]:
SPX intercept
2003 1.195406 0.000710
2004 1.363463 0.004201
2005 1.766415 0.003246
2006 1.645496 0.000080
2007 1.198761 0.003438
2008 0.968016 -0.001110
2009 0.879103 0.002954
2010 1.052608 0.001261
2011 0.806605 0.001514
9.4 透视表和交叉表
透视表(pivot table)是由各种电子表格程序和其他数据分析软件一种常见的数据汇总工具。
In [3]: tips = pd.read_csv(r"E:\python\pydata-book-master\ch08\tips.csv")
In [5]: tips[:4]
Out[5]:
total_bill tip sex smoker day time size
0 16.99 1.01 Female No Sun Dinner 2
1 10.34 1.66 Male No Sun Dinner 3
2 21.01 3.50 Male No Sun Dinner 3
3 23.68 3.31 Male No Sun Dinner 2
In [6]: tips.pivot_table(rows=['sex','smoker'])
Traceback (most recent call last):
File "<ipython-input-4-de5618d53e2d>", line 1, in <module>
tips.pivot_table(rows=['sex','smoker'])
TypeError: pivot_table() got an unexpected keyword argument 'rows'
查了有关资料,将rows改成index,cols写成全名”columns”:
In [8]: tips.pivot_table(index=['sex','smoker'])
Out[8]:
size tip total_bill
sex smoker
Female No 2.592593 2.773519 18.105185
Yes 2.242424 2.931515 17.977879
Male No 2.711340 3.113402 19.791237
Yes 2.500000 3.051167 22.284500
In [14]: tips.pivot_table(['tip_pct','size'],index = ['sex','day'],columns = 'smoker')
Out[14]:
tip_pct size
smoker No Yes No Yes
sex day
Female Fri 0.165296 0.209129 2.500000 2.000000
Sat 0.147993 0.163817 2.307692 2.200000
Sun 0.165710 0.237075 3.071429 2.500000
Thur 0.155971 0.163073 2.480000 2.428571
Male Fri 0.138005 0.144730 2.000000 2.125000
Sat 0.162132 0.139067 2.656250 2.629630
Sun 0.158291 0.173964 2.883721 2.600000
Thur 0.165706 0.164417 2.500000 2.300000
#传入margins = True作为分项的一个汇总
In [15]: tips.pivot_table(['tip_pct','size'],index = ['sex','day'],columns = 'smoker',margins = True)
Out[15]:
tip_pct size
smoker No Yes All No Yes All
sex day
Female Fri 0.165296 0.209129 0.199388 2.500000 2.000000 2.111111
Sat 0.147993 0.163817 0.156470 2.307692 2.200000 2.250000
Sun 0.165710 0.237075 0.181569 3.071429 2.500000 2.944444
Thur 0.155971 0.163073 0.157525 2.480000 2.428571 2.468750
Male Fri 0.138005 0.144730 0.143385 2.000000 2.125000 2.100000
Sat 0.162132 0.139067 0.151577 2.656250 2.629630 2.644068
Sun 0.158291 0.173964 0.162344 2.883721 2.600000 2.810345
Thur 0.165706 0.164417 0.165276 2.500000 2.300000 2.433333
All 0.159328 0.163196 0.160803 2.668874 2.408602 2.569672
#使用len可以得到有关分组大小的交叉表
In [17]: tips.pivot_table('tip_pct',index = ['sex','smoker'],columns='day',aggfunc = len,margins = True)
Out[17]:
day Fri Sat Sun Thur All
sex smoker
Female No 2.0 13.0 14.0 25.0 54.0
Yes 7.0 15.0 4.0 7.0 33.0
Male No 2.0 32.0 43.0 20.0 97.0
Yes 8.0 27.0 15.0 10.0 60.0
All 19.0 87.0 76.0 62.0 244.0
#如果有空值NA,我们设置fill_value = 0
In [19]: tips.pivot_table('size',index=['time','sex','smoker'],columns='day',aggfunc='sum',fill_value = 0)
Out[19]:
day Fri Sat Sun Thur
time sex smoker
Dinner Female No 2 30 43 2
Yes 8 33 10 0
Male No 4 85 124 0
Yes 12 71 39 0
Lunch Female No 3 0 0 60
Yes 6 0 0 17
Male No 0 0 0 50
Yes 5 0 0 23
9.5 交叉表:crosstab
交叉表是一种计算频率的特殊透视表。
In [20]: pd.crosstab([tips.time,tips.day],tips.smoker,margins=True)
Out[20]:
smoker No Yes All
time day
Dinner Fri 3 9 12
Sat 45 42 87
Sun 57 19 76
Thur 1 0 1
Lunch Fri 1 6 7
Thur 44 17 61
All 151 93 244