
本章内容:
- 操纵日期和缺失值
- 熟悉数据类型的转换
- 变量的创建和重编码
- 数据集的排序,合并与取子集
- 选入和丢弃变量
4。1一个示例
- 处于管理岗的男性和女性在听从上级的程度是否有所不同?
- 这种情况是否依国家的不同而不同,或者说这些性别导致的不同是否普遍存在?
代码4-1 创建leadership数据库
>manager<-c(1,2,3,4,5)
>date<-c("10/24/08","10/28/08","10/1/08","10/12/08","5/1/09")
>country<-c("US","US","UK","UK","UK")
>gender<-c("M","F","F","M","F")
>age<-c(32,45,25,39,99)
>q1<-c(5,3,3,3,2)
>q2<-c(4,5,5,3,2)
>q3<-c(5,2,5,4,1)
>q4<-c(5,5,5,NA,2)
>q5<-c(5,5,2,NA,1)
>leadership<-data.frame(manager,date,country,gender,age,q1,q2,q3,q4,q5,
stringsAsFactors = FALSE)
> leadership
manager date country gender age q1 q2 q3 q4 q5
1 1 10/24/08 US M 32 5 4 5 5 5
2 2 10/28/08 US F 45 3 5 2 5 5
3 3 10/1/08 UK F 25 3 5 5 5 2
4 4 10/12/08 UK M 39 3 3 4 NA NA
5 5 5/1/09 UK F 99 2 2 1 2 1
4。2 创建新变量
创建新变量或者对现有的变量进行变换,语句如下:
变量名------表达式
算术表达式可以用于构造公式(formula)
算术运算符
+ 加 - 减 * 乘 / 除
^或** 求幂 x%%y 求余(xmody) x%/%y 整数除法
设有一mydata数据框,变量为x1,x2,你想创建一个新变量sumx存储以上的两个变量的加和,创建名字为meanx来存储:
sumx<- x1+x2
meanx<- (x1+x2)/2
会产生错误,R不知道x1和x2来自于数据框mydata,正确代码如下:
sumx<- mydata$x1+mydata$x2
meanx<- (mydata$x1+mydata$x2)/2
语句成功执行,但是只会得到一个数据框(mydata)和两个独立的向量(sumx和meanx)
代码4-2 创建新变量
(一)
mydata<-data.frame(x1=c(2,2,6,4),x2=(3,4,2,8))
(二)
mydata$sumx<- mydata$x1 +mydata$x2
mydata$meanx<-(mydata$x1+mydata$x2)/2
attach(mydata)
mydata$sumx<-x1+x2
mydata$meanx<-(x1+x2)/2
detach(mydata)
(三)
mydata<-transform(mydata,sumx=x1+x2,meanx=(x1+x2)/2)
4。3变量的重编码
重编码设计根据同一个变量和或其他变量的现有值创建新值的过程。举例来说,你可能想:
- 将一个连续型变量修改为一组类别值
- 将误编码的值替换为正确的值
- 基于一组分数线创建一个表示及格/不及格的变量
要重编码数据,可以使用R中的一个或多个逻辑运算符。逻辑运算符表大四可返回TRUE和FALSE
逻辑运算符
< 小于
<= 小于或等于
> 大于
>= 大于或等于
== 严格等于
!= 不等于
!x 非x
x|y x或y
x&y x和y
isTRUE(x) 测试x是否为TRUE
不妨假设你希望将leadership数据集中经理人的连续型年龄变量age重编码为类别型变量agecat()
Young、Middle Aged 、Elder)。首先,必须将99岁的年龄值重编码为缺失值,使用的代码为:
leadership$age[leadership$age==99]<-NA
语句variable[condition]<-expression 将尽在condition的值为TURE时执行赋值。
在指定好年龄中的缺失值后,可以借助着使用以下的代码创建agecat变量:
leadership$agecat[leadership$age > 75] <- "Elder"
leadership$agecat[leadership$age>=55$leadership$age<=75]<-"Middle Aged"
leadership$agecat[leadership$age<55]<"Young"
这段代码可以紧凑的写为:
leadership<-within(leadership,{
agecat<-NA
agecat[age>75] <-"Elder"
agecat[age>=55&age<=75] <-"Middle Aged"
agecat[age<55] <-"Young"})
函数within()与函数with()类似,不同的是允许你修改数据框。
cut()函数可以将一个数值型变量按值域切割为多个区间,并返回一个因子。
4。4变量的重命名
若对现有的变量名不满意,可以交互的或以编程的方式修改他们。
如:
fix(leadership)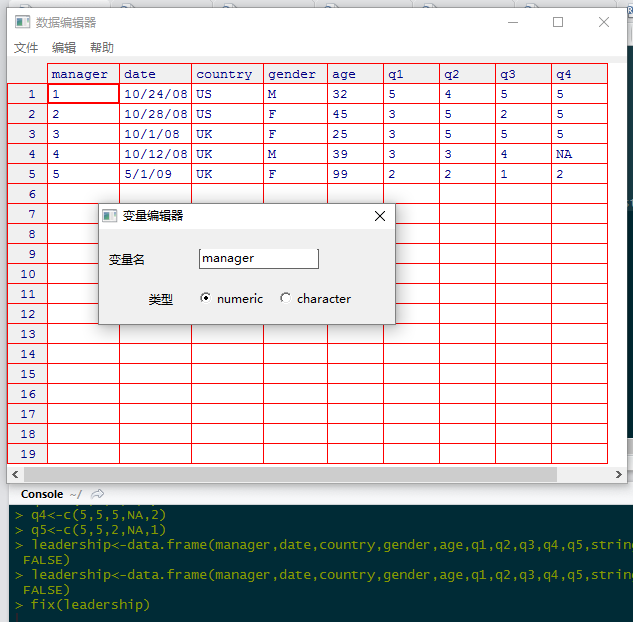
若以编程的方式,reshape包内有一个rename()函数,用于修改变量名。
首次需要先安装,否则:
> library(reshape)
Error in library(reshape) : 不存在叫‘reshape’这个名字的程辑包
我们来安装:
> install.packages("reshape")
接下来使用第四章开头4-1的代码:在历史记录里面载入这些代码,下列代码均在代码4-1后面进行。
> library(reshape)
> leadership<-rename(leadership,c(manager="managerID",date="testID"))
> names(leadership)[2]<-"testDate"
> names(leadership)
[1] "managerID" "testDate" "country" "gender" "age" "q1" "q2"
[8] "q3" "q4" "q5"
> names(leadership)[2]<-"testDate"
> leadership
managerID testDate country gender age q1 q2 q3 q4 q5
1 1 10/24/08 US M 32 5 4 5 5 5
2 2 10/28/08 US F 45 3 5 2 5 5
3 3 10/1/08 UK F 25 3 5 5 5 2
4 4 10/12/08 UK M 39 3 3 4 NA NA
5 5 5/1/09 UK F 99 2 2 1 2 1
> names(leadership)[6:10]<-c("item1","item2","item3","item4","item5")
> leadership
managerID testDate country gender age item1 item2 item3 item4 item5
1 1 10/24/08 US M 32 5 4 5 5 5
2 2 10/28/08 US F 45 3 5 2 5 5
3 3 10/1/08 UK F 25 3 5 5 5 2
4 4 10/12/08 UK M 39 3 3 4 NA NA
5 5 5/1/09 UK F 99 2 2 1 2 1
4。5缺失值
在任何规模的项目中,数据都可能由于未作答问题、设备故障、或者编码数据的缘故不完整。
R中,缺失值以符号NA(Not Available,不可用)表示。不可能出现的值通过符号NaN(Not a Number)来表示。
函数is.na()允许你检测缺失值是否存在。
如:
> y<-c(1,2,3,NA)
> is.na(y)
[1] FALSE FALSE FALSE
某元素为缺失值,相应位置被改为TRUE,不是缺失位置为FALSE。
代码4-3 使用is.na() 函数
> is.na(leadership[,6:10])
item1 item2 item3 item4 item5
[1,] FALSE FALSE FALSE FALSE FALSE
[2,] FALSE FALSE FALSE FALSE FALSE
[3,] FALSE FALSE FALSE FALSE FALSE
[4,] FALSE FALSE FALSE TRUE TRUE
[5,] FALSE FALSE FALSE FALSE FALSE
leadership[,6:10]将数据框限定在第6-10列。
4。5。1重编码某些值为缺失值
让编码为99的数据表示为缺失值。
> leadership$age[leadership$age==99]<-NA
> leadership
managerID testDate country gender age item1 item2 item3 item4 item5
1 1 10/24/08 US M 32 5 4 5 5 5
2 2 10/28/08 US F 45 3 5 2 5 5
3 3 10/1/08 UK F 25 3 5 5 5 2
4 4 10/12/08 UK M 39 3 3 4 NA NA
5 5 5/1/09 UK F NA 2 2 1 2 1
4。5。2在分析中排除缺失值
> x<-c(1,2,NA,3)
> y<-x[1]+x[2]+x[3]+x[4]
> z<-sum(x)
> z
[1] NA
由于x第3个元素缺失,所以y和z也是NA(缺失值)
> x<-c(1,2,NA,3)
> y<-sum(x,na.rm = TRUE)
> y
[1] 6
na.rm = TRUE 选项可以移除缺失值,对剩余值进行计算
na.mit()可以删除所有含有缺失数据的行。
代码4-4 使用na.omit()删除不完整的观测
> leadership
manager date country gender age q1 q2 q3 q4 q5
1 1 10/24/08 US M 32 5 4 5 5 5
2 2 10/28/08 US F 45 3 5 2 5 5
3 3 10/1/08 UK F 25 3 5 5 5 2
4 4 10/12/08 UK M 39 3 3 4 NA NA
5 5 5/1/09 UK F 99 2 2 1 2 1
> newdata<-na.omit(leadership)
> newdata
manager date country gender age q1 q2 q3 q4 q5
1 1 10/24/08 US M 32 5 4 5 5 5
2 2 10/28/08 US F 45 3 5 2 5 5
3 3 10/1/08 UK F 25 3 5 5 5 2
5 5 5/1/09 UK F 99 2 2 1 2 1
4。6日期值
日期值通常以字符串的形式输入到R中,然后转化为以数值形式存储的日期变量,函数as.Date()用于执行这种转化。语法:
as.Date(x,"input_format")
日期的默认值输入格式为yyyy-mm-dd,语句:
mydates<-as.Date(c("2007-06-22","2004-02-13"))
将默认格式字符串数据转换为日期,相反就使用mm/dd/yyyy格式来读取数据
strDates<-c("01/05/1965","08/16/1975")
dates<-as.Date(strDates,"%m/%d/%Y")
两个实用的函数:
Sys.Date()可以返回当天的日期,而date()则返回当前的日期与时间。
> Sys.Date()
[1] "2017-01-18"
> date()
[1] "Wed Jan 18 20:12:48 2017"
使用format()函数来输出指定格式的日期值。
> today<-Sys.Date()
> format(today,format="%B %d %Y")
[1] "一月 18 2017"
> format(today,format="%A")
[1] "星期三"
R的内部存储自1970年1月1日以来的天数表示。更早的日期表示为负数。
这样可以在日期上进行执行的算术运算
> startdate<-as.Date("2000-1-4")
> enddate<-as.Date("2010-1-4")
> days<-enddate-startdate
> days
Time difference of 3653 days
我们使用difftime来计算时间间隔
> today<-Sys.Date()
> born<-as.Date("1993-07-23")
> difftime(today,born,units = "days")
Time difference of 8598 days
> difftime(today,born,units = "week")
Time difference of 1228.286 weeks
4。6。1将日期转换为字符型变量
as.character()函数可以将日期转换为字符型变量:
strDates<-as.character(dates)
转换后使用一系列的字符处理函数处理数据(取子集,替换,连接等)
4。7类型转换
使用类型转换函数来将数据转换为指定类型。
如:
is.numeric() 对应 as.numeric()
名为is.datatype()这样的函数返回TRUE或FALSE,而as.datatype()这样的函数则将其参数转换为对应的类型。
代码4-5 转换数据类型
> library(openxlsx)
> a<-c(1,2,3)
> a
[1] 1 2 3
> is.numeric(a)
[1] TRUE
> is.vector(a)
[1] TRUE
> a<-as.character(a)
> a
[1] "1" "2" "3"
> is.numeric(a)
[1] FALSE
> is.vector(a)
[1] TRUE
> is.character(a)
[1] TRUE
is.datatype()和第5章讨论的控制流结合使用时候,允许根据具体的数据类型以不同的方式处理数据。
as.datatype()函数可以让你在分析之前先将数据转换为要求的格式。
4。8数据排序
order()函数对一个数据进行排序。默认为升序。
在排序变量之前加一个减号就是降序排列。
> leadership
manager date country gender age q1 q2 q3 q4 q5
1 1 10/24/08 US M 32 5 4 5 5 5
2 2 10/28/08 US F 45 3 5 2 5 5
3 3 10/1/08 UK F 25 3 5 5 5 2
4 4 10/12/08 UK M 39 3 3 4 NA NA
5 5 5/1/09 UK F 99 2 2 1 2 1
> newdata<-leadership[order(leadership$age),]
> attach(leadership)
The following objects are masked _by_ .GlobalEnv:
age, country, date, gender, manager, q1, q2, q3, q4, q5
> newdata<-leadership[order(gender,age),]
> detach(leadership)
> newdata
manager date country gender age q1 q2 q3 q4 q5
3 3 10/1/08 UK F 25 3 5 5 5 2
2 2 10/28/08 US F 45 3 5 2 5 5
5 5 5/1/09 UK F 99 2 2 1 2 1
1 1 10/24/08 US M 32 5 4 5 5 5
4 4 10/12/08 UK M 39 3 3 4 NA NA
> attach(leadership)
The following objects are masked _by_ .GlobalEnv:
age, country, date, gender, manager, q1, q2, q3, q4, q5
> newdata<-leadership[order(gender,-age),]
> detach(leadership)
> newdata
manager date country gender age q1 q2 q3 q4 q5
5 5 5/1/09 UK F 99 2 2 1 2 1
2 2 10/28/08 US F 45 3 5 2 5 5
3 3 10/1/08 UK F 25 3 5 5 5 2
4 4 10/12/08 UK M 39 3 3 4 NA NA
1 1 10/24/08 US M 32 5 4 5 5 5
将下标留空(,)表示默认选择所有行。
4。9数据集的合并
本节展示了向数据框中添加列(变量)和行(观测)的方法
- 横向联结通常向数据框添加变量(列)
- 纵向联结通常向数据框添加观测(行)
4。9。1添加列manager()函数用于合并两个数据框(数据集)。
一般,两个数据框是通过一个或多个共有变量进行联结的(一种内联结,inner join)
total<-merge(dataframeA ,dataframeB,by="ID")
将dataframeB按照ID进行合并
total<-merge(dataframeA,dataframeB,by=c("ID","Country"))
若要直接横向合并两个矩阵或数据框,不一定要指定一个公共索引。
使用cbind()函数:
total<-cbind(A,B)
这两个函数将合并对象A和对象B,每个对象必须拥有相同的行数,且以相同顺序排列。
4。9。2添加行
rbind()函数,用于纵向合并两个数据框(数据集)
total<-rbind(dataframeA,dataframeB)
这两个函数将合并对象A和对象B,每个对象必须拥有相同的行数,且以顺序不一定相同。
若dataframeA拥有dataframeB中没有的变量,请在合并之前做以处理:
- 删除dataframeA中多余变量
- 在dataframeB中创建追加的变量将其设为NA(缺失)
4。10 数据集取子集
R拥有强大的索引特性,可以用于访问对象的中的元素,可以利用这些特性对行和列进行选入和排除。
4。10。1选入(保留)变量
> leadership
manager date country gender age q1 q2 q3 q4 q5
1 1 10/24/08 US M 32 5 4 5 5 5
2 2 10/28/08 US F 45 3 5 2 5 5
3 3 10/1/08 UK F 25 3 5 5 5 2
4 4 10/12/08 UK M 39 3 3 4 NA NA
5 5 5/1/09 UK F 99 2 2 1 2 1
> newdata<-leadership[,c(6:10)]
> myvars<-c("q1","q2","q3","q4","q5")
> newdata<-leadership[myvars]
> newdata
q1 q2 q3 q4 q5
1 5 4 5 5 5
2 3 5 2 5 5
3 3 5 5 5 2
4 3 3 4 NA NA
5 2 2 1 2 1
> myvars<-paste("q",1:5,sep="")
> newdata<-leadership[myvars]
> newdata
q1 q2 q3 q4 q5
1 5 4 5 5 5
2 3 5 2 5 5
3 3 5 5 5 2
4 3 3 4 NA NA
5 2 2 1 2 1
注:
- 将下标留空(,)表示默认选择所有行。
- > newdata<-leadership[,c(6:10)]
> myvars<-c("q1","q2","q3","q4","q5")实现了等价的变量选择,引号中变量名充当了列的下标。
4。10。2 剔除(丢弃)变量
语句:
> myvars<-names(leadership) %in% c("q3","q4")
> newdata<-leadership[!myvars]
> newdata
manager date country gender age q1 q2 q5
1 1 10/24/08 US M 32 5 4 5
2 2 10/28/08 US F 45 3 5 5
3 3 10/1/08 UK F 25 3 5 2
4 4 10/12/08 UK M 39 3 3 NA
5 5 5/1/09 UK F 99 2 2 1
分析:
- names(leadership)生成了一个包含变量名的字符型向量:
c("testDate","country","gender","age","q1","q2","q3","q4","q5")2.names(leadership) %in% c("q3","q4") 返回了一个逻辑型向量,names(leadership)中每个匹配q3、q4的元素的值为TRUE,反之为FALSE: c(FALSE,FALSE,FALSE,FALSE,FALSE,FALSE,FALSE,TRUE,TRUE,FALSE)
3.运算符非(!)将逻辑值反转,c(TRUE,TRUE,TRUE,TRUE,TRUE,TRUE,TRUE,FALSE,FALSE,TRUE,)选择了逻辑值为TRUE的值,于是q3和q4被剔除了。
其他的两种方法:
- 知道q3、q4的第8、9个变量,使用:newdata<-leadership[c(-8,-9)]
- 相同的变量删除工作可通过:leadership$q3<-leadership$q4<-NULL
4。10。3选入观测
选入或剔除观测(行)通常是成功的数据准备和数据分析的一个关键要素。
代码4-6 选入观测
> leadership
manager date country gender age q1 q2 q3 q4 q5
1 1 10/24/08 US M 32 5 4 5 5 5
2 2 10/28/08 US F 45 3 5 2 5 5
3 3 10/1/08 UK F 25 3 5 5 5 2
4 4 10/12/08 UK M 39 3 3 4 NA NA
5 5 5/1/09 UK F 99 2 2 1 2 1
> newdata<-leadership[1:3,]
> newdata<-leadership[which(leadership$gender=="M"&leadership$age>30),]
> newdata
manager date country gender age q1 q2 q3 q4 q5
1 1 10/24/08 US M 32 5 4 5 5 5
4 4 10/12/08 UK M 39 3 3 4 NA NA
> attach(leadership)
The following objects are masked _by_ .GlobalEnv:
age, country, date, gender, manager, q1, q2, q3, q4, q5
> newdata<-leadership[which(gender=='M'& age>30),]
> detach(leadership)
> newdata
manager date country gender age q1 q2 q3 q4 q5
1 1 10/24/08 US M 32 5 4 5 5 5
4 4 10/12/08 UK M 39 3 3 4 NA NA
分析:
- 逻辑比较leadership$gender=="M"生成了向量c(TRUE,FALSE,FALSE,TRUE,FALSE)
- 逻辑比较leadership$age>30,生成了向量c(TRUE,TRUE,FALSE,TRUE,TRUE)
- 逻辑比较c(TRUE,FALSE,FALSE,TRUE,TRUE)&c(TRUE,TRUE,FALSE,TRUE,TRUE)生成了向量c(TRUE,FALSE,FALSE,TRUE,FALSE)
- 函数which()给出了向量中值为TRUE元素的下标。因此,生成向量which(c(TRUE,FALSE,FALSE,TRUE,FALSE)),生成了向量c(1,4)
- leadership[c(1,4),]从数据框中选择了第一个和第四个观测。这就满足了我们的选取准则。(30岁以上的男性)
本章节开头部分,提到了希望将研究范围确定到2009-1-1到2009-12-31,如下可以实现:
> leadership$date<-as.Date(leadership$date,"%m/%d/%y")
> startdate<-as.Date("2009-01-01")
> enddate<-as.Date("2009-10-31")
> newdata<-leadership[which(leadership$date>=startdate&leadership$date<=enddate),]
> newdata
manager date country gender age q1 q2 q3 q4 q5
5 5 2009-05-01 UK F 99 2 2 1 2 1
4。10。4 subset()函数
使用subset()函数可以实现选择变量和观测变量,
> newdata<-subset(leadership,age>35|age<24,select = c(q1,q2,q3,q4))
> newdata
q1 q2 q3 q4
2 3 5 2 5
4 3 3 4 NA
5 2 2 1 2
> newdata<-subset(leadership,gender=='M'&age>25,select = gender:q4)
> newdata
gender age q1 q2 q3 q4
1 M 32 5 4 5 5
4 M 39 3 3 4 NA
4。10。5随机抽样
数据挖掘和机器学习领域,从更大的数据集抽样很常见。
例如:你可能希望选择两份随机样本,使其中一份样本构建预测模型,使用另外一种样本验证模型得到有效性。
sample()函数能够从数据集中(有放回或无放回的)抽取大小为n的样本。
例如:
> mysample<-leadership[sample(1:nrow(leadership),3,replace = FALSE),]
> mysample
manager date country gender age q1 q2 q3 q4 q5
5 5 2009-05-01 UK F 99 2 2 1 2 1
4 4 2008-10-12 UK M 39 3 3 4 NA NA
3 3 2008-10-01 UK F 25 3 5 5 5 2
分析:
- sample()函数第一个参数是一个由要从中抽样的元素组成的向量。
- 第二个参数是要抽取的元素数量
- 第三个参数表示无放回抽样
4。11 使用SQL语句操作数据框
先安装sqldf包(install.packages("sqldf"))
安装完成后,使用SQL中的SELECT语句
我在安装sqldf包的时候出了一些小插曲。其实安装了好几次是不断报错的。那么我是如何解决的呢?
我使用Rtudio环境,安装sqldb几次出错。网上没有好的教程。
经过自己试验之后,这样处理。我写出来以后,供大家参考。
> install.packages("sqldf")
also installing the dependencies ‘BH’, ‘plogr’, ‘gsubfn’, ‘proto’, ‘RSQLite’, ‘DBI’, ‘chron’
trying URL 'https://cran.rstudio.com/bin/windows/contrib/3.3/BH_1.62.0-1.zip'
Content type 'application/zip' length 16150075 bytes (15.4 MB)
downloaded 3.8 MB
...
Warning in install.packages :
error 1 in extracting from zip file
Warning in install.packages :
cannot open compressed file 'BH/DESCRIPTION', probable reason 'No such file or directory'
Error in install.packages : cannot open the
我们看到报错了。
解决办法:
1.彻底退出你的360。
2.在RStudio里设置在某个镜像站下载包的
在Rtudio中菜单栏点击tool>global option>packages>change
选择China (Beijing) [https] - TUNA Team, Tsinghua University
然后就可以安装出来了。
> install.packages("sqldf")
also installing the dependencies ‘BH’, ‘plogr’, ‘gsubfn’, ‘proto’, ‘RSQLite’, ‘DBI’, ‘chron’
...
The downloaded binary packages are in
C:\Users\yichenfan\AppData\Local\Temp\RtmpOO6hO7\downloaded_packages
输入library(sqldf)
> library(sqldf)
载入需要的程辑包:gsubfn
载入需要的程辑包:proto
载入需要的程辑包:RSQLite
> newdf<-sqldf("select * from mtcars where carb=1 order by mpg",row.names=TRUE)
Loading required package: tcltk
Warning message:
Quoted identifiers should have class SQL, use DBI::SQL() if the caller performs the quoting.
我们看到又报错了。
我们检查一下tcltk
> capabilities()["tcltk"]
tcltk
TRUE
此时我们使用SQL语句,就可以操作了
> library(sqldf)
> newdf<-sqldf("select * from mtcars where carb=1 order by mpg",row.names=TRUE)
> newdf
mpg cyl disp hp drat wt qsec vs am gear carb
Valiant 18.1 6 225.0 105 2.76 3.460 20.22 1 0 3 1
Hornet 4 Drive 21.4 6 258.0 110 3.08 3.215 19.44 1 0 3 1
Toyota Corona 21.5 4 120.1 97 3.70 2.465 20.01 1 0 3 1
Datsun 710 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1
Fiat X1-9 27.3 4 79.0 66 4.08 1.935 18.90 1 1 4 1
Fiat 128 32.4 4 78.7 66 4.08 2.200 19.47 1 1 4 1
Toyota Corolla 33.9 4 71.1 65 4.22 1.835 19.90 1 1 4 1
代码清单4-7 使用SQL语句操作数据框
> library(sqldf)
> newdf<-sqldf("select * from mtcars where carb=1 order by mpg",row.names=TRUE)
> newdf
mpg cyl disp hp drat wt qsec vs am gear carb
Valiant 18.1 6 225.0 105 2.76 3.460 20.22 1 0 3 1
Hornet 4 Drive 21.4 6 258.0 110 3.08 3.215 19.44 1 0 3 1
Toyota Corona 21.5 4 120.1 97 3.70 2.465 20.01 1 0 3 1
Datsun 710 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1
Fiat X1-9 27.3 4 79.0 66 4.08 1.935 18.90 1 1 4 1
Fiat 128 32.4 4 78.7 66 4.08 2.200 19.47 1 1 4 1
Toyota Corolla 33.9 4 71.1 65 4.22 1.835 19.90 1 1 4 1
> sqldf("select avg(mpg) as avg_mpg,avg(disp) as avg_disp,gear from mtcars where cyl in (4,6) group by gear")
avg_mpg avg_disp gear
1 20.33333 201.0333 3
2 24.53333 123.0167 4
3 25.36667 120.1333 5
sqldf包是R中的一个实用的数据管理辅助工具。