

本章内容
- 数学和统计函数
- 字符处理函数
- 循环和条件执行
- 自编函数
- 数据整合与重塑
本章的三个基本部分:(1)浏览R中的多种数学、统计和字符处理函数;(2)如何自己编写函数来完成数据处理和分析任务;(3)了解数据的整合和概述方法,以及数据集的重塑和重构方法
5。1一个数据处理难题
表5-1的数据难题:(1)三组数据之间的均值和标准值差距太远,求均值无意义。(2)表示姓名的字段只有一个。
5。2数值和字符处理函数
本节我们将综述R中作为数据处理基石的函数——数值(数学、统计、概率)函数和字符处理函数。
5。2。1数学函数
常用的数学函数:
- abs(x) 绝对值(如:abs(-4)返回值为4)sqrt(x) 开方(如:sqrt(25)返回值为5)
- ceiling(x) 不小于x的最小整数(如:ceiling(3.75)返回值为4)
- floor(x) 不大于x的最大整数(如:floor(3.75)返回值为3)
- trunc(x) 向0的方向截取的x的整数部分(如:trunc(5.99)返回值为5)
- round(x,digits=n) 将x舍入为指定位的小数(round(3.475,digits返回值为3.48))
- signif(x,digits=n) 将x舍入为有效位的小数(signif(3.475,digits返回值为3.5))
- cos(x)sin(x)tan(x) 余弦、正弦、正切
- log(x,base=n) 对x取n为底的对数
- log(x) 自然对数
- exp(x) 指数函数
这些函数被应用于数值向量、矩阵或数据框时候,他们会作用于每一个独立的值。
如:
sqrt(c(4,25))=c(2,5)
5。2。2统计函数
- mean(x) 平均数 (如:mean(c(1,2,3,4))返回值为2.5)median(x) 中位数 (如:median(c(1,2,3,4))返回值为2.5)
- sd(x) 标准差 (sd(c(1,2,3,4))返回值为1.29)
- var(x) 方差 (var(c(1,2,3,4)返回值为1.67))
- mad(x) 绝对中位差 (mad(c(1,2,3,4))返回值为1.48)
- quantile(x,probs) 求分位数,其中x为待求分位数的数值型向量,probs为一个由[0,1]之间的 概率值组成的求数值向量 #求x的30%的84%分位点
- range(x) 求值域 (x<-c(1,2,3,4),range(x)返回值为c(1,4))
- sum(x) 求和
- diff(x,lag=n) 滞后差分,lag用以指定滞后几项,默认为1。
- min(x) 求最小值
- max(x) 求最大值
- scale(x,center=TRUE,scale=TRUE) 为数据对象x按列进行中心化(center=TRUE)或标准化(center=TRUE,sacle=TRUE)
代码5-1 均值和标准差的计算
> x<-c(1,2,3,4,5,6,7,8)
> mean(x) #使用简洁的方式求平均数
[1] 4.5
> sd(x)
[1] 2.44949
> n<-length(x) #返回元素的数量
> meanx<-sum(x)/n #使用冗长的方式
> css<-sum((x-meanx)^2) #从每个元素中减去4.5,将“从每个元素中减去4.5”的数平方
> sdx<-sqrt(css/(n-1))
> meanx
[1] 4.5
> sdx
[1] 2.44949
数据的标准化
默认情况下,函数scale()对矩阵或数据框的指定列进行均值为0,标准差为1的标准化
newdata<-scale(mydata)
要对每一列进行任意均值和标准差的标准化,使用如下代码:
newdata<scale(mydata)*SD+M #M是想要的均值,SD为想要的标准差
要对指定列而不是整个矩阵或数据框进行标准化,如下代码:
newdata<-transform(mydata,myvar=scale(myvar)*10+50) #将变量myvar标准化为均值50,标准化为10的变量
5。2。3概率函数
概率函数通常用来生成已知的模拟数据,以及在用户编写的统计函数中计算概率值。
在R中,概率函数形如:
[dpqr]distribution_abbreviation()
其中,第一个字母表示其所指分布的某一方面:
- d=密度函数(density)p=分布函数(distribution function)
- q=分位数函数(quantile function)
- r=生成随机函数(随机偏差)
在区间[-3,3]上绘制正态曲线
x<-pretty(c(-3,3),30)
y<-dnorm(x)
plot(x,y,type = "l",xlab = "NormalDeviate",ylab = "Density",yaxs="i") 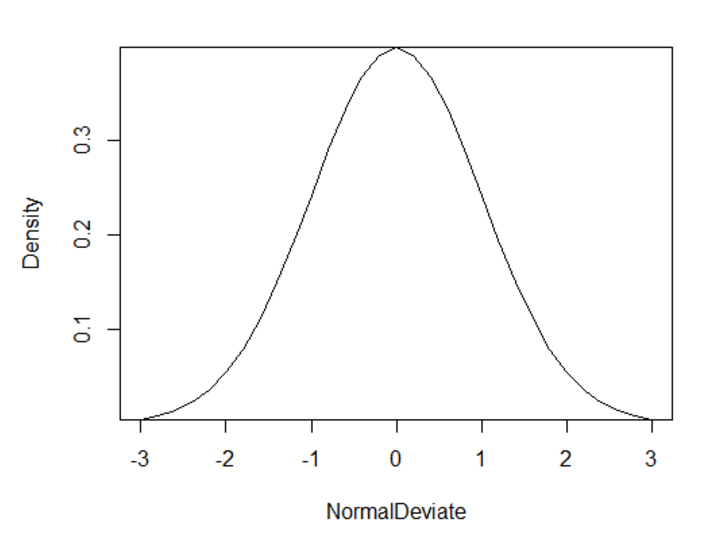
> pnorm(1.96)
[1] 0.9750021
> qnorm(.9,mean = 500,sd=100)
[1] 628.1552
> rnorm(50,mean = 50,sd=10)
[1] 66.30140 58.32200 50.19828 56.18099 46.90776 51.06160 58.46110 51.92753 44.97088 44.99317
[11] 49.19300 48.83648 50.36169 37.70426 41.06964 47.22941 43.85674 49.65857 68.77963 50.79890
[21] 37.79954 38.39293 59.27305 36.92903 70.40379 61.38188 53.52293 57.60498 58.16075 50.08207
[31] 41.84147 49.72898 33.52840 45.37547 44.40262 41.51579 41.78792 44.97260 39.99328 39.92351
[41] 53.17448 40.12112 55.12697 61.39707 33.23622 50.85639 46.25131 64.34144 31.82201 47.06960
(1)位于z=1.96左侧的标准正态曲线下方面积是多少?
> pnorm(1.96)
[1] 0.9750021
(2)均值为500,标准差为100的正态分布的0.9的分位点是多少?
> qnorm(.9,mean = 500,sd=100)
[1] 628.1552
(3)生成50个均值为50,标准差为10的正态函数?
> rnorm(50,mean = 50,sd=10)
1。设定随机种子
每次生成伪随机数时,生成不同的种子。通过函数set.seed()显式指定这个种子,让结果重现。
函数runif()用来生成区间[0,1]上服从均匀分布的伪随机数。
代码5-2 生成正态分布的伪随机数
> runif(5)
[1] 0.4395987 0.0939289 0.6490620 0.6654249 0.8139327
> runif(5)
[1] 0.7330382 0.5172171 0.5665933 0.7015867 0.4579476
> set.seed(1234)
> runif(5)
[1] 0.1137034 0.6222994 0.6092747 0.6233794 0.8609154
> set.seed(1234)
> runif(5)
[1] 0.1137034 0.6222994 0.6092747 0.6233794 0.8609154
手动设定种子,就可以重现结果。
***2。生成多元正态数据
在模拟研究 和蒙特卡洛方法中,你经常需要获取来自给定均值向量和协方差的多元正态分布的数据。MASS包中的mvrnorm()函数可以搞定这个问题。格式:
mvrnorm(n,mean,sigma)
n是想要的样本,mean为均值向量,sigma是方差-协方差矩阵
在5-3代码中,从下表的三元正态分布中抽取500个观测。

代码5-3 生成服从多元正态分布的数据
> library(MASS)
> options(digits = 3)
> set.seed(1234) #设定随机种子
> mean<-c(230.7,146.7,3.6) #指定均值向量,协方差
#从矩阵转换为数据框
> sigma<-matrix(c(15360.8,6721.2,-47.1,6721.2,4700.9,-16.5,-47.1,-16.5,0.3),nrow = 3,ncol = 3)
> mydata<-mvrnorm(500,mean,sigma) #生成500个伪随机观测
> mydata<-as.data.frame(mydata)
> names(mydata)<-c("y","x1","x2")
> dim(mydata) #查看结果,有500个观测和3个变量
[1] 500 3
> head(mydata,n=10) #输出前10个观测
y x1 x2
1 98.8 41.3 3.43
2 244.5 205.2 3.80
3 375.7 186.7 2.51
4 -59.2 11.2 4.71
5 313.0 111.0 3.45
6 288.8 185.1 2.72
7 134.8 165.0 4.39
8 171.7 97.4 3.64
9 167.2 101.0 3.50
10 121.1 94.5 4.10
5。2。4字符处理函数
字符处理函数可以从文本型数据中抽取信息,或者为打印输出和生成报告重设文本的格式。
字符处理函数
- nchar() 计算x中的字符数量 x<-c("cdv","fwe","wffef") length(x)的返回值是5
- substr(x,start,stop) 提取或替换一个字符向量中的子串
- x<-"abcdef" substr(x,2,4)返回值为“bcd”
- grep(pattern,x,ignore.case=FALSE,fixed=FALSE)在x中搜索某种模式若fixed=FALSE则pattern为一个正则,表达式,若fixed=TRUE,则pattern为一个文本字符串。
- grep("A",c("b","A","c"),fixed=TRUE)返回值2。
- paste(... ,sep="") 连接字符串,分隔符为sep
- paste("x",1:3,sep="")返回值c("x1","x2","x3")
- toupper(x) 大写转换
- tolower(x) 小写转换
函数grep()、sub()、strsplit()能够搜索某个文本字符串(fixed=TRUE)或某个正则表达式(fixed=FALSE,默认值为FALSE)。正则表达式为文本模式的匹配提供了一套清晰而简练的语法。
5。2。5 其他实用函数
- length(x) 对象x的长度 x<- c(2,5,6,9) length(x) 返回值为4seq(from,to,by) 生成一个序列 如:indices<-seq(1,10)
- indices的值为 c(1,3,5,7,9)
- rep(x,n) 将x重复n次 y<-rep(1:3,2) y的返回值为c(1,2,3,1,2,3)
- cut(x,n) 将连续变量x分割为有着n个水平的因子使用ordered_result=TRUE可以创建一个有序因子
- pretty(x,n) 创建美观的分割点,通过选取n+1个等间距的去整值,将一个连
- 续型变量x分割为n个区间,绘图常用
5。2。6 将函数应用于矩阵和数据框
R语言可以应用到一系列的数据对象上,包括标量、向量、矩阵、数组和数据框。
代码5-4 将函数应用于数据对象
> a<-5
> sqrt(a) #开方
[1] 2.236068
> b<-c(1.234,5.654,2.99)
> round(b) #对数值进行四舍五入
[1] 1 6 3
> c<-matrix(runif(12),nrow=3) #runif是生成[0,1]上均匀分布的随机数
> c
[,1] [,2] [,3] [,4]
[1,] 0.96359936 0.2160280 0.2890082 0.9128172
[2,] 0.20676238 0.2396466 0.8041144 0.3533918
[3,] 0.08619744 0.1971609 0.3782496 0.9314871
> log(c) #求对数
[,1] [,2] [,3] [,4]
[1,] -0.03707967 -1.532347 -1.2413001 -0.09121962
[2,] -1.57618505 -1.428590 -0.2180137 -1.04017797
[3,] -2.45111479 -1.623735 -0.9722009 -0.07097292
> mean(c) #求平均值,求矩阵中全部的12个元素均值
[1] 0.4648719
apply()函数,可将一个任意函数“应用”到矩阵、数组、数据框的任何维度上。
apply函数的使用格式为:
apply(x,MARGIN,FUN,...)
x为对象,MARGIN是维度下标,FUN是由你指定的函数,而...则包括了任何想传递给FUN的参数,在矩阵或数据框中,MARGIN=1表示行,MARGIN=2表示列。
FUN为任意R函数,这也包括自行编写的函数。
lapply()和sapply()可将函数应用到列表(list)上。
代码5-5 将一个函数应用到矩阵的所有列(列)
#生成了一个包含正态随机数的6*5矩阵
> mydata<-matrix(rnorm(30),nrow = 6)
> mydata
[,1] [,2] [,3] [,4] [,5]
[1,] 0.4585260 1.2031271 1.2338845 0.5905186 -0.2806204
[2,] -1.2611491 0.7688732 -1.8913847 -0.4351408 0.8120776
[3,] -0.5274652 0.2383510 -0.2226513 -0.2507699 -0.2077037
[4,] -0.5568142 -1.4150281 0.7681275 -0.9262694 1.4507573
[5,] -0.3744387 2.9337744 0.3879537 1.0874358 0.8414932
[6,] -0.6044000 0.9350258 0.6091330 -1.9439592 -0.8657378
#计算了6行的均值
> apply(mydata,1,mean)
[1] 0.6410872 -0.4013448 -0.1940478 -0.1358454 0.9752437 -0.3739876
#计算了5列的均值
> apply(mydata,2,mean)
[1] -0.4776235 0.7773539 0.1475105 -0.3130308 0.2917110
#计算每列的截尾均值(截尾值基于中间60%的数据,最高和最低20%的值被忽略)
> apply(mydata,2,mean,trim=0.2)
[1] -0.5157795 0.7863443 0.3856407 -0.2554154 0.2913117
5-3 数据处理难题的一套解决方案
下列代码给出了解决5.1节的方法。
表5-1的数据难题:(1)三组数据之间的均值和标准值差距太远,求均值无意义。(2)表示姓名的字段只有一个。
代码5-6 示例5-1的解决办法
> options(digits=2)
> Student<-c("John Davis","Angela Williams","Bullwinkle Moose","David Jones","Janice Markhammer","Cheryl Cushing","Reuven Ytzrhak","Greg Knox","Joel England","Mary Rayburn")
> Math<-c(502,600,412,358,495,512,410,625,573,522)
> Science<-c(95,99,80,82,75,85,80,95,89,86)
> English<-c(25,22,18,15,20,28,15,30,27,18)
> roster<-data.frame(Student,Math,Science,English,stringsAsFactors = FALSE)
> z<-scale(roster[,2:4]) #计算综合得分
> score<-apply(z,1,mean)
> roster<-cbind(roster,score)
> y<-quantile(score,c(.8,.6,.4,.2)) #对学生评分
> roster$grade[score<y[1] & score>=y[2]]<-"B"
> roster$grade[score<y[2] & score>=y[3]]<-"B"
> roster$grade[score<y[3] & score>=y[4]]<-"B"
> roster$grade[score<y[4] ]<-"F"
> name<-strsplit((roster$Student)," ") #抽取姓氏和名字
> lastname<- sapply(name,"[",2)
> firstname<- sapply(name,"[",1)
> roster<-cbind(firstname,lastname,roster[,-1])
> roster<-roster[order(lastname,firstname),] #根据姓氏和名字排序
> roster
firstname lastname Math Science English score grade
6 Cheryl Cushing 512 85 28 0.35 C
1 John Davis 502 95 25 0.56 B
9 Joel England 573 89 27 0.70 B
4 David Jones 358 82 15 -1.16 F
8 Greg Knox 625 95 30 1.34 A
5 Janice Markhammer 495 75 20 -0.63 D
3 Bullwinkle Moose 412 80 18 -0.86 D
10 Mary Rayburn 522 86 18 -0.18 C
2 Angela Williams 600 99 22 0.92 A
7 Reuven Ytzrhak 410 80 15 -1.05 F
代码分析:
(1)options(digits=2) 设置全局的数字有效位数,限定了输出小数点后数字的位数。
> options(digits=2)
> roster
Student Math Science English
1 John Davis 502 95 25
2 Angela Williams 600 99 22
3 Bullwinkle Moose 412 80 18
4 David Jones 358 82 15
5 Janice Markhammer 495 75 20
6 Cheryl Cushing 512 85 28
7 Reuven Ytzrhak 410 80 15
8 Greg Knox 625 95 30
9 Joel England 573 89 27
10 Mary Rayburn 522 86 18
(2)由于数学、英文、科学的考试分值不同(均值和标准差相去甚远),我们先让他们变得可比较。
将变量进行标准化,用函数scale()来实现。z<-scale(roster,[,2:4])
scale(x,center=TRUE,scale=TRUE) 为数据对象x按列进行中心化(center=TRUE)或标准化(center=TRUE,sacle=TRUE)
> z<-scale(roster[,2:4])
> z
Math Science English
[1,] 0.013 1.078 0.587
[2,] 1.143 1.591 0.037
[3,] -1.026 -0.847 -0.697
[4,] -1.649 -0.590 -1.247
[5,] -0.068 -1.489 -0.330
[6,] 0.128 -0.205 1.137
[7,] -1.049 -0.847 -1.247
[8,] 1.432 1.078 1.504
[9,] 0.832 0.308 0.954
[10,] 0.243 -0.077 -0.697
(3)在通过函数mean()来计算各行的均值以获得综合得分,使用函数cbind()将其添加到花名册中。
> score<-apply(z,1,mean)
> roster<-cbind(roster,score)
> roster
Student Math Science English score
1 John Davis 502 95 25 0.56
2 Angela Williams 600 99 22 0.92
3 Bullwinkle Moose 412 80 18 -0.86
4 David Jones 358 82 15 -1.16
5 Janice Markhammer 495 75 20 -0.63
6 Cheryl Cushing 512 85 28 0.35
7 Reuven Ytzrhak 410 80 15 -1.05
8 Greg Knox 625 95 30 1.34
9 Joel England 573 89 27 0.70
10 Mary Rayburn 522 86 18 -0.18
(4)函数quantile()给出了学生综合得分的百分数。A的分界点是0.74,B的分界点是0.44
quantile(x,probs) 求分位数,其中x为待求分位数的数值型向量,probs为一个由[0,1]之间的
概率值组成的求数值向量 #求x的30%的84%分位点
> y<-quantile(score,c(.8,.6,.4,.2))
> y
80% 60% 40% 20%
0.74 0.44 -0.36 -0.89
(5)通过逻辑运算符,可以将学生的百分数排名重编码为一个新的类别型成绩变量。
我们在数据框roster中创建变量grade
> roster$grade[score>=y[1]]<-"A"
> roster$grade[score<y[1] & score>=y[2]]<-"B"
> roster$grade[score<y[2] & score>=y[3]]<-"C"
> roster$grade[score<y[3] & score>=y[4]]<-"D"
> roster$grade[score<y[4] ]<-"F"
> roster
Student Math Science English score grade
1 John Davis 502 95 25 0.56 B
2 Angela Williams 600 99 22 0.92 A
3 Bullwinkle Moose 412 80 18 -0.86 D
4 David Jones 358 82 15 -1.16 F
5 Janice Markhammer 495 75 20 -0.63 D
6 Cheryl Cushing 512 85 28 0.35 C
7 Reuven Ytzrhak 410 80 15 -1.05 F
8 Greg Knox 625 95 30 1.34 A
9 Joel England 573 89 27 0.70 B
10 Mary Rayburn 522 86 18 -0.18 C
(6)strsplit()函数以空格为界把学生姓名拆分为姓氏和名字。把strsplit()应用到一个字符串组成的向量上会返回一个列表
> name<-strsplit((roster$Student)," ")
> name
[[1]]
[1] "John" "Davis"
[[2]]
[1] "Angela" "Williams"
[[3]]
[1] "Bullwinkle" "Moose"
[[4]]
[1] "David" "Jones"
[[5]]
[1] "Janice" "Markhammer"
[[6]]
[1] "Cheryl" "Cushing"
[[7]]
[1] "Reuven" "Ytzrhak"
[[8]]
[1] "Greg" "Knox"
[[9]]
[1] "Joel" "England"
[[10]]
[1] "Mary" "Rayburn"
(7)我们现在完成有Student变量向所拆分的名和姓的变量的替换。
"[" 是可以提取某个对象的一部分函数,这里来提取列名name的第一或第二个元素。使用sapply()函数提取列表中的每个成分的第一个元素,放入一个存储名字的向量Firstname,提取列表中的每个成分的第二个元素,储存姓氏放入放入Lastname
> lastname<- sapply(name,"[",2)
> firstname<- sapply(name,"[",1)
> roster<-cbind(firstname,lastname,roster[,-1])
> roster
firstname lastname Math Science English score grade
1 John Davis 502 95 25 0.56 B
2 Angela Williams 600 99 22 0.92 A
3 Bullwinkle Moose 412 80 18 -0.86 D
4 David Jones 358 82 15 -1.16 F
5 Janice Markhammer 495 75 20 -0.63 D
6 Cheryl Cushing 512 85 28 0.35 C
7 Reuven Ytzrhak 410 80 15 -1.05 F
8 Greg Knox 625 95 30 1.34 A
9 Joel England 573 89 27 0.70 B
10 Mary Rayburn 522 86 18 -0.18 C
(8)order()函数将按照姓氏和名字对数据集进行排序
> roster<-roster[order(lastname,firstname),]
> roster
firstname lastname Math Science English score grade
6 Cheryl Cushing 512 85 28 0.35 C
1 John Davis 502 95 25 0.56 B
9 Joel England 573 89 27 0.70 B
4 David Jones 358 82 15 -1.16 F
8 Greg Knox 625 95 30 1.34 A
5 Janice Markhammer 495 75 20 -0.63 D
3 Bullwinkle Moose 412 80 18 -0.86 D
10 Mary Rayburn 522 86 18 -0.18 C
2 Angela Williams 600 99 22 0.92 A
7 Reuven Ytzrhak 410 80 15 -1.05 F
5。4控制流
R语言也有一半现代编程语言中都有的标准控制结构。
牢记以下概念:
- 语句(statement)是一条单独的R语句或一组复合语句(包含在花括号{ }中的一组R语句,使用分号分隔)
- 条件(cond)是一条最终被解析为真(TRUE)或假(FALSE)的表达式
- 表达式(expr)是一条数值或字符串的求职语句
- 序列(seq) 是一个数值或字符串序列
5 。4。1 重复和循环
循环结构重复的执行一个或一系列语句,直到某个条件不为真为止。
循环结构包括:for和while结构
1。for结构
for循环重复的执行一个语句,直到某个变量的值不再包含在序列seq中为止。
语法:
for (var in seq) statement
例如:
> for (i in 1:10) print ("Hello")
[1] "Hello"
[1] "Hello"
[1] "Hello"
[1] "Hello"
[1] "Hello"
[1] "Hello"
[1] "Hello"
[1] "Hello"
[1] "Hello"
[1] "Hello"
将Hello输出了10次
2。while结构
while循环重复执行一个语句,直到条件不为真为止。
语法:
while (cond) statement
例如:
> i<-10
> while (i>0) (print("Hello");i<-i-1)
Error: unexpected ';' in "while (i>0) (print("Hello");"
> while (i>0) {print("Hello");i<-i-1}
[1] "Hello"
[1] "Hello"
[1] "Hello"
[1] "Hello"
[1] "Hello"
[1] "Hello"
[1] "Hello"
[1] "Hello"
[1] "Hello"
[1] "Hello"
将Hello输出了10次,而且我们注意到,print外面是圆括号的时候报错,花括号的时候才能输出结果!
注意:处理大数据集的行和列时候,R中的循环可能比较低效费时,最好可以联用R中的内建数值/字符处理函数和apply族函数
5 。4。2 条件执行
在条件执行结构中,一条或一组语句仅在满足一个指定条是执行。
条件执行结构的包括:if-else、 ifelse 、switch
1. if-else结构
控制结构if-else在某个指定条件为真执行语句;也在条件为假的时候执行另外的语句
语法:
if (cond) statement
if (cond) statement1 else statement2
2. ifelse
ifelse结构是if-else结构比较紧凑的向量化版本,语法:
ifelse (cond,statement1,statement2)
若cond为TRUE,则执行第一个语句;若cond为FALSE,则执行第二个语句。
3. switch
switch根据一个表达式的值选择语句执行。语法:
switch(expr,....)
其中....表示与expr的各种可能输出值绑定的语句。
代码5-7 一个switch示例
> feeling<-c("sad","afraid")
> for (i in feeling)
+ print(
+ switch(i,
+ happy="I am glad you are happy",
+ afraid="There is nothing to fear",
+ sad="Cheer up",
+ angry="Calm down now"
+ )
+ )
[1] "Cheer up"
[1] "There is nothing to fear"
5。5 用户自编函数
R语言最大的优点之一就是用户可以自行添加函数。一个函数的结构大概如下:
myfunction<-function(arg1,arg2,...)
{
statements
return(object)
}
函数中的对象只在函数内部使用;返回对象的数据类型是任意的,从标量到列表都可以。
下列代码就是,编写一个函数,要求是用来计算数据对象的集中趋势和散布情况。
分析:函数应当可以选择性的给出参数统计量(均值和标准值)和非参数统计量(中位数和绝对中位差)。结果的给出形式应该是含名称列表的形式。
代码5-8 mystats(): 一个由用户编写的描述性统计量计算函数
> mystats<-function(x,parametric=TRUE,print=FALSE)
+ {
+ if (parametric)
+ {
+ center<-mean(x);spread<-sd(x)
+ }
+ else
+ {
+ center<-median(x);spread<-mad(x)
+ }
+ if (print & parametric) {cat("Mean=",center,"\n","SD=",spread,"\n")}
+ else if (print & !parametric) {cat("Median=",center,"\n","MAD=",spread,"\n")}
+ result<list(center=center,spread=spread)
+ return(result)
+ }
> set.seed(1234)
> x<-rnorm(500)
> y<-mystats(x)
> y<-mystats(x,parametric = FALSE,print=TRUE)
Median= -0.021
MAD= 1
函数可以让用户选择输出当天日期的格式。在函数声明中,为参数指定的值作为默认值。
> mydate<-function(type="long")
+ {
+ switch(type,
+ long=format(Sys.time(),"%A%B%d%Y"),
+ short=format(Sys.time(),"%m-%d-%y"),
#cat()函数将在输入的日期函数格式不匹配时候执行
+ cat(type,"is not a recongnized type\n")
+ )
+ }
> mydate("long")
[1] "星期日二月52017"
> mydate("short")
[1] "02-5-17"
> mydate()
[1] "星期日二月52017"
> mydate("medium")
medium is not a recongnized type
5 。6整合与重构
整合计算时,观测将替换为根据这些观测计算的描述性统计量
在重塑数据时,通过修改数据的结构(行和列)来决定数据的组织方式
5。6。1转置
使用 t() 函数就可以对一个矩阵或数据框进行转置(反转行和列)
代码5-9 数据集的转置
> cars<-mtcars[1:5,1:4]
> cars
mpg cyl disp hp
Mazda RX4 21 6 160 110
Mazda RX4 Wag 21 6 160 110
Datsun 710 23 4 108 93
Hornet 4 Drive 21 6 258 110
Hornet Sportabout 19 8 360 175
> t(cars)
Mazda RX4 Mazda RX4 Wag Datsun 710 Hornet 4 Drive Hornet Sportabout
mpg 21 21 23 21 19
cyl 6 6 4 6 8
disp 160 160 108 258 360
5。6。2整合数据
在R中使用一个或多个by变量和一个预先定义好的函数来折叠数据。格式:
aggregate(x,by,FUN)
x是待折叠的数据对象
by是一个变量名组成的列表(这些变量将被去掉以形成新的观测)
FUN是计算描述性统计量的标量函数(被用来计算新观测的值)
代码5-10 整合数据
> options(digits = 3)
> attach(mtcars)
The following objects are masked from mtcars (pos = 3):
am, carb, cyl, disp, drat, gear, hp, mpg, qsec, vs, wt
> aggdata<-aggregate(mtcars,by=list(cyl,gear),FUN=mean,na.rm=TRUE)
> aggdata
Group.1 Group.2 mpg cyl disp hp drat wt qsec vs am gear carb
1 4 3 21.5 4 120 97 3.70 2.46 20.0 1.0 0.00 3 1.00
2 6 3 19.8 6 242 108 2.92 3.34 19.8 1.0 0.00 3 1.00
3 8 3 15.1 8 358 194 3.12 4.10 17.1 0.0 0.00 3 3.08
4 4 4 26.9 4 103 76 4.11 2.38 19.6 1.0 0.75 4 1.50
5 6 4 19.8 6 164 116 3.91 3.09 17.7 0.5 0.50 4 4.00
6 4 5 28.2 4 108 102 4.10 1.83 16.8 0.5 1.00 5 2.00
7 6 5 19.7 6 145 175 3.62 2.77 15.5 0.0 1.00 5 6.00
8 8 5 15.4 8 326 300 3.88 3.37 14.6 0.0 1.00 5 6.00
5。6。3 reshape2包
reshape2包是一套重构和整合数据集的绝妙的万能工具。
需要首先将数据融合,使每一行都是唯一的标识符-变量组合,然后将数据重铸为你想要的形状。
我们给出原始数据集mydata:
> ID<-c(1,1,2,2)
> Time<-c(1,2,1,2)
> X1<-c(5,3,6,2)
> X2<-c(6,5,1,4)
> mydata<-data.frame(ID,Time,X1,X2)
> mydata
ID Time X1 X2
1 1 1 5 6
2 1 2 3 5
3 2 1 6 1
4 2 2 2 4
1。融合(melt)
数据集的融合是将它重构成这样一种形式:每个测量变量独占一行,行中带有唯一确定这个测量所需要的标识符变量。
> library(reshape2)
> md<-melt(mydata,id=c("ID","Time"))
> md
ID Time variable value
1 1 1 X1 5
2 1 2 X1 3
3 2 1 X1 6
4 2 2 X1 2
5 1 1 X2 6
6 1 2 X2 5
7 2 1 X2 1
8 2 2 X2 4
2。重铸(cast)
dcast()函数读取已融合的数据,并使用你提供的公式和一个(可选的)用于整合数据的函数将其重塑。格式:
newdata<-dcast(md,formula,fun.aggregate)
md是已经融合的数据,formula是描述了想要的结果,fun.aggregate数据整合函数。
执行整合
> dcast(md,ID~variable,sd)
ID X1 X2
1 1 1.414214 0.7071068
2 2 2.828427 2.1213203
> dcast(md,ID~variable,sd)
ID X1 X2
1 1 1.414214 0.7071068
2 2 2.828427 2.1213203
> dcast(md,Time~variable,sd)
Time X1 X2
1 1 0.7071068 3.5355339
2 2 0.7071068 0.7071068
> dcast(md,ID~Time,sd)
ID 1 2
1 1 0.7071068 1.414214
2 2 3.5355339 1.414214
不执行整合
> dcast(md,ID+Time~variable)
ID Time X1 X2
1 1 1 5 6
2 1 2 3 5
3 2 1 6 1
4 2 2 2 4
> dcast(md,ID+variable~Time)
ID variable 1 2
1 1 X1 5 3
2 1 X2 6 5
3 2 X1 6 2
4 2 X2 1 4
> dcast(md,ID~variable+Time)
ID X1_1 X1_2 X2_1 X2_2
1 1 5 3 6 5
2 2 6 2 1 4