上次我们介绍了MSSQL经典问题:现有范围(孤岛)。其根本解决思路就是利用人为创建自然增长的一列,与一个标识列进行一定的计算,得到一个范围列通过GROUP BY进行分组计算。那如果现在有多个标识列,该如何来处理呢?
今天我们要介绍的是组标识列的解决方案,比上次稍微复杂一点,但是根本思路还是一致的,唯一的区别在于(此处先省略很多字)。
先来看下今天的数据结构:
create table zhongyang.dbo.T2
(
id int,
val varchar(1)
);
insert into zhongyang.dbo.T2
(
id,
val
)
values (2,'a'),(3,'a'),(5,'a'),(7,'b'),(11,'b'),(13,'a'),(17,'a'),(19,'a'),(23,'c'),(29,'c'),(31,'a'),(37,'a'),
(41,'a'),(43,'a'),(47,'c'),(53,'c'),(59,'c');
select *
from zhongyang.dbo.T2
order by id;
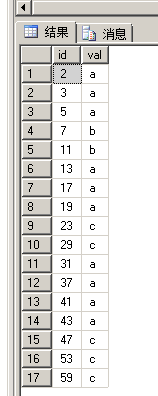
这次有两个标识列:id和val,我们希望根据val列得到id的现有范围,那么该如何处理呢?
也许你会说,给每个标识列都创建一个自然增长列,再分别与标识列计算,那么问题来了,val列存放的是字符型,该怎么和自然增长列进行计算呢?
再好好观察下数据,id列是可以直接参与计算的,val列却不行,那如果我们将这两个列结合起来,创建一个分组列,行不行呢?别光想啦,动手写一下,看看能得到什么结果:
select *,
ROW_NUMBER() over(order by id) as rowindex1,
ROW_NUMBER() over(order by val,id) as rowindex2
from zhongyang.dbo.T2
order by id;
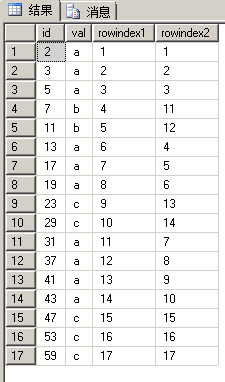
再仔细看下数据,尤其是得到的两个分组列,能发现什么?很显然,不能直接使用这两个分组列进行GROUP BY计算,毫无意义。难道我们思路错了吗?
对啦,如果将这两个标识列进行计算,能得到什么呢?
;with aaa as
(
select *,
ROW_NUMBER() over(order by id) as rowindex1,
ROW_NUMBER() over(order by val,id) as rowindex2
from zhongyang.dbo.T2
)
select *,
rowindex2-rowindex1 as diff
from aaa
order by id;

看看diff列,怎么样,是不是明白了?其实这次介绍的例子,复杂点在于没有办法通过一次计算得到分组列,而是需要针对多个标示列,分别计算出一个中间列,再通过对多个中间列的处理,得到最终的分组列。最后看下结果:
;with aaa as
(
select *,
ROW_NUMBER() over(order by id) as rowindex1,
ROW_NUMBER() over(order by val,id) as rowindex2
from zhongyang.dbo.T2
)
,bbb as
(
select *,
rowindex2-rowindex1 as diff
from aaa
)
select val,
MIN(id) as StartId,
MAX(id) as EndId
from bbb
group by val,diff
order by val,StartId;
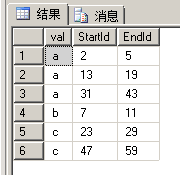
结果终于出来了,不容易吧。其实仔细想想,也不是很难,很多时候的数据需求,不会一次两次就得到结果,而且给出的数据,也往往无法直接使用,需要做多次处理,因此我们最重要的是要先仔细观察数据本身,找出存在的规律。
