readr包用于读取数据。相比于base包,其优势在于速度快,能提速十余倍;相比于data.table包,其速度稍有逊色,作者Hadley大叔表示,差个1.2到2倍速度的样子,但是,在读取过程中能对数据进行更加精细的解析。下面介绍其主要函数。主要参考R for Data Science一书,http://r4ds.had.co.nz/data-import.html#getting-started。
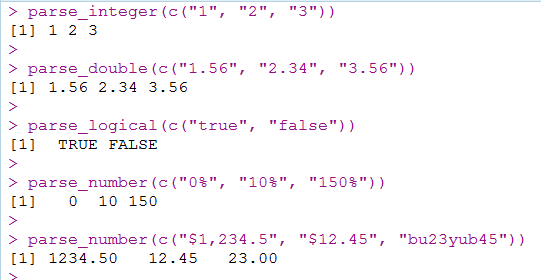
向量解析parse_logical(), parse_integer(), parse_double(), 和parse_character()这几个函数,分别将向量解析到对应的逻辑值、整型、双精度浮点型和字符型。
数字型parse_integer()和parse_double()要求参数必须是完全的数字,不含其它不可转换的字符,而parse_number()函数就更宽泛一些,直接剪除非数字字符。例如"bu23yub45",就只提取23,被隔断的45就被剪除。
parse_integer(c("1", "2", "3"))
parse_double(c("1.56", "2.34", "3.56"))
parse_logical(c("true", "false"))
parse_number(c("0%", "10%", "150%"))
parse_number(c("$1,234.5", "$12.45", "bu23yub45"))
还可以自己设置小数点的标法,比如,用逗号表示小数点。
parse_number("$1.234,56",
locale = locale(decimal_mark = ",", grouping_mark = "."))

字符型tidyverse默认用utf-8进行编码。对于要进行解析的字符串,要先弄清楚原码。例如下两句
x1 <- "El Ni\xf1o was particularly bad this year"
x2 <- "\x82\xb1\x82\xf1\x82\xc9\x82\xbf\x82\xcd"
parse_character(x1, locale = locale(encoding = "Latin1"))
parse_character(x2, locale = locale(encoding = "Shift-JIS"))

对于不知道原编码的字符串,可以先用guess_encoding()函数测试一下,猜的不一定对,聊胜于无,比如x2就猜错了。

因子型这个就比较鸡肋,有更好的包,过几天再写笔记。功能主要就是看给出的向量是否有超出给定因子水平的因子。
fruit <- c("apple", "banana")
parse_factor(c("apple", "banana", "bananana"), levels = fruit)

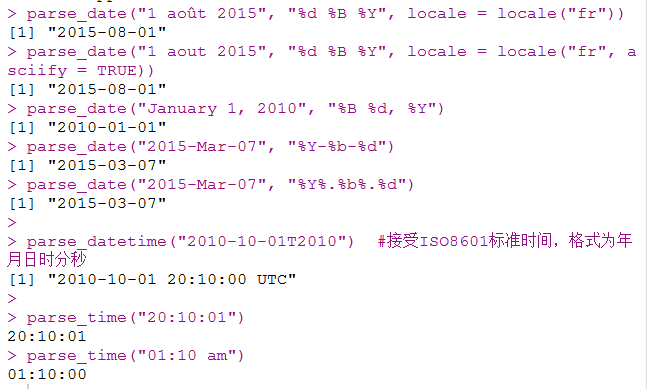
时间型很灵活的时间解析,可以利用locale()函数自行设定解析的方法。前两条命令就设定了法语的月份表达以及字符串的编译为ASCII码。%*表示时间的格式,是format选项的参数,根据要解析的时间进行设置。
parse_date("1 août 2015", "%d %B %Y", locale = locale("fr"))
parse_date("1 aout 2015", "%d %B %Y", locale = locale("fr", asciify = TRUE))
parse_date("January 1, 2010", "%B %d, %Y")
parse_date("2015-Mar-07", "%Y-%b-%d")
parse_date("2015-Mar-07", "%Y%.%b%.%d")
parse_datetime("2010-10-01T2010") #接受ISO8601标准时间,格式为年月日时分秒
parse_time("20:10:01")
parse_time("01:10 am")
文件读写数据读取主要有read_csv(),read_csv2(), read_tsv(), read_delim(), read_fwf(), fwf_positions()等函数。
read_csv("The first line of metadata
#The second line of metadata
srtb
x,y,z
1,2,3", skip = 2, trim_ws = TRUE, comment = "#", quoted_na = TRUE, col_names = c("x", "y", "z"))
read_csv函数以逗号划分列。skip表示要跳过不读的行数,comment表示以此开头的行不读。结果如下。

read_delim("a\tb\n1\t2\t.", delim = "\t", na = ".", col_names = c("x", "y", "z"))
read_delim可以自行设定列的分隔符,在delim选项里设定。na表示将该值视为NA值。结果如下。

国泰安数据读取从国泰安数据库下载了TXT和CSV格式的两个数据文件尝试读入。
吐槽一句,国泰安真是太不友好了,Excel文件还好,TXT和CSV格式直接读取很虐,需要做一些处理。
前方高能。
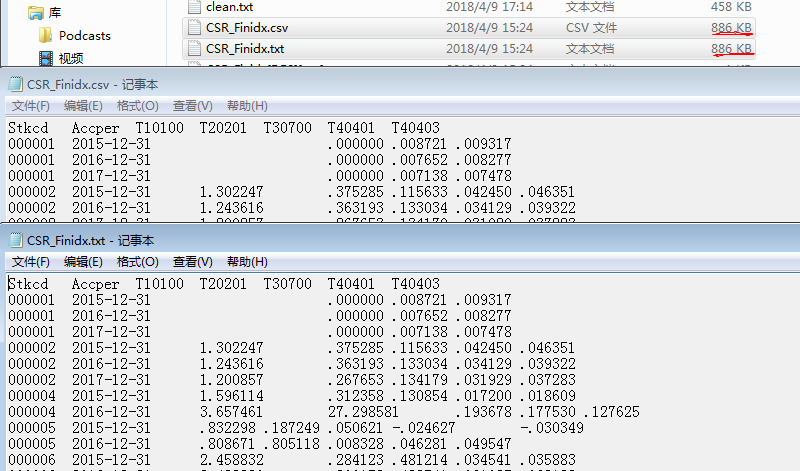
这两个文件的内容是一样的,七个变量,七千多个观测值。以我被数据虐待这么些年的经验来看,这么点数据有886kb的大小很不正常,八成藏着什么吊诡的字符要虐我一下,而且数据间隔很不均匀,一看就不是正经的用制表符或者逗号间隔的文件。
试着读一下。
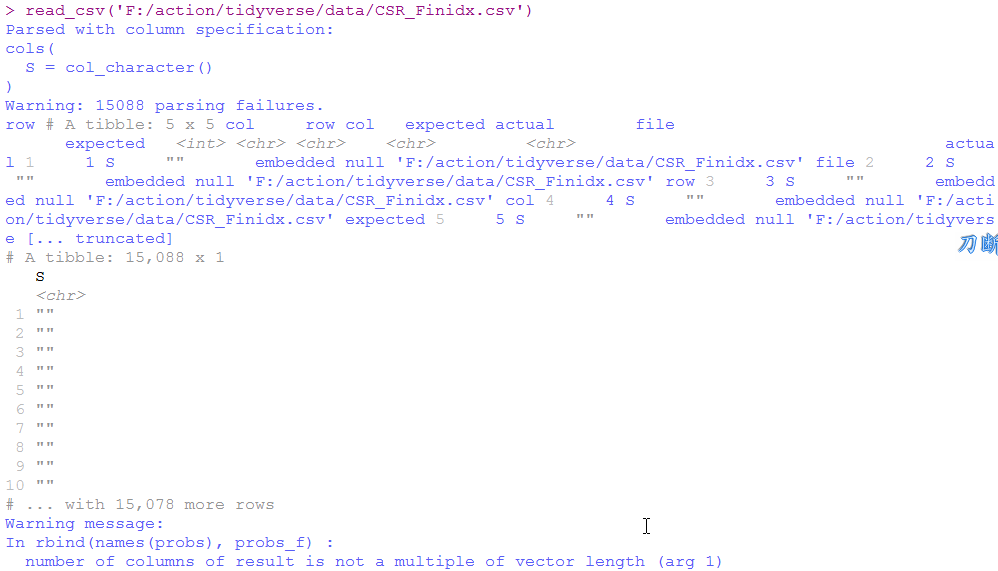
这酸爽,七个变量就读出了一个,还是个空值。
我觉得主要是read_csv这个函数非要用utf-8编码造成的。不然用base包里的read.csv函数来读一下试试。
l1 <- read.csv('F:/action/tidyverse/data/CSR_Finidx.csv', sep = ",", fileEncoding = "UTF-16")
view(l1)
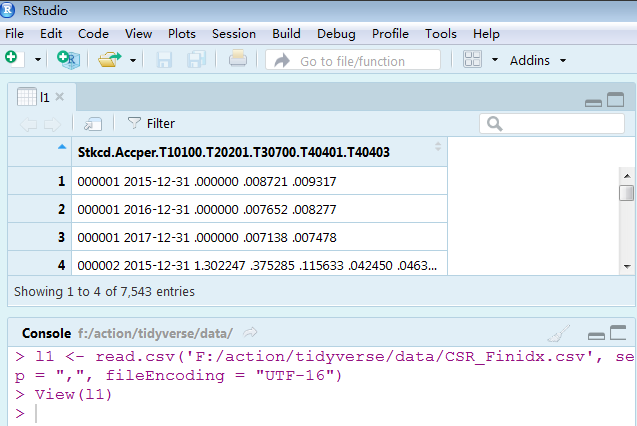
读是读出来了,但是根本不按套路来,七个变量挤成一个,虽然有办法拆开,但还是算是失败了。因为对于几个G的数据来说,base包不行。太弱了,配不上我。
我决定试一下data.table::fread。
library(data.table)
l2 <- fread('F:/action/tidyverse/data/CSR_Finidx.csv')
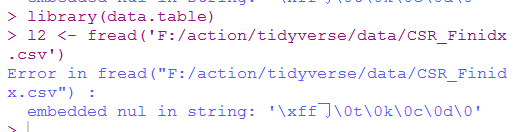
还是失败了。从报错来说,还是编码的问题。看来这个问题是绕不过去了。
手动转码由于是间隔中有空白字符乱码,导致读取混乱,那只好另存为utf-8编码的文件了。
果然是国泰安这个混蛋的锅。
重新保存的数据new只有453kb大小。fread和read_txt两个函数都很顺利地读取了。
R转码stackoverflow上看来的方法。
如果文件很多,懒得手动转码,可以用这个函数搞个遍历就好。
cleanFiles<-function(file,newfile){
writeLines(iconv(readLines(file,skipNul = TRUE)),newfile)
}
cleanFiles('CSR_Finidx.csv','clean.csv')
很方便。但是有一个缺点,新生成的文件不再包含原有的第一行,即变量名,那行被转码成了NA。而且分隔符被强行改成了制表符。明明是个CSV文件啊。
l <- read_delim('F:/action/tidyverse/data/clean.csv', col_names = paste('v', 1:7), delim = '\t')
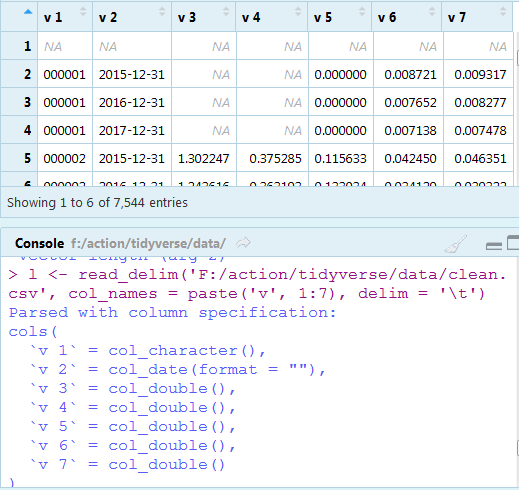
除此之外,效果还不错,会计年度变量自动解析成了日期型。
我果然是被虐傻了OTZ
凑合用吧,还能离咋地。




