之前为了大家可以将收集的数据便于分析,建议大家使用csv这种表样式数据格式进行保存。但是咱们爬数据时,除了一些数值类,大部分数据是文本,如何操作csv每一行中的文本数据呢?
例如我有 局座哭了.csv,我们如何对comment列进行数据清理,只保留中文。
操作数据时,如何保持原来的数据结构(比如分词处理后,csv文件除了加了一列新的分词记录外,原来的数据是否保留,能否一一对应)?
思路:
1、用pandas库读入csv文件为dataframe
2、将dataframe转化为python对象
3、写一个处理函数(如数据操作函数,如分词)
4、在此调用处理函数,得到新数据
5、将原csv数据和新数据写入新csv
一、读入csv文件
首先要将csv文件查看下,整理成utf-8编码形式
然后使用pandas库的read_csv()方法,直接看案例学习吧
import pandas as pd
path = r'C:\Users\thunderhit\Desktop\局座哭了.csv'
f = open(path,'r',encoding='utf-8') #mac不用这行,直接pd.read_csv(path)
data = pd.read_csv(f)
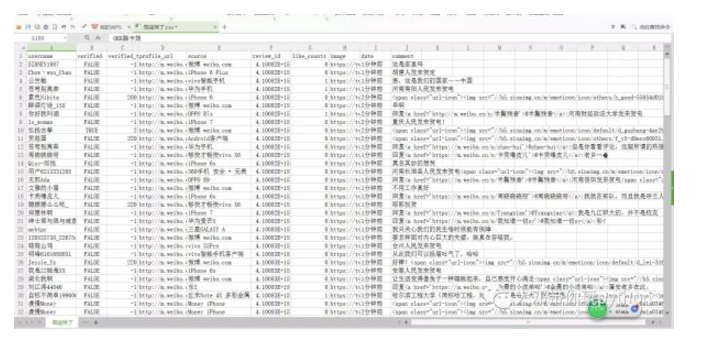
data
#了解数据的概况,如count为记录数(即131行)
data.describe()
verified_typereview_idlike_countscount131.0000001.310000e+02131.000000mean19.1679394.100877e+150.129771std63.5119804.155520e+100.337341min-1.0000004.100820e+150.00000025%-1.0000004.100830e+150.00000050%-1.0000004.100890e+150.00000075%-1.0000004.100910e+150.000000max220.0000004.100930e+151.000000
二、将dataframe转化为python对象
我们看到 局座哭了.csv 有131行数据。
能不能循环的方式,把每行遍历出来?
能不能再对每行的每个元素进行抽取,比如抽取出每行中的comment
2.1 遍历dataframe中的每一行
首先我们要有知道行数,data.describe()告诉我们有131行
那任意的csv文件有多少行(record_num行数),我们必须自动化的知道
record_num = df.describe().ix[0,0]
record_num = int(data.describe().ix[0,0])
record_num
131
2.2 遍历每行出来
比如我要看第一行的所有列的数据
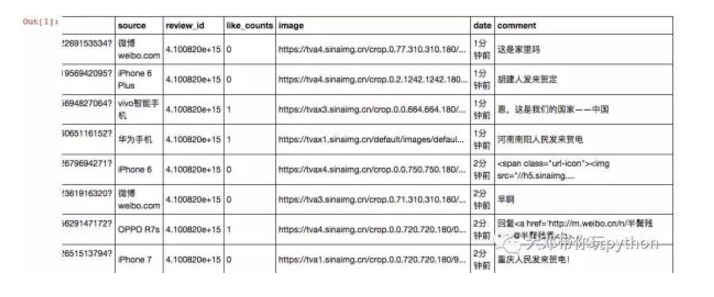
data.ix[0,:]
username SIDNEY1987
verified False
verified_type -1
profile_url http://m.weibo.cn/u/2269153534?uid=2269153534&...
source 微博 weibo.com
review_id 4.10082e+15
like_counts 0
image https://tva4.sinaimg.cn/crop.0.77.310.310.180/...
date 1分钟前
comment 这是家里吗
Name: 0, dtype: object
#遍历出所有行
for i in range(record_num):
record = data.ix[i,:]
print(record)
username SIDNEY1987
verified False
verified_type -1
profile_url http://m.weibo.cn/u/2269153534?uid=2269153534&...
source 微博 weibo.com
review_id 4.10082e+15
like_counts 0
image https://tva4.sinaimg.cn/crop.0.77.310.310.180/...
date 1分钟前
comment 这是家里吗
Name: 0, dtype: object
username Chow丶won_Chan
verified False
verified_type -1
profile_url http://m.weibo.cn/u/1956942095?uid=1956942095&...
source iPhone 6 Plus
review_id 4.10082e+15
like_counts 0
image https://tva4.sinaimg.cn/crop.0.2.1242.1242.180...
date 1分钟前
comment 胡建人发来贺定
Name: 1, dtype: object
username 公竺敏
verified False
verified_type -1
profile_url http://m.weibo.cn/u/5694827064?uid=5694827064&...
source vivo智能手机
review_id 4.10082e+15
like_counts 1
image https://tvax3.sinaimg.cn/crop.0.0.664.664.180/...
date 1分钟前
comment 恩,这是我们的国家――中国
Name: 2, dtype: object
username 苍穹别离曲
verified False
verified_type -1
profile_url http://m.weibo.cn/u/6065116152?uid=6065116152&...
source 华为手机
review_id 4.10082e+15
like_counts 1
image https://tvax1.sinaimg.cn/default/images/defaul...
date 1分钟前
comment 河南南阳人民发来贺电
。。。。。。
2.3 对每一行中的某列进行操作
比如提取出第1行中的comment
record1 = data.ix[0,:]
record1['comment']
'这是家里吗'
#遍历出所有行的comment
for i in range(record_num):
record = data.ix[i,:]
comment = record['comment']
print(comment)
这是家里吗
胡建人发来贺定
恩,这是我们的国家――中国
河南南阳人民发来贺电
回复<a href='http://m.weibo.cn/n/半鬓残香'>@半鬓残香</a>:河南财经政法大学发来贺电
重庆人民发来贺电!
好棒!<span class="url-icon"><img src="//h5.sinaimg.cn/m/emoticon/icon/default/d_lei-316a1a3ed5.png" style="width:1em;height:1em;;"></span>
安徽人民发来贺电
让生活变得像兔子一样蹦跳起来,自己感觉开心满足<span class="url-icon"><img src="//h5.sinaimg.cn/m/emoticon/icon/default/d_xixi-ce63ce2629.png" style="width:1em;height:1em;;"></span><span class="url-icon"><img
[加油]
回复<a href='https://m.weibo.cn/n/诗词苑'>@诗词苑</a>:好骄傲
为什么显示已删除?!
谁给我普及一下?倒底是第二艘还是首艘?怎么有的报第二膄、有的报首艘
骄傲!!!<span class="url-icon"><img
皮皮虾号,我们走,想去哪就去哪
<span class="url-icon"><img src="//h5.sinaimg.cn/m/emoticon/icon/others/l_xin-8e9a1a0346.png" style="width:1em;height:1em;;"></span>用力抽插<span class="url-icon">src="//h5.sinaimg.cn/m/emoticon/icon/others/l_xin-8e9a1a0346.png" style="width:1em;height:1em;;"></span>用力抽插<span class="url-icon">
回复<a href='https://m.weibo.cn/n/李诚是我'>@李诚是我</a>:去过你们学校招聘,食堂饭菜挺好吃,以前叫九江船校,也是中船系统内的
大中国威武!
我们的征途是星辰大海
回复<a href='https://m.weibo.cn/n/oolongtea凤凰乌龙茶人'>@oolongtea凤凰乌龙茶人</a>:是的没毛病
<a href='https://m.weibo.cn/n/端木芸姍'>@端木芸姍</a> 艾特一个台独狗 兄弟们送我上去
大连造!!!
如果你认识重庆北碚一姐刘珍羽的话,请告诉她 ,我爱她 ,如果这条评论被淹没就当我是傻瓜
厉害了。我的国。
直播为什么删了啊
三、写一个处理函数
如数据操作函数,如只保留中文数据
import re
def Chinese(text):
cleaned = re.findall(r'[\u4e00-\u9fa5]+', text) #返回列表
cleaned = ''.join(cleaned) #拼接成字符串
return cleaned
commentt = '>@半鬓残香</a>:河南信阳发来贺电<span class="url-icon">'
Chinese(commentt)
'半鬓残香河南信阳发来贺电'
四、在此调用处理函数,得到新数据
#在循环中调用函数,对每行的comment操作,只保留中文字符
for i in range(record_num):
record = data.ix[i,:]
comment = record['comment']
cleaned = Chinese(comment)
print(cleaned)
这是家里吗
胡建人发来贺定
恩这是我们的国家中国
河南南阳人民发来贺电
早啊
回复半鬓残香半鬓残香河南财经政法大学发来贺电
重庆人民发来贺电
回复但是你看看评论远超所谓的热搜
回复卡秃噜皮儿卡秃噜皮儿老乡
莫名其妙的想哭
河南长垣县人民发来贺电
回复半鬓残香半鬓残香河南信阳发来贺电
不用工作真好
回复周晓晓晓呀周晓晓晓呀我就在部队而且我是呼兰人
耶耶祝贺
回复我是九江职大的并不是校友
淹没就当我是傻瓜
厉害了我的国
直播为什么删了啊
。。。。。。
五、将原csv数据和新数据写入新csv
import csv
#建新csv文件
path = r'C:\Users\thunderhit\Desktop\新csv文件.csv'
csvfile = open(path,'w',encoding='utf-8')
writer = csv.writer(csvfile)
writer.writerow(('username','verified','verified_type','profile_url','source','review_id','like_counts','image','date','comment'))
for i in range(record_num):
record = data.ix[i,:]
comment = record['comment']
comment = Chinese(comment)
writer.writerow((record['username'],record['verified'],record['verified_type'],record['profile_url'],
record['source'],record['review_id'],record['like_counts'],record['image'],record['date'],comment))
csvfile.close()
检查一下
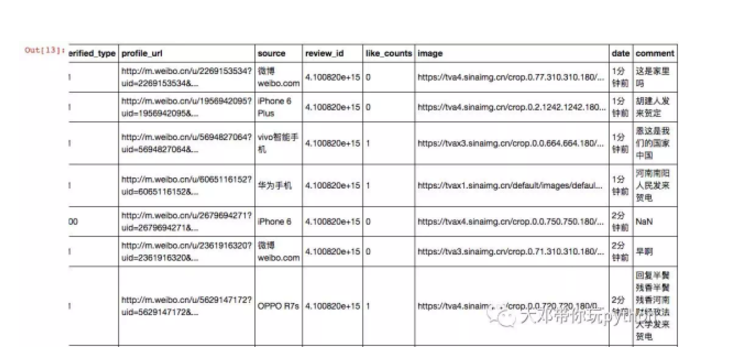
我们检查下新的csv文件,是否如我们意
comment列是否已经清理,只保留中文
path = r'C:\Users\thunderhit\Desktop\新csv文件.csv'
f = open(path,'r',encoding='utf-8') #mac不用这行,直接pd.read_csv(path)
pd.read_csv(f)
更多内容
文本分析
python居然有情感??真的吗??
文本分析之网络关系
中文分词-jieba库知识大全自然语言处理库之snowNLP用gensim库做文本相似性分析基于共现发现人物关系的python实现
用python计算两文档相似度
数据分析
酷炫的matplotlib
文本分析之网络关系
pandas库读取csv文件用词云图解读“于欢案”
神奇的python
初识Python的GUI编程Python实现文字转语音功能怜香惜玉,我用python帮助办公室文秘
逆天的量化交易分析库-tushare
开扒皮自己微信的秘密
8行代码实现微信聊天机器人
使用Python登录QQ邮箱发送QQ邮件
爬虫
爬虫实战视频专辑抓取单博主的所有微博及其评论【视频】手把手教你抓美女~
当爬虫遭遇验证码,怎么办【视频】于欢案之网民的意见(1)?【视频】有了selenium,小白也可以自豪的说:“去TMD的抓包、cookie”
【视频】快来get新技能--抓包+cookie,爬微博不再是梦
【视频教程】用python批量抓取简书用户信息
爬豆瓣电影名的小案例(附视频操作)
爬豆瓣电影名的小案例2(附视频操作)用Python抓取百度地图里的店名,地址和联系方式

