华为贴吧爬虫
import urllib.request
from bs4 import BeautifulSoup
import csv
import time
import random
start_time = time.time()
csvFile = open(r"E:\Python\Projects\贴吧\华为\huawei.csv",'a+',newline='')
writer = csv.writer(csvFile)writer.writerow(('posting_num','posting_title','posting_coments_num','posting_user_link','posting_user_name'))
base_url = 'http://tieba.baidu.com/f?kw=%E5%8D%8E%E4%B8%BA&ie=utf-8&pn='
posting_num = 1
for page in range(0,6942):
time_delay = random.randint(1, 3)
url = base_url + str(page * 50)
html = urllib.request.urlopen(url)
bsObj = BeautifulSoup(html,'lxml')
posting_list = bsObj.find_all('div',{'class':'t_con cleafix'})
print('============================')
print('正在抓取华为贴吧第%d页' % page) now_time = time.time()
has_spent_seconds = now_time - start_time
has_spent_time_int = int((now_time - start_time) / 60)
print('华为号小爬虫已耗时%d分钟' % has_spent_time_int)
if page > 1:
will_need_time = ((6940 * has_spent_seconds) / page)/60
will_need_time = int(will_need_time)
print('华为号小爬虫还要爬%d分钟'%will_need_time)
for posting in posting_list:
try:
posting_coments_num = posting.contents[1].span.contents[0]
posting_user_name = posting.contents[3].span.contents[1].a.contents[0]
posting_user_link = 'http://tieba.baidu.com' + posting.contents[3].span.contents[1].a.attrs['href']
posting_title = posting.contents[3].contents[1].contents[1].a.attrs['title']
posting_num = posting_num + 1
writer.writerow((posting_num, posting_title, posting_coments_num, posting_user_link, posting_user_name))
except:
continue
time.sleep(time_delay)
if page in list(range(1,6940,10)):
time.sleep(3)
csvFile.close()
end_time = time.time()
duration_time = int((end_time - start_time)/60)
print('程序运行了%d分钟'%duration_time)
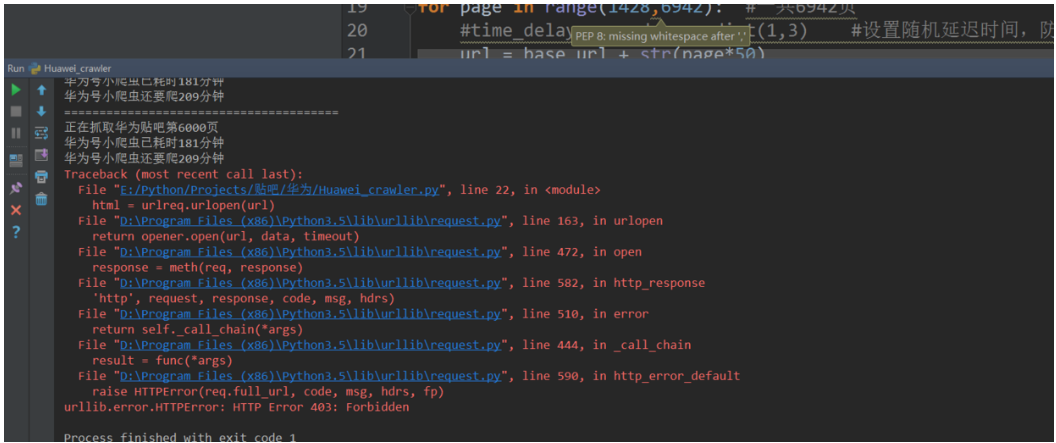
程序爬了6000页就被百度封掉,你们回去可以改下贴吧的,比如爬小米吧或者其他娱乐的吧,将页面数改成小于6000的,应该不会被封掉。按照我写的代码,我爬6000页用了180分钟。结果如图,403forbiden,被百度封掉了。