Python网络爬虫之『美味的汤』
1.载入库函数
from bs4 import BeautifulSoup
from collections import Counter
from time import sleep
import requests
import re
2.测试
# 豆瓣top250首页
url = "https://movie.douban.com/top250"
# 解析网页
soup = BeautifulSoup(requests.get(url).text,"lxml")
# 提取链接
## 先看看链接的个数
items = soup('div','item')
print len(items)
25
## 提取链接
links = []
for item in items:
links.append(item.find('div','hd').a.get('href'))
print links[1]
https://movie.douban.com/subject/1295644/
## 访问某一个链接,提取一些有用信息
page1 = BeautifulSoup(requests.get(links[0]).text,"lxml")
### 电影名称
title = page1.find('span',attrs = {'property':'v:itemreviewed'}).text
### 发行时间
year = page1.find('span',attrs = {'class':'year'}).text
year = re.sub(r"[()]","",year)
###评分
rating_num = page1.find('strong',attrs = {'class':'ll rating_num'}).text
### 评论数
votes = page1.find('span',attrs = {'property':'v:votes'}).text
### 类型
types_node = page1.findAll('span',attrs = {'property':'v:genre'})
types = [node.text for node in types_node ]
### 打印
print title,year,rating_num,votes,types[0],types[1]
##其他信息
info = page1.find('div',attrs = {'id':'info'}).text
print info
type(info)
### 国家
#country = re.match("制片国家/地区:",info)
#print country
肖申克的救赎 The Shawshank Redemption 1994 9.6 682843 剧情 犯罪
导演: 弗兰克·德拉邦特
编剧: 弗兰克·德拉邦特 / 斯蒂芬·金
主演: 蒂姆·罗宾斯 / 摩根·弗里曼 / 鲍勃·冈顿 / 威廉姆·赛德勒 / 克兰西·布朗 / 吉尔·贝罗斯 / 马克·罗斯顿 / 詹姆斯·惠特摩 / 杰弗里·德曼 / 拉里·布兰登伯格 / 尼尔·吉恩托利 / 布赖恩·利比 / 大卫·普罗瓦尔 / 约瑟夫·劳格诺 / 祖德·塞克利拉
类型: 剧情 / 犯罪
制片国家/地区: 美国
语言: 英语
上映日期: 1994-09-10(多伦多电影节) / 1994-10-14(美国)
片长: 142 分钟
又名: 月黑高飞(港) / 刺激1995(台) / 地狱诺言 / 铁窗岁月 / 消香克的救赎
IMDb链接: tt0111161
unicode
2.定义函数
获取所有的入选电影页面链接
# 获得进入每部电影相应的页面链接
def get_link(soup_page):
items = soup('div','item')
## 提取链接
links = []
for item in items:
links.append(item.find('div','hd').a.get('href'))
return links
### 进入每个链接,提取需要的信息
def get_movie_info(link):
page1 = BeautifulSoup(requests.get(link).text,"lxml")
### 电影名称
title = page1.find('span',attrs = {'property':'v:itemreviewed'}).text
### 发行时间
year = page1.find('span',attrs = {'class':'year'}).text
year = re.sub(r"[()]","",year)
###评分
rating_num = page1.find('strong',attrs = {'class':'ll rating_num'}).text
### 评论数
votes = page1.find('span',attrs = {'property':'v:votes'}).text
#### 类型
#types_node = page1.findAll('span',attrs = {'property':'v:genre'})
#types = [node.text for node in types_node ]
##其他信息
info = page1.find('div',attrs = {'id':'info'}).text
return {
"title":title,
"year":year,
"rating_num":rating_num,
"votes":votes,
"info":info
}
进入每部影片的介绍页面提取信息
base_url = "https://movie.douban.com/top250"
links = []
Max_Page = 10
rank = 0
for page in range(1,Max_Page +1):
print "Processing Page ",page,".Please wait..."
CurrentUrl = base_url+ u'?start=' +unicode((page-1)*25)+u'&filter='
CurrentSoup = BeautifulSoup(requests.get(CurrentUrl).text,"lxml")
links.append(get_link(CurrentSoup))
sleep(30)
print links[249]
### 获得所有影片信息
movies = []
rate = 1
for i in range(0,10):
for j in range(0,25):
try:
print "Getting information of the",rate,"-th movie."
movies.append(get_movie_info(links[i][j]))
sleep(5)
except Exception,e:
print e
rate+=1
保存数据
from os import getcwd
getcwd()
import pickle
from os import makedirs
from os.path import exists
def save_obj(obj, name ):
if not exists('obj/'):
makedirs('obj/')
with open('obj/'+ name + '.pkl', 'wb') as f:
pickle.dump(obj, f, pickle.HIGHEST_PROTOCOL)
def load_obj(name ):
with open('obj/' + name + '.pkl', 'rb') as f:
return pickle.load(f)
# save links,movies
#save_obj(links,"links")
#save_obj(movies,"movies")
movies = load_obj("movies")
movies[239]
{'info': u'\n\u5bfc\u6f14: \u5a01\u5ec9\xb7\u60e0\u52d2\n\u7f16\u5267: \u8fbe\u5c14\u987f\xb7\u7279\u6717\u52c3 / \u4f0a\u5b89\xb7\u9ea6\u514b\u83b1\u4f26\xb7\u4ea8\u7279 / \u7ea6\u7ff0\xb7\u6234\u987f\n\u4e3b\u6f14: \u5965\u9edb\u4e3d\xb7\u8d6b\u672c / \u683c\u5229\u9ad8\u91cc\xb7\u6d3e\u514b / \u57c3\u8fea\xb7\u827e\u4f2f\u7279 / \u54c8\u7279\u5229\xb7\u9c8d\u5c14 / \u54c8\u8003\u7279\xb7\u5a01\u5ec9\u59c6\u65af\n\u7c7b\u578b: \u5267\u60c5 / \u559c\u5267 / \u7231\u60c5\n\u5236\u7247\u56fd\u5bb6/\u5730\u533a: \u7f8e\u56fd\n\u8bed\u8a00: \u82f1\u8bed / \u610f\u5927\u5229\u8bed / \u5fb7\u8bed\n\u4e0a\u6620\u65e5\u671f: 1953-09-02(\u7f8e\u56fd)\n\u7247\u957f: 118 \u5206\u949f\n\u53c8\u540d: \u91d1\u679d\u7389\u53f6(\u6e2f) / \u7f57\u9a6c\u5047\u671f(\u53f0)\nIMDb\u94fe\u63a5: tt0046250\n',
'rating_num': u'8.9',
'title': u'\u7f57\u9a6c\u5047\u65e5 Roman Holiday',
'votes': u'317177',
'year': u'1953'}
## 对发行年份进行汇总计算
def get_year(movie):
return int(movie["year"])
##
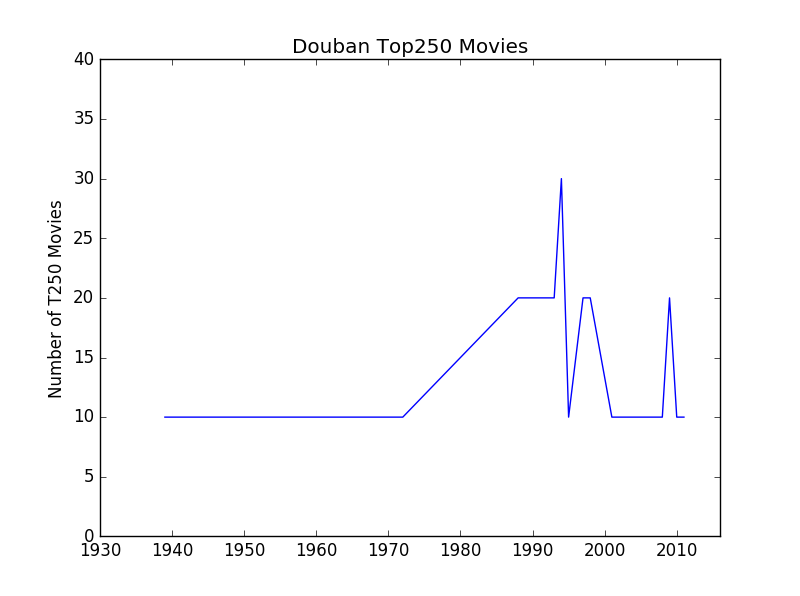
year_counts = Counter(get_year(movie) for movie in movies)
# 画图
import matplotlib.pyplot as plt
years = sorted(year_counts)
movie_counts = [year_counts[year] for year in years]
plt.plot(years,movie_counts)
plt.ylim([0, 40])
plt.xlim([1930,2016])
plt.ylabel("Number of T250 Movies")
plt.title("Douban Top250 Movies")
plt.show()
参考文献
- 『Data Science from Scratch』
