学习Python不到一个月,虽然学的很渣,但是还是想通过这种途径分享自己的学习心得,毕竟当初学习R语言也是这么走过来的。
今天是R语言与Python综合系列的第一篇,就聊一聊两者在常用字符串输出上的差异。
为了方便统一案例图片的风格,今天统一在jupyter编辑器中编辑(R和Python)。
通常在R语言中我们使用最多的关于字符串输出函数是paste和paste0。
这两着之间的差别非常微小,如同其字面意思一样,前者可以自定义字符串间隔符号,后者则默认没有间隔符号。
paste和paste0都可以完成单个向量字符串的连接以及两个向量间的匹配。
#生成10个随机大写字母作为案例:
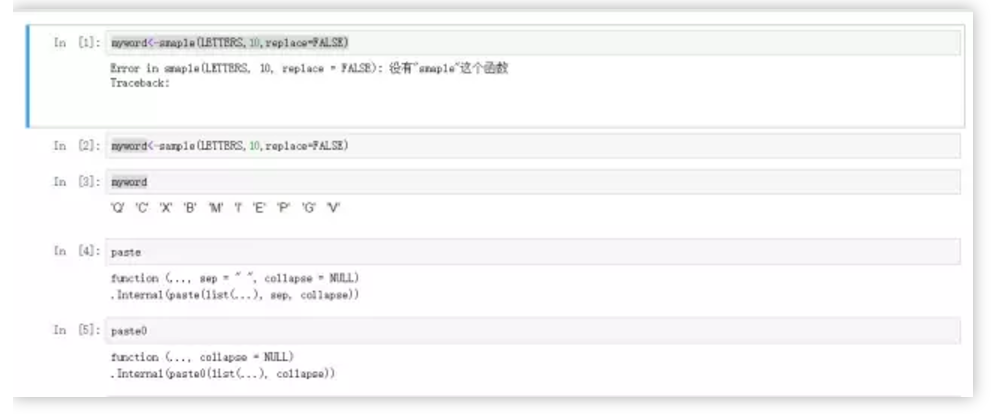
myword<-sample(LETTERS,10,replace=FALSE)
我们可以打印出两个函数的详细参数表:
paste
function (..., sep = " ", collapse = NULL) #sep参数默认间隔为空格
.Internal(paste(list(...), sep, collapse))
paste0
function (..., collapse = NULL) #sep没有间隔参数(无间隔)
.Internal(paste0(list(...), collapse))
单个向量的连接成字符串:
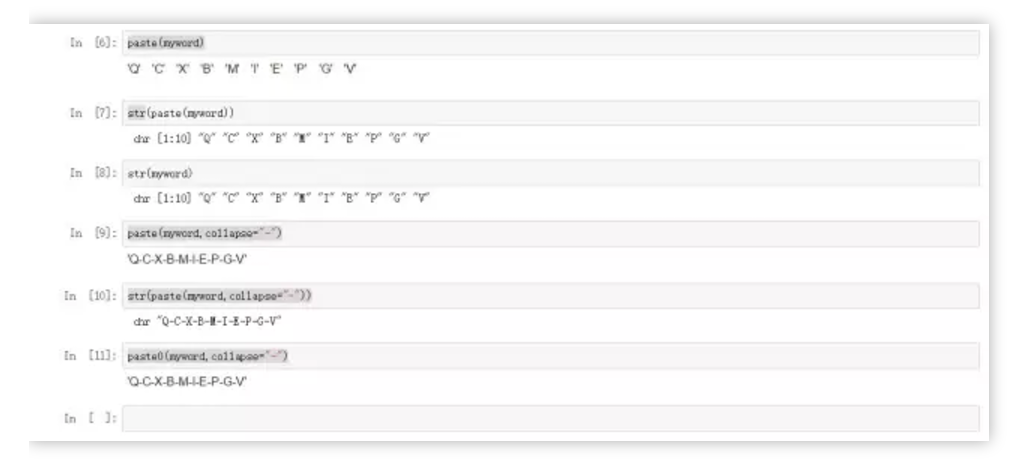
paste(myword,collapse="-")
'Q-C-X-B-M-I-E-P-G-V'
在拼接单个向量之时,通过设置collapse参数来控制字符之间的间隔符,最终输出一个单值字符串。
paste0(myword,collapse="-")
'Q-C-X-B-M-I-E-P-G-V'
我们可以看到,在拼接单个向量为字符串的过程中,paste和paste0两个函数并无太大区别,因为不涉及匹配参数sep。
通常情况下,我们使用paste和paste0做向量间的匹配情况比较多,这种情况多见于遍历网页,遍历日期等。
比如假如我们们要遍历一个网页的网址如下:
随机打开了网易云课堂的一个课程栏目,看到一共有22页课程,此时最简单的遍历网页方法就是通过paste或者paste0。
http://study.163.com/category/400000000146050#/
url<-"http://study.163.com/category/400000000146050#/?p="
num<-1:22
myurl<-paste(url,num,sep="");myurl
myurl<-paste0(url,num);myurl
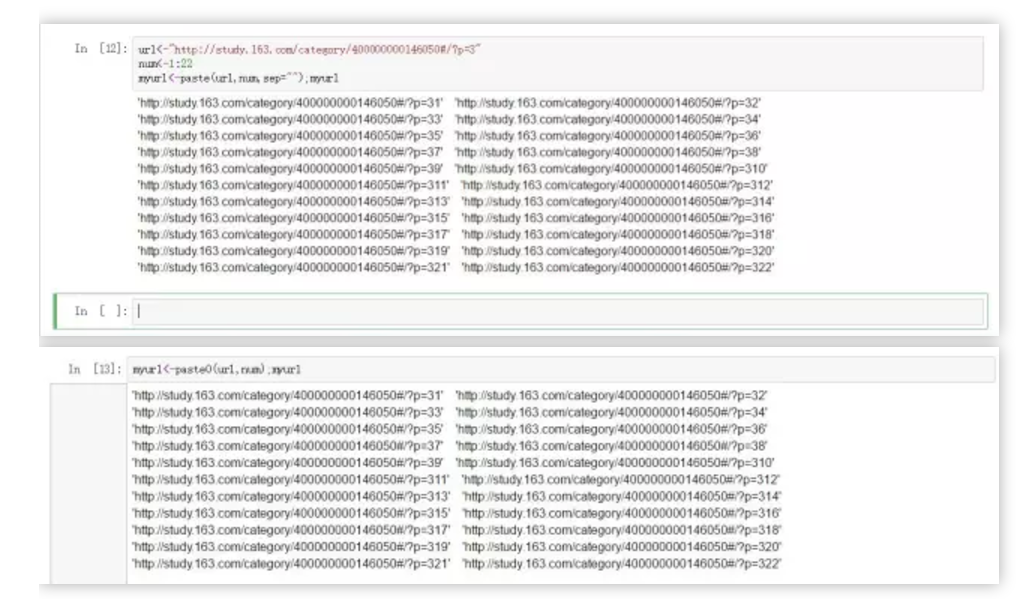
对比两个函数的用法,大家应该能领会其中的差别了吧,paste0把paste的sep参数简化了,直接强制设定为无间隔,此时做向量间匹配的话,paste0函数就可以不用设置sep参数,而paste则需设置,当然虽然在遍历网页时确实节省代码,但也不是任何场合都是如此。
比如我要拼接时间与日期,而且要求以“-”间隔,此时你还是需要使用传统的paste函数来完成这个任务,因为paste0已经不存在sep参数了。
mydate<-paste(2001:2005,"06",sep="-");mydate
还有一个stringr包中字符串拼接函数str_sub()也可以高效的完成上述工作,但是因为需要额外加载包,所以平时我用的频率不高。
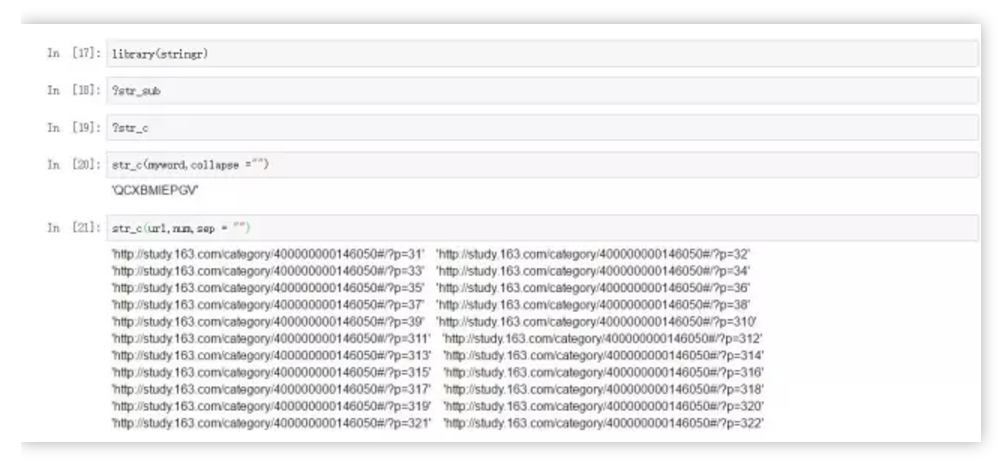
library(stringr)
str_c(myword,collapse ="")
str_c(url,num,sep = "")
在R语言中,字符串格式化输出除了以上常见操作之外,还有一些非常重要的需求,比如格式化输出百分比,格式化输出日期时间等。
以百分比为例:
我们可以通过一些扩展包内提供的百分比构造函数来高效的完成百分比构造过程。
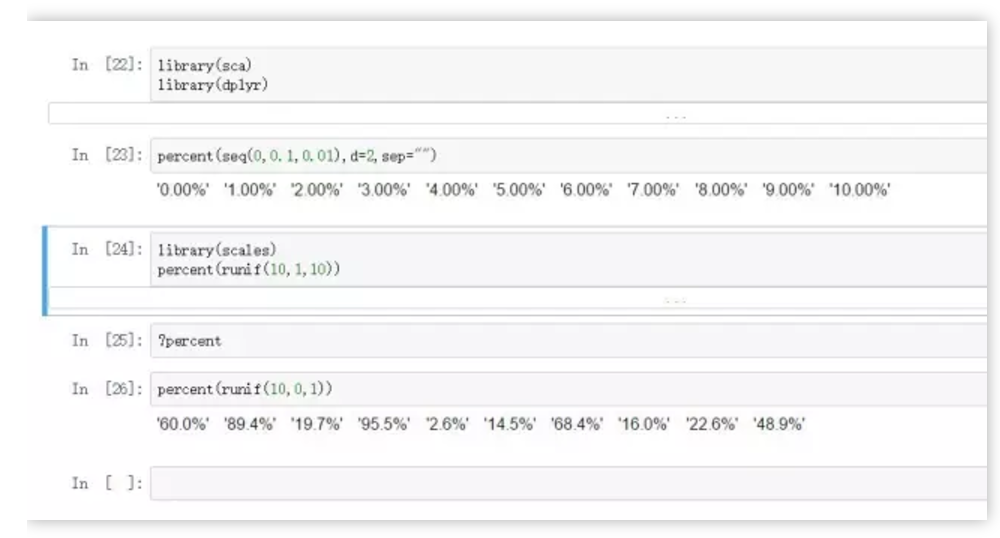
library(sca)
library(dplyr)
percent(seq(0,0.1,0.01),d=2,sep="") #其中的参数控制百分比输出的小数点后位数。
library(scales)
percent(runif(10,0,1)) #percent函数说明了目前没法看到如何控制小数点显式位数。
接下来跟大家介绍一个重量级的函数——sprintf。此函数据说来头不小。(据说继承自C/C++),该函数的使用可以大大简化字符串格式化输出的操作流程。
%d 整数 d d代表整数;2代表长度;0代表不足长度用0补齐
%f 浮点数 %4.2f 第一个数字代表总位数;第二个数字代表小数点位数
%s 字符串
%% 百分比
该函数的参数远不止这三个,太多我也记不住,而且平时使用频率最高的也就这三个,所以秉着投入回报率最高的原则,建议大家用什么记什么。
所以以上百分比过程便只剩下这么几个代码:
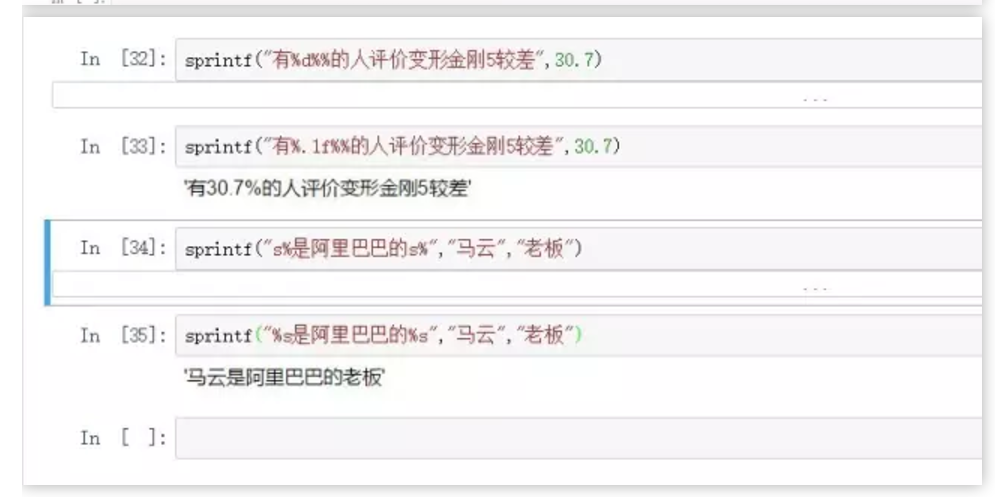
sprintf("%d%%",1:10) #遍历百分比
sprintf("%d-%d-d",2001,12,1:30) #遍历日期:
sprintf("有%.1f%%的人评价变形金刚5较差",30.7)
'有30.7%的人评价变形金刚5较差'
sprintf("%s是阿里巴巴的%s","马云","老板")
'马云是阿里巴巴的老板'

当然,以上过程完全可以通过paste和str_c函数完成,只是sprintf函数来写这些东西看起来更优化,更有逼格。
好了重于轮到Python了,对于一个小菜鸟来说,第一次写Pyhon的教程心情很忐忑,注意了下面要换编辑器了(虽然仍然使用的jupter里)。
Pyhton:
Pyhton中的字符串格式化输出大概有两套比较完善的系统(我所知的)。
其实第一套系统应该也是源于C/C++(感觉跟R里面的格式化符号规则是一致的)
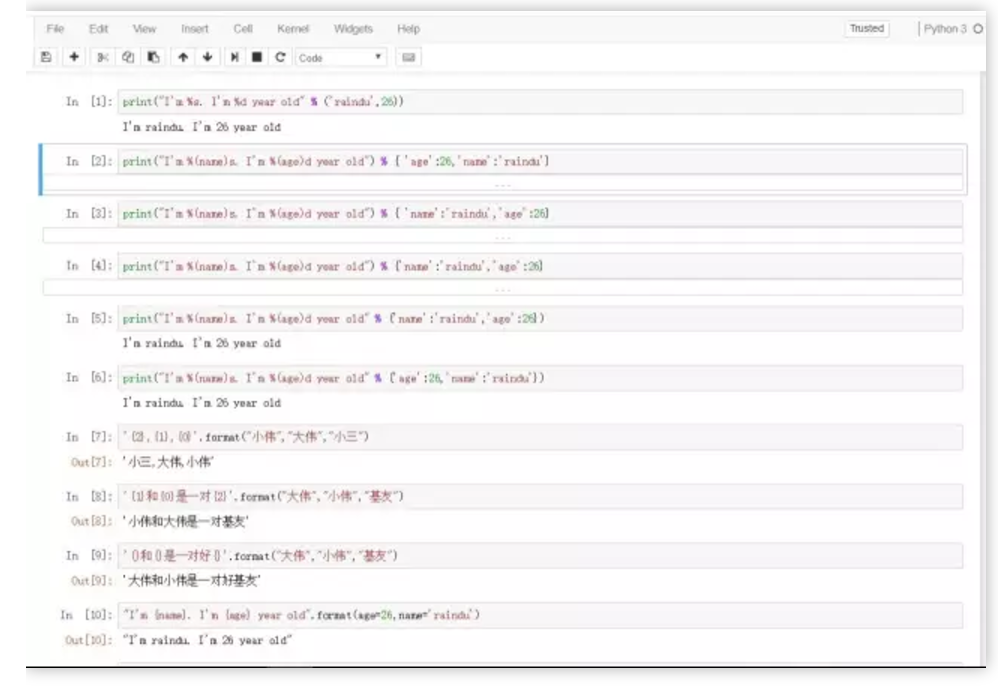
print("I'm %s. I'm %d year old" % ('raindu',26))
以上使用print函数输出了宝宝的大名和芳龄~_~,python中的字符串格式符规则是,在要输出的主句中对应位置插入格式符,在句尾之后使用 % 连接一个元组,元组内提供主句所有的待格式化的字符串,有几个需要格式化的字符串就需要在元组中提供几个字符串对象,而且顺序一定要与待格式化的字符串在主句的位置一一对应。
另一种方式可以使用字典进行字符传递。
print("I'm %(name)s. I'm %(age)d year old" % {'age':26,'name':'raindu'})
这种方式最大的好处就是,以命名参数的形式传入,这样可以不用考虑字典内的键值对顺序。(因为有名字可以索引)
Python中的字符串格式化符号相对于R规定的更加严格、细致,上述所述R中的字符串:%s、数值%d、浮点型%f是通用的。
除此之外,格式化符号内部还可以提供更为详尽的格式控制。
%[(name)][flags][width].[precision]typecode
(name)为名称
flags可以有+,-,' '或0。+表示右对齐。-表示左对齐。' '为一个空格,表示在正数的左侧填充一个空格,从而与负数对齐。0表示使用0填充。
width表示显示宽度
precision表示小数点后精度
但是发现网上关于Python教程中,使用最多的还是.format这种字符串输出形式。
format 函数:
'{2},{1},{0}'.format("小伟","大伟","小三")
'小三,大伟,小伟'
'{1}和{0}是一对{2}'.format("大伟","小伟","基友")
'小伟和大伟是一对基友'
这种传参的方式可以看做是位置参数(顺序),即在要输出的主句中插入末尾提供的对应字符串位置,即可完成格式化过程。
如果你不想在主句对应的花括号内写位置参数,你必须保证末尾提供的字符串顺序与主句对应要插入的位置保持一致。
'{}和{}是一对好{}'.format("大伟","小伟","基友")
当然,你也可以在format括号内内对字符串进行命名,然后将对应名字传入主句对应花括号内部。
"I'm {name}. I'm {age} year old".format(age=26,name='raindu')
这种情况下你也不必考虑format括号内的字符串对应顺序,因为所有的字符串都有名称,只传入名称,函数即可自动完成索引配对。
使用以上两种方式都可以方便的遍历网页:
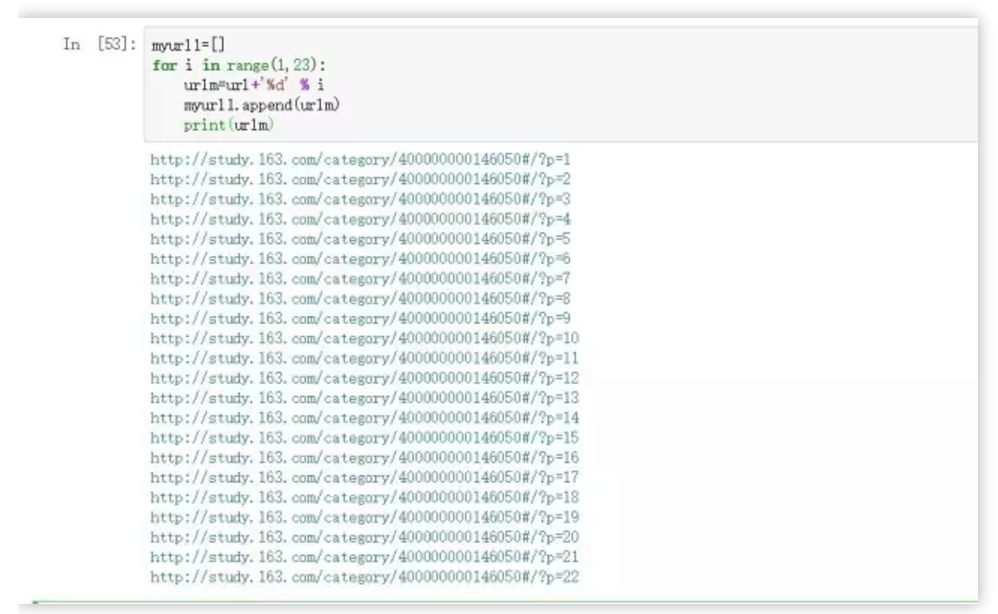
url="http://study.163.com/category/400000000146050#/?p="
myurl1=[]
for i in range(1,23):
urlm=url+'%d' % i
myurl1.append(urlm)
print(urlm)
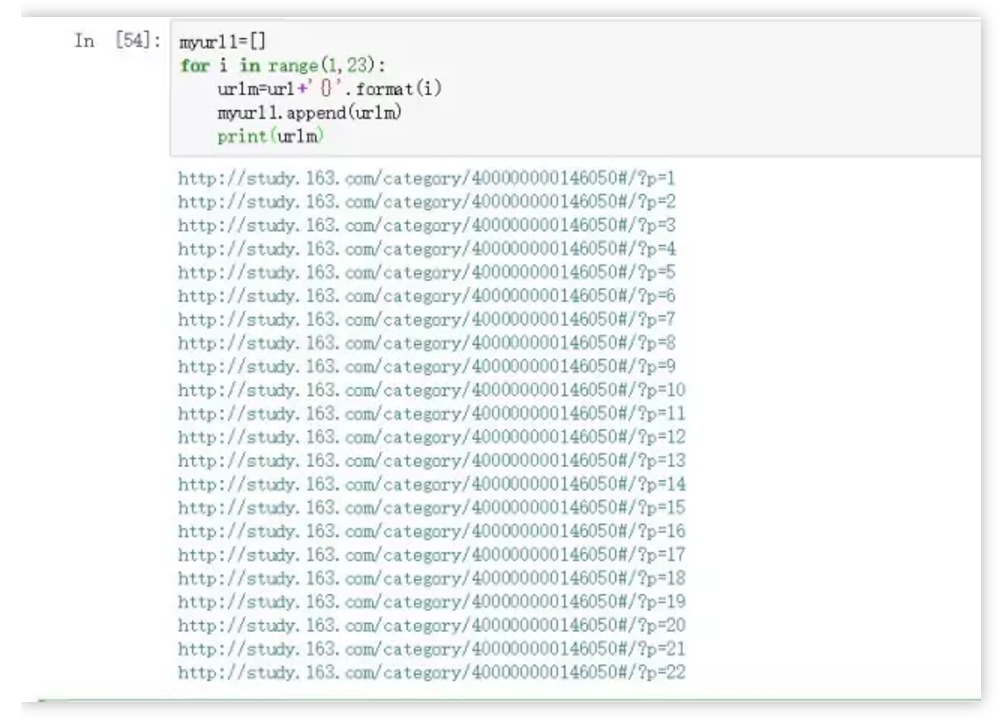
myurl1=[]
for i in range(1,23):
urlm=url+'{}'.format(i)
myurl1.append(urlm)
print(urlm)
好了今天就这样了,要同时贯穿两门语言真的不是一件容易的事情,长路漫漫以后日子要苦逼了。
总结一下:
R语言字符串格式化输出:
paste/paste0
stringr::str_c
sca::percent
scales::percent
sprintf
Python字符串格式化输出:
关于传参的规则:
使用格式化符号可以通过位置参数【比较好用】、命名参数来实现字符串格式化输出【使用字典反而繁琐了】。
使用.format格式化输出可以通过顺序参数(编号顺序)、位置参数(前后位置顺序需一致)、名称参数(比较自由不用考虑顺序)