最近在看任坤大神的新作——《R语言编程指南》,其中对于编程语言中非常流行的面向对象编程范式(OOP)在R语言中的实现进行了非常详尽的讲解,强烈推荐各位有志于进阶R语言编程的小伙伴儿进行阅读。
R语言内目前可以实现OOP范式的一共有四套标准:S3、S4、RC、R6,其中关于S3、S4两种范式在早期的各种扩展包中使用比较多,是基于泛型函数而实现的,之前在学习Python的面向对象编程系列时曾经做过粗浅的练习:
左手用R右手Python系列——面向对象编程基础
S3与S4之间的差异:
1.在定义S3类的时候,没有显式的定义过程,而定义S4类的时候需要调用函数setClass;
2.在初始化S3对象的时候,只是建立了一个list,然后设置其class属性,而初始化S4对象时需要使用函数new;
3.提取变量的符号不同,S3为$,而S4为@;
4.在应用泛型函数时,S3需要定义f.classname,而S4需要使用setMethod函数;
5.在声明泛型函数时,S3使用UseMethod(), 而S4使用setGeneric()。
S3的范式存在很大的隐患,对于类与对象的定义都不够严谨,S4范式在很大程度上弥补了S3的缺陷,但是在实现方式和方法分派上与主流的面向对象语言仍然存在很大的差距,方法分配、类与方法的定义都是割裂独立执行的,在封装上非常不方便,而RC以及在RC基础上进一步发展的R6标准已经逐步开始接近主流编程语言中面向对象的实现模式。
RC 是一种具有引用语义的类系统,它更像其他面向对象编程语言中的类系统。
它将所有的类属性及对应方法都封装在一个实例生成器中,通过生成器可以生成需要的实例,进而执行对应的类方法。在方法中修改字段的值,需要用<<-。
以下是使用RC引用类实现的一个小爬虫:
#加载扩展包
library("RCurl")
library("XML")
library("magrittr")
首先定义类:
hellobi <- setRefClass(
"hellobi",
fields = list(
i = "numeric",
fullinfo = "data.frame",
headers = "character"
),
methods = list(
GetData = function() {
d <- debugGatherer()
handle <- getCurlHandle(debugfunction=d$update,followlocation=TRUE,cookiefile="",verbose = TRUE)
while (i < 10){
i <<- i + 1
url <- sprintf("https://www.hellobi.com/jobs/search?page=%d",i)
tryCatch({
content <- getURL(url,.opts=list(httpheader=headers),.encoding="utf-8",curl=handle) %>% htmlParse()
job_item <- content %>% xpathSApply(.,"//div[@class='job_item_middle pull-left']/h4/a",xmlValue)
job_links <- content %>% xpathSApply(.,"//div[@class='job_item_middle pull-left']/h4/a",xmlGetAttr,"href")
job_info <- content %>% xpathSApply(.,"//div[@class='job_item_middle pull-left']/h5",xmlValue,trim = TRUE)
job_salary <- content %>% xpathSApply(.,"//div[@class='job_item-right pull-right']/h4",xmlValue,trim = TRUE)
job_origin <- content %>% xpathSApply(.,"//div[@class='job_item-right pull-right']/h5",xmlValue,trim = TRUE)
myreslut <- data.frame(job_item,job_links,job_info,job_salary,job_origin,stringsAsFactors = FALSE)
fullinfo <<- rbind(fullinfo,myreslut)
cat(sprintf("第【%d】页已抓取完毕!",i),sep = "\n")
},error = function(e){
cat(sprintf("第【%d】页抓取失败!",i),sep = "\n")
})
Sys.sleep(runif(1))
}
cat("all page is OK!!!")
return (fullinfo)
}
)
)
创建一个类实例:
mydata <- hellobi(
i = 0,
fullinfo = data.frame(),
headers = c(
Referer = "https://www.hellobi.com/jobs/search",
`User-Agent` = "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.79 Safari/537.36"
)
)
调用类中对应的方法执行爬虫程序:
mydatainfo <- mydata$GetData()
预览数据:
DT::datatable(mydatainfo)

R6是基于RC引用类系统的进一步升级版,它明确的的将类内所有的属性(字段)和方法进行了共有和私有的区分,这样可以控制那些对象对于用户是可见的,那些是不可见的,增加程序的安全性,并尽可能使得可见部分简洁明了,易于理解。
library("R6")
#R6不是内置包,是一个第三方扩展包,因此在使用R6系统前需要提前加载该包
创建R6对象:
hellobi <- R6Class(
"hellobi",
public = list(
i = NA,
fullinfo = NA,
headers = NA,
#初始化函数
initialize = function(i,fullinfo,headers) {
#以下主要是进行参数检查并进行分配初始化参数
if (!missing(i)) self$i <- i
if (!missing(fullinfo)) self$fullinfo <- fullinfo
if (!missing(headers)) self$headers <- headers
},
#方法调用(这里我将爬虫程序定义在私有域内,然后在公有域内进行引用)
GetData = function() {
private$Crawler()
}
),
#定义私有域(这里私有域主要定义爬虫程序)
private = list(
Crawler = function(){
d <- debugGatherer()
handle <- getCurlHandle(debugfunction=d$update,followlocation=TRUE,cookiefile="",verbose = TRUE)
while (self$i < 10){
self$i <<- self$i + 1
url <- sprintf("https://www.hellobi.com/jobs/search?page=%d",self$i)
tryCatch({
content <- getURL(url,.opts=list(httpheader=self$headers),.encoding="utf-8",curl=handle) %>% htmlParse()
job_item <- content %>% xpathSApply(.,"//div[@class='job_item_middle pull-left']/h4/a",xmlValue)
job_links <- content %>% xpathSApply(.,"//div[@class='job_item_middle pull-left']/h4/a",xmlGetAttr,"href")
job_info <- content %>% xpathSApply(.,"//div[@class='job_item_middle pull-left']/h5",xmlValue,trim = TRUE)
job_salary <- content %>% xpathSApply(.,"//div[@class='job_item-right pull-right']/h4",xmlValue,trim = TRUE)
job_origin <- content %>% xpathSApply(.,"//div[@class='job_item-right pull-right']/h5",xmlValue,trim = TRUE)
myreslut <- data.frame(job_item,job_links,job_info,job_salary,job_origin,stringsAsFactors = FALSE)
self$fullinfo <<- rbind(self$fullinfo,myreslut)
cat(sprintf("第【%d】页已抓取完毕!",self$i),sep = "\n")
},error = function(e){
cat(sprintf("第【%d】页抓取失败!",self$i),sep = "\n")
})
Sys.sleep(runif(1))
}
cat("all page is OK!!!")
return (self$fullinfo)
}
)
)
创建类实例:
mydata <- hellobi$new(
i =0,
fullinfo = data.frame(),
headers = c(
Referer = "https://www.hellobi.com/jobs/search",
`User-Agent` = "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.79 Safari/537.36"
)
)
调用类中的方法执行爬虫程序:
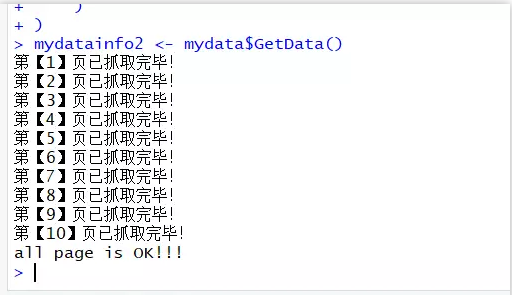
mydatainfo2 <- mydata$GetData()
关于面向对象的一些高级特性——继承、多态等属性,有待以后有更深理解之后再做分享,因为自己理解的不够深刻,今天也是抱着试一试的心态尝试着熟练二者的区别,如果各位对此有更加精辟的理解,欢迎交流分享。